
survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载。
生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系。例如研究病人感染了病毒后,多长时间会死亡;工作的机器多长时间会发生崩溃等。 这里“个体的存活”可以推广抽象成某些关注的事件。 所以SA就成了研究某一事件与它的发生时间的联系的方法。这个方法广泛的用在医学、生物学等学科上,近年来也越来越多人用在互联网数据挖掘中,例如用survival analysis去预测信息在社交网络的传播程度,或者去预测用户流失的概率。 R里面有很成熟的SA工具。 本文介绍生存分析的基本概念和一些公式,以及R语言应用示例。
相比于logistics regression, survival analysis有个很大的优点是可以处理缺失数据(censored data, 只有个体的部分数据)。比如说医生想研究病人在服药后的健康状况,跟踪期为2015一整年。有些人接近2015年底才开始服药,那么他就只有很短的数据。如果在一年内知道病人死亡了,那么这个病人的数据是完全的;而健康的病人的数据到2015年末就是缺失的了(right censored),因为假如病人在一年后死亡了,我们并不知道这个事。或者说病人在一年内突然失联了,那么他的数据也是缺失。

用T表示事件的发生时刻
存活函数 :
S(t)= Pr(T>t) = 1-F(t)
表示个体在t时刻还活着的概率,即事件在t时刻还未发生的概率。S(0)=1, S(无穷大) = 0, 并且S(t)是单调非增函数。实际数据中,t通常取离散值,例如天,周等。
风险函数:

(2) 模型
2.1 如果每个个体都遵循相同的规律,即个体间没有差异,那么问题比较简单。Kaplan-Meier是一种无参数的模型,它在每个兴趣时间点做一次存活统计,估计存活函数. 令 表示第i时刻还存活的个体数, 表示第i时刻发生事件的个体数量,那么:
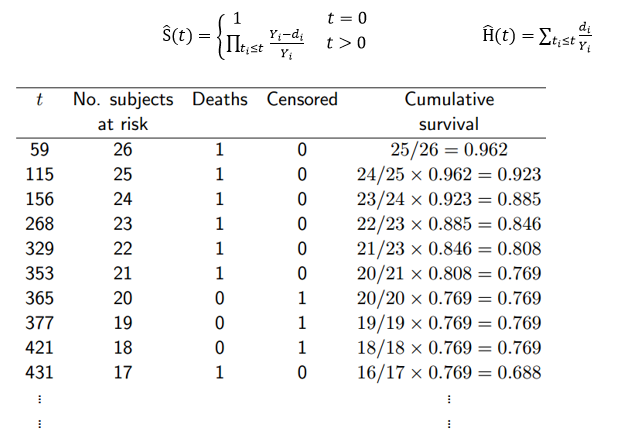
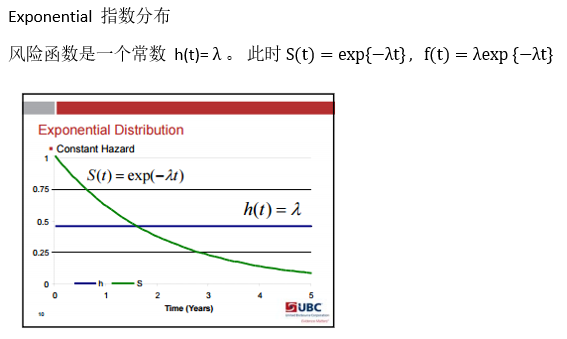
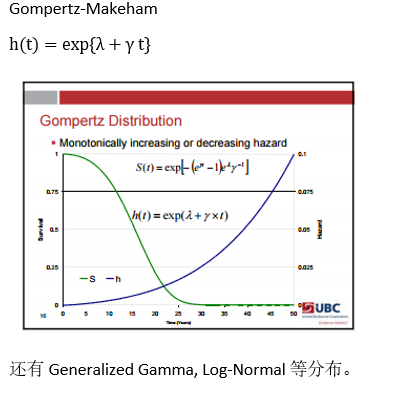
这种方法学出来的S(t)是不平滑的。 带参数的模型会假设模型服从某个分布,使学得的函数平滑。常用的有:

install.packages("OIsurv") library(OIsurv) data(tongue) attach(tongue) my.surv<-Surv(time[type==1], delta[type==1]) my.fit<-survfit(my.surv~1) #Kaplan-Meier summary(my.fit) plot(my.fit) #比较type=1和type=2这两个组的存活函数 my.fit1<-survfit(Surv(time,delta)~type) plot(my.fit1) #计算风险函数 H.hat<--log(my.fit$surv) H.hat<-c(H.hat, tail(H.hat,1)) print(my.fit, print.rmean=TRUE) #检验两个存活函数是否有区别 survdiff(Surv(time, delta) ~ type) # output omitted detach(tongue)
2.2 Cox proportional hazards model

# cox PH model data(burn) attach(burn) my.surv <- Surv(T1, D1) coxph.fit <- coxph(my.surv ~ Z1 + as.factor(Z11), method="breslow") detach(burn)
预测新数据的值感觉比较不正规,因为survival analysis本身不是针对预测的:
risk = function(model, newdata, time) {
as.numeric(1-summary(survfit(model, newdata = newdata, se.fit = F, conf.int = F), times = time)$surv)
}2.3 extended Cox model
如果Cox PH Model中的变量会随时间变化,那么就成了extended Cox model,此时HR不再是一个常量。很简单的例子,如果病人的居住地也是一个变量,病人有可能会搬家,例如在北京吸霾了5年,再跑去厦门生活,那么他旧病复发的概率肯定会降低。所以住所这个变量是和时间相关的。一种简单的做法是,按照变量改变的时刻,把时间切割成区间,使得每个区间内的变量没有变化。然后再套用Cox PH模型。
# extended cox data(relapse) N <- dim(relapse)[1] t1 <- rep(0, N+sum(!is.na(relapse$int))) # initialize start time at 0 t2 <- rep(-1, length(t1)) # build vector for end times d <- rep(-1, length(t1)) # whether event was censored g <- rep(-1, length(t1)) # gender covariate i <- rep(FALSE, length(t1)) # initialize intervention at FALSE j <- 1 for(ii in 1:dim(relapse)[1]){ if(is.na(relapse$int[ii])){ # no intervention, copy survival record t2[j] <- relapse$event[ii] d[j] <- relapse$delta[ii] g[j] <- relapse$gender[ii] j <- j+1 } else { # intervention, split records g[j+0:1] <- relapse$gender[ii] # gender is same for each time d[j] <- 0 # no relapse observed pre-intervention d[j+1] <- relapse$delta[ii] # relapse occur post-intervention? i[j+1] <- TRUE # intervention covariate, post-intervention t2[j] <- relapse$int[ii]-1 # end of pre-intervention t1[j+1] <- relapse$int[ii]-1 # start of post-intervention t2[j+1] <- relapse$event[ii] # end of post-intervention j <- j+2 # two records added } } mySurv <- Surv(t1, t2, d) # pg 3 discusses left-trunc. right-cens. data myCPH <- coxph(mySurv ~ g + i)
参考文献:
http://www.stat.columbia.edu/~madigan/W2025/notes/survival.pdf
http://www.openintro.org/stat/down/Survival-Analysis-in-R.pdf
http://www.ispor.org/congresses/Spain1111/presentations/W29_Ishak-Jack.pdf
http://data.princeton.edu/pop509/ParametricSurvival.pdf
posted on 2016-03-16 22:17 leavingseason 阅读(39726) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号