李宏毅2021春机器学习课程笔记——Convolutional Neural Network
本文作为自己学习李宏毅老师2021春机器学习课程所做笔记,记录自己身为入门阶段小白的学习理解,如果错漏、建议,还请各位博友不吝指教,感谢!!
CNN理解角度一
图像的表达形式
对于一个Machine来说,一张输入的图像其实是一个三维的Tensor。

如上图所示,三个维度分别表示图像的宽、高和Channel的数目。彩色图像的每一个pixel都是由RGB 三个颜色所组成的,所以3个Channel就分别代表了RGB三个颜色,宽和高表示了这张图像中像素的数目(即:100×100)
之前提到的网络(例:Fully Connected Network)的输入都是一个向量,那如何将一张有三个维度的图像数据输入到网络中呢?一个直接的方法就是将这个三维的Tensor拉直成一个向量,如下图所示:

图中拉直后的向量的长度为100×100×3,其中每一维里存的数值表示某一个pixel在某个颜色上的强度。如果我们使用Fully Connected Network来实现我们的目标,假设这个Network的第一个隐藏层中有1000个Neuron。我们将上图中的向量输入到这个网络,那么第一层中就有\(3 \times 10^7\)个参数,如下图所示:
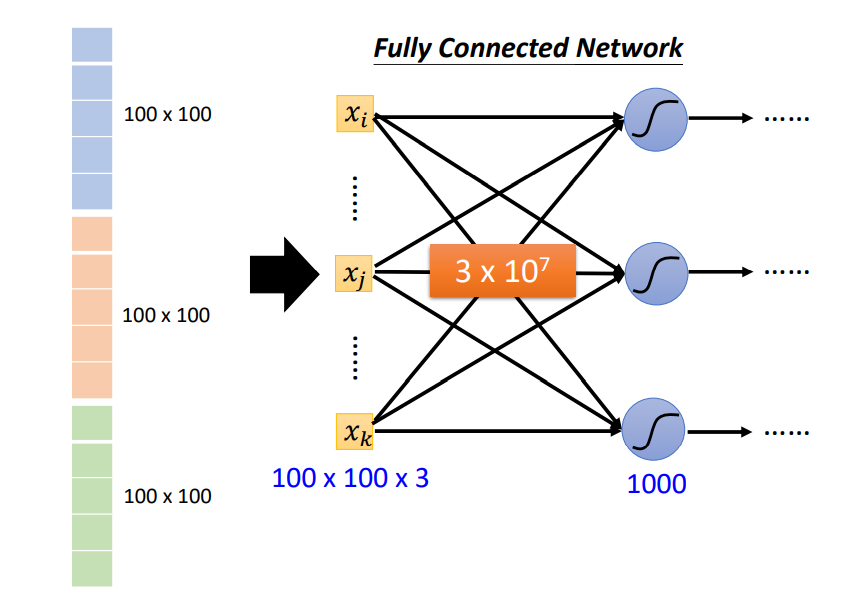
随着网络层数增多,参数也增多,网络的弹性增强,也就更容易出现过拟合(Overfitting)问题,而且训练的效率也会变低。所以,如何减少网络的参数是我们使用图像数据训练模型要解决的一个问题。除了上述参数太多的问题,在使用Fully Collected Network处理图像信息时,也会有无法提取图像的局部不变性特征的问题。
