火力全开,优化 python 量化日行情数据下载以及常用指标计算速度
火力全开,优化 python 量化日行情数据下载以及常用指标计算速度
今天做了个异步协程的测试,结果有点失望,多进程 + 协程并没有提高 io 密集型任务请求的效率。至于为什么,原因暂时没找到,怀疑是协程的事件循环耗了时,或者是任务并没有构造出真正可等待对象。有知道的网络大神能否提下专业意见。
不过重构了日行情下载速度和常用指标计算速度,还是大大减少了时间的花销。日行情数据 5000 个股票,更新时间段是 2015-01-01 到 2022-12-02 ,从下载到完全插入到数据库大概 6 分钟左右。在这个 7 年的时间段内,常用指标计算并保存到数据库,即均线指标以及个股振幅指标 5、10、20、50、120、250,大概花费 2.5分钟左右。
为日后扩展其他指标打下基础,更新一次估计能控制在 10 分钟以内。
测试 io 密集型任务,cup 密集型任务
下面是测试代码和结果,从结果上看,io 密集型任务多进程的效率和多进程 + 协程的效率是差不多的。对于 cpu 密集型任务来说,多进程明显提高了效率。
可以尝试换事件循环 uvloop ,使用这个事件循环协程效率可提高,但 window 并不支持,所以这个步骤我没测试到。
测试代码:
import asyncio
import os
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, wait
import akshare as ak
import pandas as pd
import config.stockconstant as sc
async def _task_io2():
loop = asyncio.get_event_loop()
future = loop.run_in_executor(None, ak.stock_zh_a_hist, '000001', 'daily', '20150101', '20221202', 'qfq')
response = await future
# print(f"请求回来了 {response.empty}")
async def _read_csw():
return pd.read_csv(sc.config_path)
def _task_io():
pd.read_csv(sc.config_path)
def _task_cpu():
return sum(i * i for i in range(10 ** 5))
async def async_thread_pool(is_io, total, cpu_count):
executor = ThreadPoolExecutor(cpu_count)
loop = asyncio.get_event_loop()
t1 = time.time()
tt = [loop.run_in_executor(executor, _task_io if is_io else _task_cpu) for _ in range(total)]
await asyncio.wait(tt)
print(f'async_thread_pool 耗时:{time.time() - t1} 任务量:{total} {"io 任务" if is_io else "cpu 任务"}')
async def async_process_pool(is_io, total, cpu_count):
executor = ProcessPoolExecutor(cpu_count)
loop = asyncio.get_event_loop()
t1 = time.time()
tt = [loop.run_in_executor(executor, _task_io if is_io else _task_cpu) for _ in range(total)]
await asyncio.wait(tt)
print(f'async_process_pool 耗时:{time.time() - t1} 任务量:{total} {"io 任务" if is_io else "cpu 任务"}')
def thread_pool(is_io, total, cpu_count):
executor = ThreadPoolExecutor(cpu_count)
t1 = time.time()
futures = [executor.submit(_task_io if is_io else _task_cpu) for _ in range(total)]
wait(futures)
print(f'thread_pool 耗时:{time.time() - t1} 任务量:{total} {"io 任务" if is_io else "cpu 任务"}')
def process_pool(is_io, total, cpu_count):
executor = ProcessPoolExecutor(cpu_count)
t1 = time.time()
futures = [executor.submit(_task_io if is_io else _task_cpu) for _ in range(total)]
wait(futures)
print(f'process_pool 耗时:{time.time() - t1} 任务量:{total} {"io 任务" if is_io else "cpu 任务"}')
def main(total, cpu_count):
print(f'cpu:{cpu_count} 个')
asyncio.run(async_thread_pool(True, total, cpu_count))
asyncio.run(async_process_pool(True, total, cpu_count))
thread_pool(True, total, cpu_count)
process_pool(True, total, cpu_count)
print('--------------------------------------')
asyncio.run(async_thread_pool(False, total, cpu_count))
asyncio.run(async_process_pool(False, total, cpu_count))
thread_pool(False, total, cpu_count)
process_pool(False, total, cpu_count)
print('=========================================')
def coroutine(total):
t1 = time.time()
tasks = [asyncio.ensure_future(_task_io2()) for _ in range(total)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(f'coroutine 耗时:{time.time() - t1} 任务量:{total}')
