FPGA开发全攻略——综合
原文链接:
FPGA开发全攻略连载之十二:FPGA实战开发技巧(8)(原文缺失,转自:FPGA开发全攻略—工程师创新设计宝典)
5.3.4 综合高手揭秘XST的11个技巧
作者:Ricky Su(www.rickysu.com)
技巧1、XST 主要参考资料:XST User Guide (ISE 安装目录doc 中的xst.pdf)
技巧2、 辅助参考资料:WP231 - HDL Coding Practices to Accelerate Design Performance
技巧3、特别注意之一:请给XST 加时序约束。
通常我们会为工程添加UCF 约束指定时序要求和管脚约束。但是UCF 约束是给MAP,PAR 等实现使用的,综合工具XST 并不能感知系统的时序要求。而为XST 添加XCF 约束却是使实现结果拥有最高频率的关键。其原因是显而易见的:实现工具只能在综合网表的基础上布局布线,而综合工具却可以根据要求调整综合网表,使实现工具更容易满足时序要求。如果不将时序目标告知综合器,将导致我们对性能的要求得不到体现。
XCF约束语法与UCF 类似并且在XST User Guide 中有详细描述。其实常用的Period、Offest等约束和UCF的语法是一模一样的,可以直接使用在XCF中。
给设计添加XCF 约束的方法是Synthesize - XST --> 右键 --> Synthesis Constraint File = 指定路径
技巧4、特别注意之二:仔细察看综合报告中的Warning。切记要仔细查看综合报告中的所有Warning并确认是否是可以安全忽略的。综合器产生Error会使工具停止工作,但是Warning 经常会被用户忽略。其实Waning可以提示很多潜在的逻辑问题,比如某些信号声明了,被使用了,却没有被赋值,或者综合器发现了Latch但却不是期望的结果等等。
技巧5、 常用选项之一:keep_hierarchy - 保持层次。在初始设计/debug 的时候很有用。XST根据层次来综合,不打破层次优化,所有的寄存器名字都以名字排列,UCF 约束可以很方便得找到需要约束的对象。如果选择soft,则在综合时保持层次,而在map 时工具会打破层次来优化,但是instance 的名字还是保留的。
技巧6、常用选项之二:register_duplication + max_fanout + equivalent_register_removal + resource_sharing - 允许自动复制寄存器,设置最大扇出,禁止资源共享。当Timing不满足时使用复制寄存器的方法通常能改善一些瓶颈。综合器为了节省面积而做出的某些优化可能导致对时序不利,因此关闭equivalent_register_removal 和resource_sharing可能可以改善时序。