局部不变性特征:自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息。而全连接前馈网络很难提取这些局部不变形特征,一般需要进行数据增强来提高性能。
所以Fully Collected Network并不适合直接拿来处理图像信息,需要做进一步的简化。我们可以先考虑用于影像辨识的类神经网络是如何对一张图片中的动物进行分类的。

假设如上图所示,用于图像分类的类神经网络是通过综合检测到的一些重要的patterns,来进行分类的,例如:
- 某个神经元看到了鸟嘴的pattern。
- 某个神经元看到了鸟的眼睛的pattern。
- 某个神经元看到了鸟爪的pattern。
类神经网络综合检测到的这些patterns,最后得出结论,图像中的生物是一只鸟。这样的话,就没必要将一整张图像作为类神经网络中每个神经元的输入。只需要将图像中的一小部分输入到神经元中,就可以检测到某些重要的patterns。
感受野(Receptive Field)
对于上边提到的以检测patterns的方式来处理图像信息的方法,在CNN中设置有感受野(Receptive Field),并由一组神经元来处理这个感受野提取的图像信息。一般来说,感受野是要考虑所有Channels上的信息的。这样在描述感受野时,只要说明它的宽×高(即Kernel Size)就可以了。
在影像辨识中Kernel Size一般设为3×3,比较大的Kernel Size一般为7×7或者9×9。
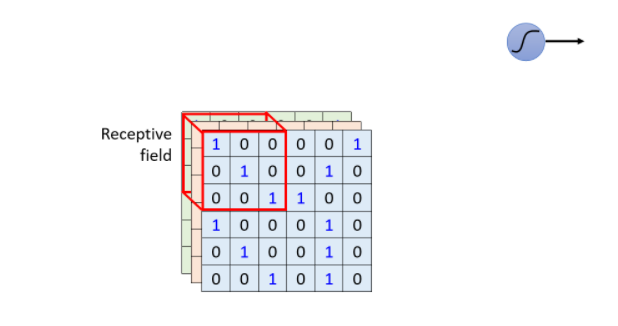
如上图所示,以一个蓝色的神经元负责处理左上角感受野中的图像信息为例。而这个神经元要完成的工作就是:
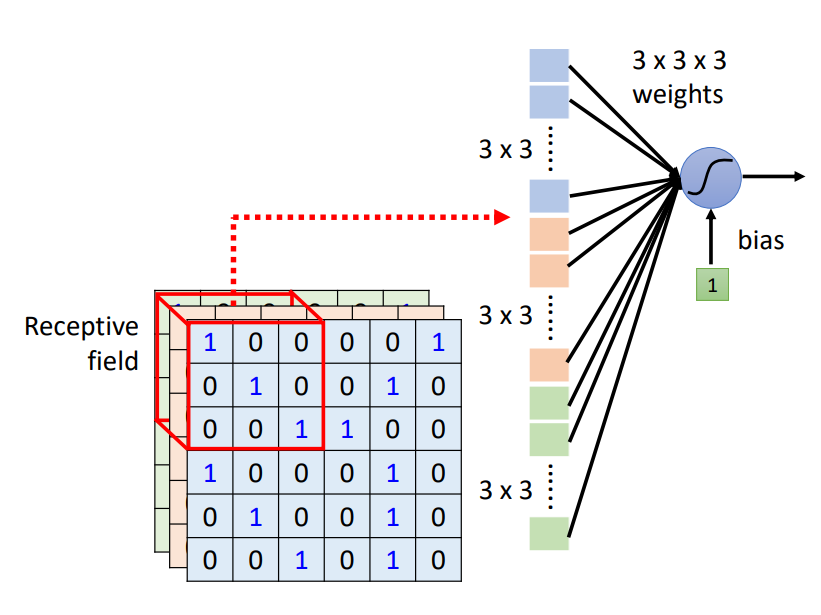
- 将感受野中\(3 \times 3 \times 3\)的数值拉直,变成一个27维的向量,作为蓝色神经元的输入。
