Self Organizing Maps (SOM): 一种基于神经网络的聚类算法
自组织映射神经网络, 即Self Organizing Maps (SOM), 可以对数据进行无监督学习聚类。它的思想很简单,本质上是一种只有输入层--隐藏层的神经网络。隐藏层中的一个节点代表一个需要聚成的类。训练时采用“竞争学习”的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫“winning neuron”。 紧接着用随机梯度下降法更新激活节点的参数。同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
所以,SOM的一个特点是,隐藏层的节点是有拓扑关系的。这个拓扑关系需要我们确定,如果想要一维的模型,那么隐藏节点依次连成一条线;如果想要二维的拓扑关系,那么就行成一个平面,如下图所示(也叫Kohonen Network):
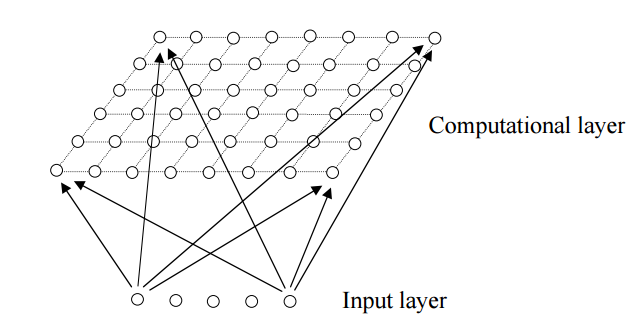
既然隐藏层是有拓扑关系的,所以我们也可以说,SOM可以把任意维度的输入离散化到一维或者二维(更高维度的不常见)的离散空间上。 Computation layer里面的节点与Input layer的节点是全连接的。
拓扑关系确定后,开始计算过程,大体分成几个部分:
1) 初始化:每个节点随机初始化自己的参数。每个节点的参数个数与Input的维度相同。
2)对于每一个输入数据,找到与它最相配的节点。假设输入时D维的, 即 X={x_i, i=1,...,D},那么判别函数可以为欧几里得距离:

3) 找到激活节点I(x)之后,我们也希望更新和它临近的节点。令S_ij表示节点i和j之间的距离,对于I(x)临近的节点,分配给它们一个更新权重:

简单地说,临近的节点根据距离的远近,更新程度要打折扣。
4)接着就是更新节点的参数了。按照梯度下降法更新:

迭代,直到收敛。
与K-Means的比较
同样是无监督的聚类方法,SOM与K-Means有什么不同呢?
(1)K-Means需要事先定下类的个数,也就是K的值。 SOM则不用,隐藏层中的某些节点可以没有任何输入数据属于它。所以,K-Means受初始化的影响要比较大。
(2)K-means为每个输入数据找到一个最相似的类后,只更新这个类的参数。SOM则会更新临近的节点。所以K-mean受noise data的影响比较大,SOM的准确性可能会比k-means低(因为也更新了临近节点)。
(3) SOM的可视化比较好。优雅的拓扑关系图 。
参考文献:http://www.cs.bham.ac.uk/~jxb/NN/l16.pdf
posted on 2016-01-09 19:20 leavingseason 阅读(68629) 评论(3) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号