技巧7、常用选项之三:Add IO Buffers - 自动插入缓冲器。当我们的设计作为顶层使用时,通常让工具自动插入IO buffer ;当需要将设计作为模块插入别的设计中时,就需要禁止自动插入IO Buffer。
技巧8、常用选项之四: Number of Clock Buffers 和 buffer_type 约束: 当综合结果中的BUFG 不是像想象中一样时,我们可以通过下面两种方法来解决:
- 用buffer_type 约束对该信号所使用的Buffer类型定义。具体使用方法在XST User Guide
- 手动插入BUFG,然后设置允许使用BUFG的数量,那么手动插入的将拥有高优先级而先占用了BUFG,工具就不会再自动插BUFG 了。
技巧9、 BlackBox :调用其它已经综合好的网表需要使用BlackBox。BlackBox说白了就是只有端口说明的HDL文件。更多的BlackBox Tip请参考我的博客( 注:为RickySu 的博客)。
技巧10、XST的命令行模式:XST支持使用命令行模式进行批量操作。
命令行的XST 支持两种模式:
Shell 方式 - 在cmd下输入xst,然后在xst的shell 环境中一条一条打命令;
Script 方式 - 在cmd下用xst -ifn script.scr运行script.scr 内的命令,或者在xst shell 中用script命令调用script.scr中的内容。在此之前,会需要先准备好compile_list.prj。EDK 其实就使用这种方法调用XST。更详细的语法参考XST User Guide。
技巧11、要查看综合后的网表,除了XST自带的RTL Schematic工具和Technology Schematic工具,还可以使用PlanAhead。他的显示/ 查找能力更为强大,而且他会先合并所有的综合网表,不会因为某个模块式预先综合好的而不能察看内部状况。
5.4 大规模设计带来的综合和布线问题
FPGA 设计的时序性能是由物理器件、用户代码设计以及 EDA 软件共同决定的,忽略了任何一方面的因素,都会对时序性能有很大的影响。本节主要给出大规模设计中,赛灵思物理器件和 EDA 软件的最优使用方案。
1)IO 约束技巧
优秀设计必须要考虑 IO 约束的技巧。对于赛灵思器件来讲,进位链是垂直分布的、逻辑排列块之间也有水平方向上三态缓冲线的直接连接、且硬核单元基本都是按列分布 ( 在水平方向就具备最短路径 ),因此最优的方案为 :将用于控制信号的 I/O 置于器件的顶部或底部,且垂直布置 ;数据总线的 I/O 置于器件的左部和右部,且水平布置,如图 5-16 所示。