- 这个神经元会给向量中每一个Dimension一个Weight,所以有27个参数。
- 再加上Bias得到输出,作为下一层神经元的输入。
将上图中的Receptive Field向右移动一格,就获得了另一个Receptive Field,这个移动的量称为Stride。Stride是一个由我们自己设置的超参数(Hyper parameter),一般设为1或2。这样我们就可以从左到右,从上到下移动来获取不同的Receptive Field,如下图所示:
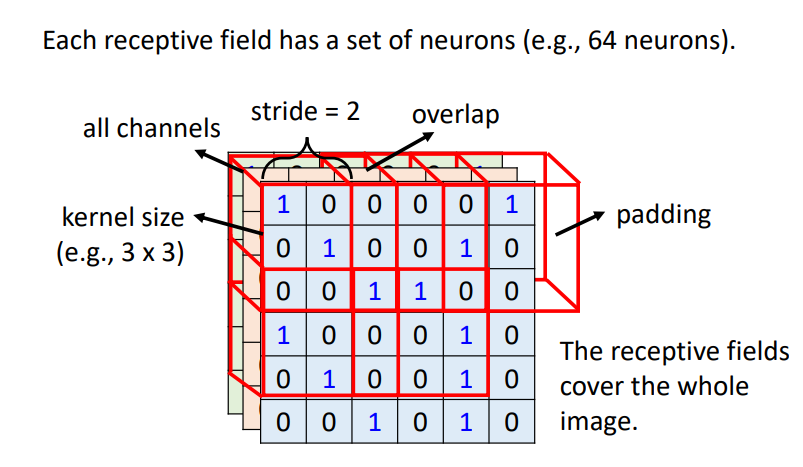
当Receptive Field从左向右移动超出图像Tensor的边界时,我们可以用0进行填充(padding)。当然,也可以使用整张图像中所有值的平均值或者边界上的数值来做padding。
权值共享
虽然,感受野对用于图像处理的网络做了初步的简化,仍会有让网络的参数变得非常多的情况。
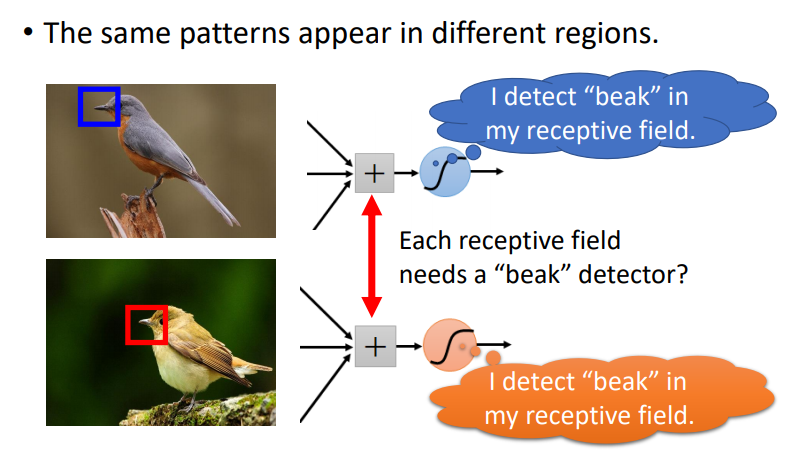
如上图所示,当表示鸟嘴的pattern出现在图像的不同区域时,按照上边的设置感受野的方法,我们可以在每个位置都放一个检测鸟嘴pattern的感受野来进行处理。这些不同位置上检测鸟嘴pattern的感受野,都做着同样的工作,这不仅造成了冗余,而且随着要处理的patterns的数量增多,网络的参数量也会变得非常的大。
对于这个问题,我们可以通过让负责不同感受野(Receptive Field)的神经元共享权值来解决。

如上图所示,在两个神经元与输入数据的连接中,两个颜色相同的连接所代表的参数weight是一样的。这样,两个神经元虽然负责处理不同位置上的感受野,但是参数是一样的,即都处理同样的pattern。
在上边提到过,一个感受野提取的信息,其实是由一组神经元来进行处理的。那这些神经元是怎么共享权值的呢?