if __name__ == '__main__':
total = 1000
cpu_count = 1
main(total, cpu_count)
total = 10000
main(total, cpu_count)
total = 1000
cpu_count = int(os.cpu_count() / 2)
main(total, cpu_count)
total = 10000
main(total, cpu_count)
cpu_count = int(os.cpu_count())
total = 1000
main(total, cpu_count)
total = 10000
main(total, cpu_count)
# 修改成异步来执行
cpu_count = int(os.cpu_count())
start_time = time.time()
pool = ProcessPoolExecutor()
total = 5000
futures = []
for part in range(cpu_count):
future = pool.submit(coroutine, int(total / cpu_count))
futures.append(future)
pool.shutdown(wait=True)
print(f'5k 次股票请求耗时: {time.time() - start_time}')
结果:
cpu:1 个
async_thread_pool 耗时:8.617908000946045 任务量:1000 io 任务
async_process_pool 耗时:10.806799411773682 任务量:1000 io 任务
thread_pool 耗时:8.566416263580322 任务量:1000 io 任务
process_pool 耗时:10.714466333389282 任务量:1000 io 任务
--------------------------------------
async_thread_pool 耗时:16.213727474212646 任务量:1000 cpu 任务
async_process_pool 耗时:18.297339916229248 任务量:1000 cpu 任务
thread_pool 耗时:16.50342082977295 任务量:1000 cpu 任务
process_pool 耗时:18.00312089920044 任务量:1000 cpu 任务
=========================================
cpu:1 个
async_thread_pool 耗时:92.37166738510132 任务量:10000 io 任务
async_process_pool 耗时:101.25876951217651 任务量:10000 io 任务
thread_pool 耗时:86.62425088882446 任务量:10000 io 任务
process_pool 耗时:93.58890128135681 任务量:10000 io 任务
--------------------------------------
async_thread_pool 耗时:156.15055894851685 任务量:10000 cpu 任务
async_process_pool 耗时:157.71604180335999 任务量:10000 cpu 任务
thread_pool 耗时:154.52726674079895 任务量:10000 cpu 任务
process_pool 耗时:155.301522731781 任务量:10000 cpu 任务
=========================================
cpu:4 个
async_thread_pool 耗时:5.767933368682861 任务量:1000 io 任务
async_process_pool 耗时:4.886445999145508 任务量:1000 io 任务
thread_pool 耗时:5.5500757694244385 任务量:1000 io 任务
process_pool 耗时:4.64022421836853 任务量:1000 io 任务
--------------------------------------
async_thread_pool 耗时:15.328773975372314 任务量:1000 cpu 任务
async_process_pool 耗时:6.7509706020355225 任务量:1000 cpu 任务
thread_pool 耗时:15.10576057434082 任务量:1000 cpu 任务
process_pool 耗时:6.597245454788208 任务量:1000 cpu 任务
=========================================
cpu:4 个
async_thread_pool 耗时:56.77140545845032 任务量:10000 io 任务
async_process_pool 耗时:31.66841983795166 任务量:10000 io 任务
thread_pool 耗时:54.32371783256531 任务量:10000 io 任务
process_pool 耗时:30.22367548942566 任务量:10000 io 任务
--------------------------------------
async_thread_pool 耗时:153.32735443115234 任务量:10000 cpu 任务
async_process_pool 耗时:51.863539695739746 任务量:10000 cpu 任务
thread_pool 耗时:150.73832869529724 任务量:10000 cpu 任务
process_pool 耗时:51.08239006996155 任务量:10000 cpu 任务
=========================================
cpu:8 个
async_thread_pool 耗时:5.868973731994629 任务量:1000 io 任务
async_process_pool 耗时:4.749261856079102 任务量:1000 io 任务
thread_pool 耗时:5.750915765762329 任务量:1000 io 任务
process_pool 耗时:4.7755701541900635 任务量:1000 io 任务
--------------------------------------
async_thread_pool 耗时:15.485109329223633 任务量:1000 cpu 任务
async_process_pool 耗时:6.287221908569336 任务量:1000 cpu 任务
thread_pool 耗时:15.208913326263428 任务量:1000 cpu 任务
process_pool 耗时:6.2330849170684814 任务量:1000 cpu 任务