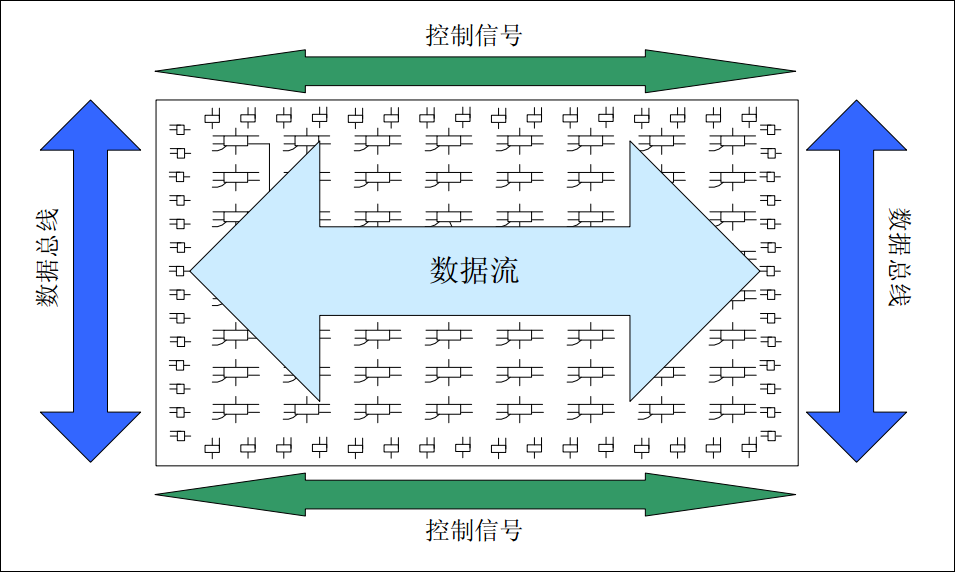
图5-16 赛灵思器件的最佳IO布局示意图
这种IO 分配方式充分利用了Xilinx FPGA 芯片架构的特点,如进位链排列方式以及块RAM、硬核乘法器位置。进位链的结构如图 5-17 所示。能解决多位宽加法、乘法从最低位向最高位的进位延时问题 ;块 RAM 和硬核乘法器可节约大量的逻辑资源且保证时序,二者在 FPGA 芯片中都是自上而下成条状分布,因此数据流水平、控制流垂直可最大限度地利用芯片底层架构。当然,在实际系统设计中,可能无法完全做到上述要求,但还是应该尽可能地将高速率、多位宽的信号布置在芯片左右两侧。
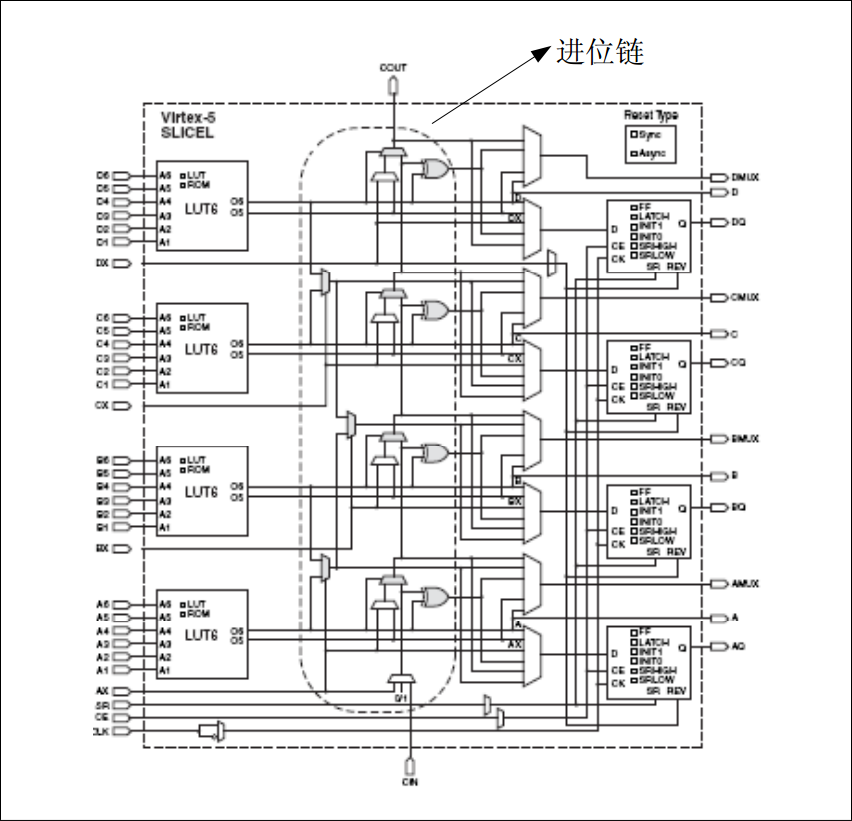
图5-17 赛灵思器件的进位链结构示意图
2)ISE 的实现工具
ISE 中集成的实现工具具备不同的努力程度 (Effort Level),当然使用最高级别的,可以提高时序性能,而不必采取其它措施 ( 如施加更高级的时序约束,使用高级工具或者更改代码等 ),但需要花费很长的计算时间。为此,赛灵思推荐的最佳流程如图 5-18 所示。
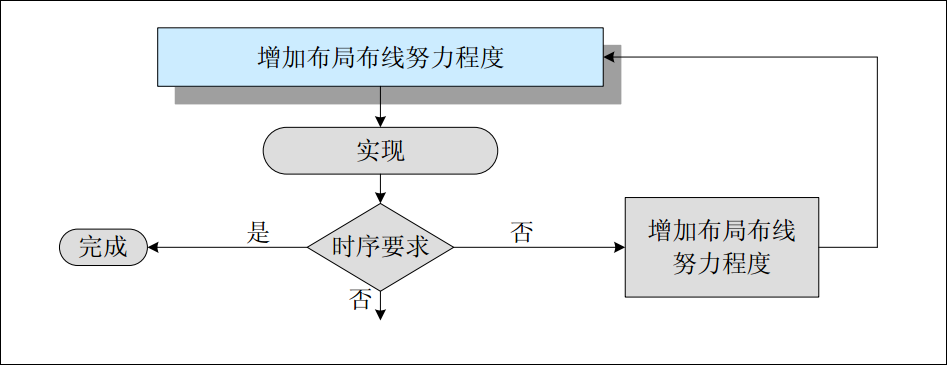
图5-18 赛灵思实现工具的最佳使用策略
在第一遍实现时,使用全局时序约束和缺省的实现参数选项,如果不能满足时序要求,则可尝试以下方法:
(1) 尝试修改代码,如使用合适的代码风格,增加流水线等 ;
(2) 修改综合参数选项,如 Optimization Effort,Use Synthesis Constraints File,Keep Hierarchy,Register Duplication,Register Balancing 等 ;
(3) 增加实现工具的努力程度 ;
(4) 在综合和实现时采用指定路径时序约束的方法。
实现工具分为映射 (MAP) 和布局布线 (PAR) 两部分,和 PAR 一样,也可使用 Map-timing 参数选项针对关键路径进行约束。如 :参数“Timing-Driven Packing and Placement”给关键路径以优先时序约束的权利 ;用户约束通过翻译 (Translate) 过程从 User Constraints File (UCF ) 中传递到设计中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号