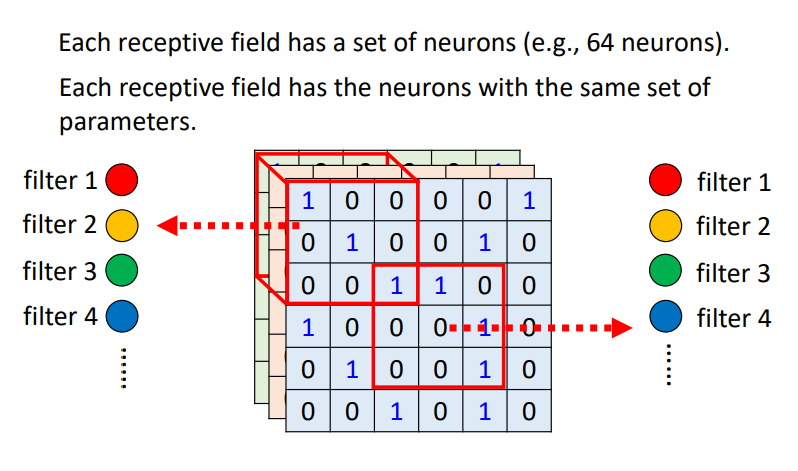
两组神经元之间的共享权值可以如上图所示理解,即颜色相同的两个神经元的参数是一样的,而这些参数被称作Filter。这里个人理解,每种颜色的神经元负责处理一种pattern,即一个Filter负责提取一个特征。
以上就是李宏毅老师从根据图像的特性,对网络进行简化的角度来解释的CNN。
CNN理解角度二
以下是李宏毅老师从Filter的角度来理解CNN网络。

如上图所示,在Convolution Layer中含有一排Filter,每一个Filter是一个3×3×channel的Tensor(Tensor中存储着Filter所对应的参数值,也就是Model中的Parameter,具体的Parameter的值是需要通过gradient decent来得到的),其作用就是要提取图像中的某一个pattern。以一张黑白色的图像(即图像的信息中Tensor的Channel=1),并假设Filter中存储的参数都已知。表示Filter提取图像中pattern的过程:
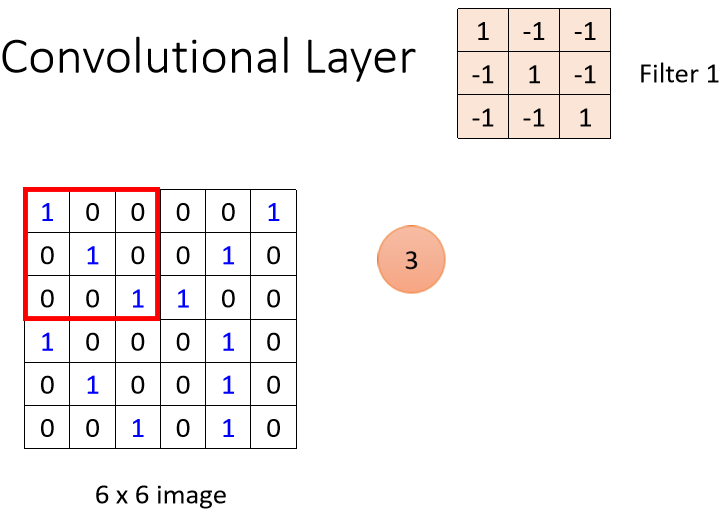
我们将第一个Filter中的参数,与左上角中的数值做内积运算得出一个值,注意这里的内积计算方式如下所示:
设Filter的移动距离(Stride)为1,使其从左到右,从上到下移动,计算出经过所有位置的值来,如下图所示:
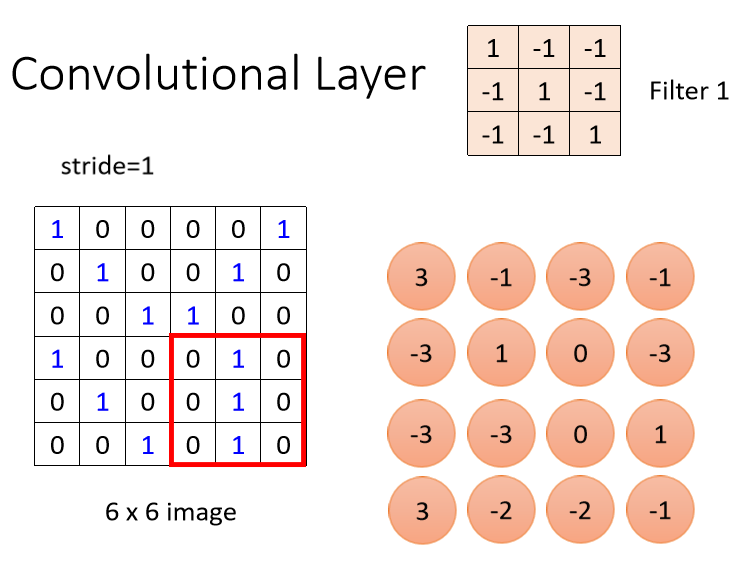
那Filter提取它所对应pattern是怎么体现出来的呢?