=========================================
cpu:8 个
async_thread_pool 耗时:58.56171226501465 任务量:10000 io 任务
async_process_pool 耗时:25.237155437469482 任务量:10000 io 任务
thread_pool 耗时:55.95446968078613 任务量:10000 io 任务
process_pool 耗时:24.77057647705078 任务量:10000 io 任务
--------------------------------------
async_thread_pool 耗时:153.94631671905518 任务量:10000 cpu 任务
async_process_pool 耗时:40.62843203544617 任务量:10000 cpu 任务
thread_pool 耗时:151.06180787086487 任务量:10000 cpu 任务
process_pool 耗时:38.96478891372681 任务量:10000 cpu 任务
=========================================
5k 次股票请求耗时: 351.0791549682617
Process finished with exit code 0
优化股票日行情数据请求速度
也没啥好说的,就是把日行情请求抽成任务函数,然后扔到进程池里面执行即可,这里要说下进程间内存并不共享,那么如何保存每个请求的结果呢?需要用 multiprocessing.Manager() 来构建对象,即进程可以共享这些对象。
核心代码如下,结果 5k 个股票请求时间 20150101 - 20221202 时间段,全部请求完毕并保存到数据库,大概 6 分钟左右。用多进程效果也是一致的,注释的代码就是使用多进程的。
def _update_daily_task(self, code, start_time,
end_time, except_code_list,
index, success_code_list):
try:
df = ak.stock_zh_a_hist(
symbol=str(code),
start_date=start_time,
end_date=end_time,
adjust="qfq")
except:
except_code_list.append(code)
print("发生异常code ", code)
return
print('成功获取股票: index->{} {}日行情数据'.format(index, code)
, ' 开始时间: {} 结束时间: {}'.format(start_time, end_time),
f'数据是否为空:{df.empty}')
if df.empty:
success_code_list.append(code)
return
# 获取对应的子列集
sub_df = df[['日期', '开盘', '最高', '最低', '收盘', '成交量', '成交额']]
# net_df 的列名可能和数据库列名不一样,修改列名对应数据库的列名
sub_df.columns = ['date', 'open', 'high', 'low', 'close', 'volume', 'amount']
# 修改 index 为 date 去掉默认的 index 便于直接插入数据库
sub_df.set_index(['date'], inplace=True)
sub_df.insert(sub_df.shape[1], 'code', str(code))
sdb.to_table(sub_df, "stock_daily_price")
success_code_list.append(code)
# print(sub_df)
async def update_daily_multi_io(self):
"""
更新股票日行情数据
东方财富日行情数据,沪深A股,先从本地配置获取股票代码,再获取日行情数据
获取成功或失败,记录到本地数据,以便股票数据更新完整
:return:
"""
last_time = time.time()
with multiprocessing.Manager() as MG:
success_code_list = MG.list()
except_code_list = MG.list()
# 读取配置信息
config_df = self.config.config_df
if config_df.empty:
print('配置信息错误,请检查...')
return
end_time = self.config.update_end_time()
executor = ProcessPoolExecutor()
futures = []
loop = asyncio.get_event_loop()
for index, row in config_df.iterrows():
code = row['code']
start_time = self.config.daily_start_time(code)
if start_time == end_time:
# 已经更新过了
continue
future = loop.run_in_executor(executor, self._update_daily_task,
code, start_time,
end_time, except_code_list,
index, success_code_list)
# future = executor.submit(self._update_daily_task,
# code, start_time,
# end_time, except_code_list,
# index, success_code_list)
futures.append(future)
# wait(futures)
if len(futures) > 0:
await asyncio.wait(futures)
# 更新配置信息
for code in success_code_list:
# 更新配置信息config_df
config_df.loc[config_df['code'] == code, 'daily_update_time'] = end_time
config_df.loc[config_df['code'] == code, 'error_daily_update_count'] = 0
for code in except_code_list:
# 更新配置信息config_df
config_df.loc[config_df['code'] == code, 'error_daily_update_count'] \
= row['error_daily_update_count'] + 1
# 同步配置到本地
self.config.save_config()
# 手动触发去重
sdb.optimize('stock_daily_price')
print('更新本地配置成功...')