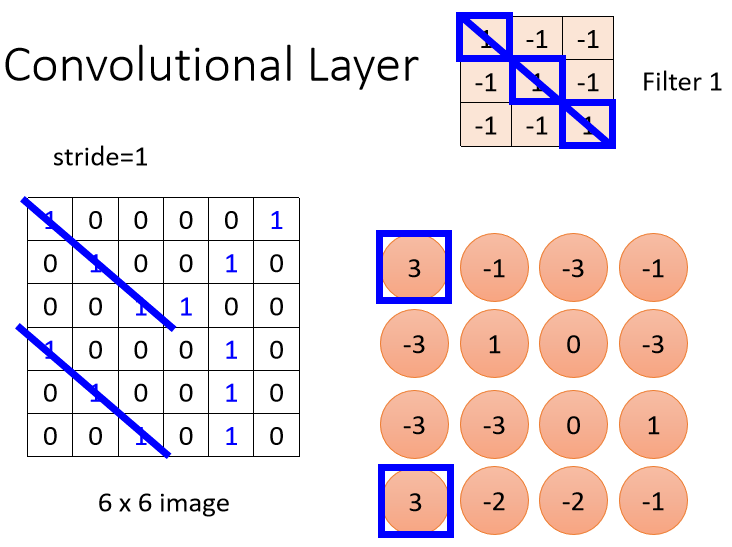
如上图所示,Filter 1检测的是对角线为1的这种pattern。当它遇到这种对角线为1的pattern时,计算出的值在Tensor中是最大的,所以可以看到两个蓝色框框出来的最大值3。假设Convolutional Layer中有64个Filter,当所有的Filter都完成内积计算后,最终会得到一个channel=64的Tensor,称为Feature Map,也可以理解为另一张新的图像,这个Feature Map将输入到后续的网络中进一步处理:

Pooling
汇聚层(Pooling Layer)也叫子采样层(Subsampling Layer),其作用是进行特征选择,降低特征数量,从而减少参数数量。
卷积层虽然可以显著的减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维度依然很高,很容易过拟合。可以在卷积层之后加上一个汇聚层,从而降低特征维数,避免过拟合。
具体的做法:假设汇聚层的输入特征映射组为\(\mathcal{X} \in \mathbb{R}^{M \times N \times D}\),对于其中每一个特征映射\(X^d \in \mathbb{R}^{M \times N}, 1 \le d \le D\),将其划分为很多区域\(R_{m,n}^d\),\(1 \le m \le M'\),\(1 \le n \le N'\),这些区域可以重叠,也可以不重叠。汇聚(Pooling)是指对每个区域进行下采样(Down Sampling)得到一个值,作为这个区域的概括。
常见的汇聚函数有两种:
- 最大汇聚(Maximum Pooling或Max Pooling):对于一个区域\(R^d_{m,n}\),选择这个区域内所有神经元的最大活性值作为这个区域的表示,即
其中\(x_i\)为区域\(R_k^d\)内每个神经元的活性值。
- 平均汇聚(Mean Pooling):一般是取区域内所有神经元活性值的平均值,即
以Max Pooling为例:

如上图所示,我们首先将4×4的Tensor划分为4个2×2的小区域,每个区域中取最大值作为代表,组成最终的2×2的汇聚结果,如下图所示:

Pooling操作,本身是没有参数的,所以它不是一个Layer,里边也没有要学习的weight。通常来说Convolution和Pooling是交替使用的,也就是做几次Convolution后,接着做一次Pooling。因为Pooling可以把图像减小,所以它可以起到减少网络参数量的作用。另外,因为Pooling是会损失一些信息,所以我们在处理细微图像信息的网络中使用Pooling,是会对网络的性能造成影响的。
参考资料:
《神经网络与深度学习》 邱锡鹏
https://github.com/unclestrong/DeepLearning_LHY21_Notes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号