print("成功请求的code: ", success_code_list)
print("错误请求code: ", except_code_list)
print(f'日行情更新耗时: {time.time() - last_time}')
结果:
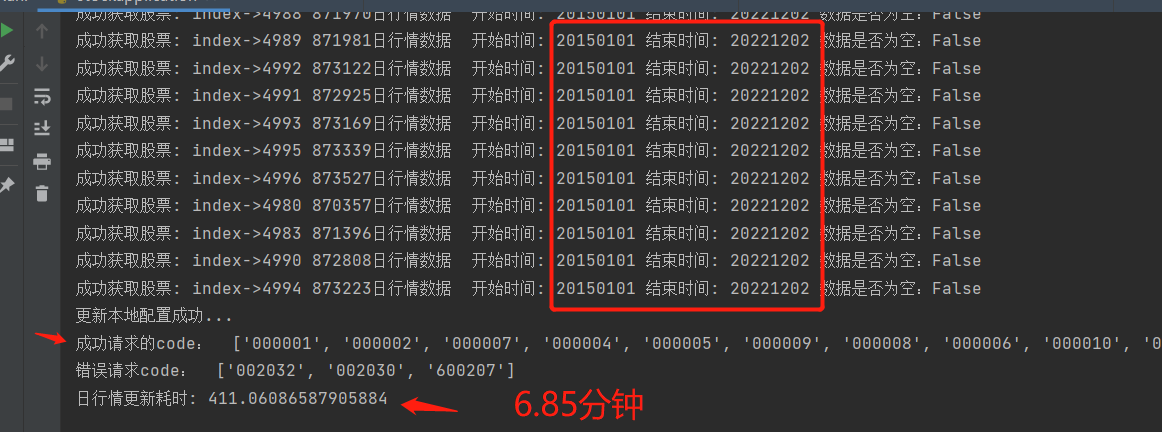
要点分析:
进程间数据共享要通过这样子来创建,这里创建了两个列表,还有其他支持的数据类型,具体的自己查看 api.
with multiprocessing.Manager() as MG:
success_code_list = MG.list()
except_code_list = MG.list()
优化个股常用指标计算速度
计算的指标
指标计算是 cpu 任务密集型,所以用进程池。
本体系建立了一个指标表,这个表只记录个股自身相关的指标,分别是个股自身振幅百分比 amp 以及均线指标 ma,这两个指标包含 5、10、20、50、120、250 日的指标。
分拆任务
根据硬件自身条件 cpu 核数来启动进程池,拆分股票计算池,并分配到不同的进程,计算完毕后把指标更新到数据库。
表结构:
columns = {
'date': 'Date',
'code': 'String',
'amp5': 'Float32',
'amp10': 'Float32',
'amp20': 'Float32',
'amp50': 'Float32',
'amp120': 'Float32',
'amp250': 'Float32',
'ma5': 'Float32',
'ma10': 'Float32',
'ma20': 'Float32',
'ma50': 'Float32',
'ma120': 'Float32',
'ma250': 'Float32'
}
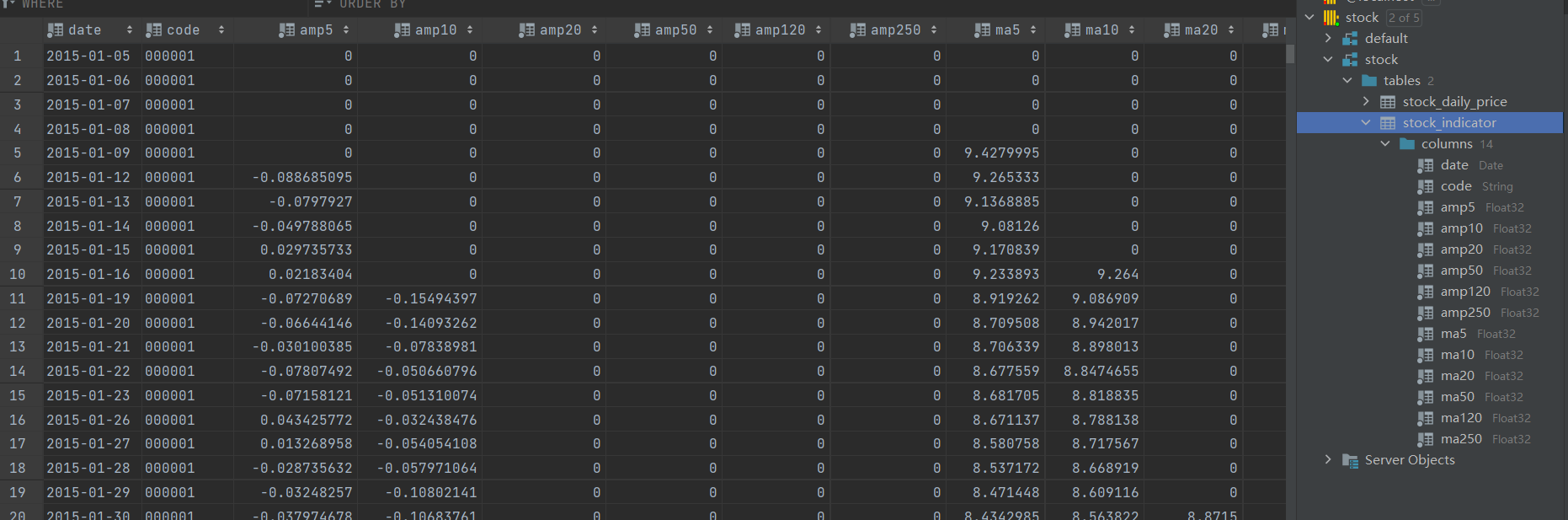
核心代码:
def _update_common_ind_task(self, codes, start_time, end_time, success_list):
"""
计算个股自身的的指标,股票池的形式查股票数据
:param codes: 任务集合的股票池
:param start_time: 开始时间
:param end_time: 结束时间
:param success_list: 计算成功列表
:return:
"""
# 查询基本日行情数据
stocks_df = sdb.pool_stock_daily(codes, start_time, end_time, ['close'])
if stocks_df.empty:
return
# 计算完的列表,用于后续拼接一次性插入数据库
ind_df_list = []
for code in codes:
daily_df = stocks_df.loc[stocks_df['code'] == code]
# 个股自身的振幅
ind_df = mathutils.amplitude(daily_df['close'], amp5=5, amp10=10,
amp20=20, amp50=50, amp120=120, amp250=250)
# 计算个股ma
ema_list = [5, 10, 20, 50, 120, 250]
for i in ema_list:
key = f'ma{str(i)}'
ind_df[key] = ta.EMA(daily_df['close'], timeperiod=i)
# 更新到指标表
if not ind_df.empty:
ind_df['code'] = code
ind_df_list.append(ind_df)
success_list.append(code)
# print(f'{code} 指标计算完毕')
result = pd.concat(ind_df_list)
if not result.empty:
sdb.to_indicator_table(result)
print(f'该任务完毕,插入数据库条目数: {len(result)}')
# 释放
del stocks_df
del ind_df_list
def update_common_ind(self):
"""
更新常用指标
:return:
"""
# 更新常用指标
config = self.config
config_df = config.config_df
format_str = '%Y-%m-%d'
end_time = config.update_end_time()
last_time = time.time()
# 先去重,避免更新有冲突
sdb.optimize(sdb.STOCK_DAILY_TABLE)
sdb.optimize(sdb.STOCK_INDICATOR_TABLE)
# 根据 cpu 个数拆分股票任务数
cpu_count = os.cpu_count()
with multiprocessing.Manager() as mg:
# 进程内数据共享
success_list = mg.list()
all_codes = list(config_df['code'])
item_count = int(len(all_codes) / cpu_count)
print(f'每个任务计算指标个数:{item_count} codeLength: {len(all_codes)}')
pool = multiprocessing.Pool(processes=cpu_count)
for index in range(cpu_count):
start_index = index * item_count
end_index = start_index + item_count
# 如果是最后一个任务,索引到最后
if index == cpu_count - 1:
end_index = len(all_codes)
# 切片,分任务
part_codes = all_codes[start_index: end_index]
ind_start_time = config.ind_start_time(part_codes[0])
# 偏移最大计算日期,最大日期 250 日均线,所以日行情数据开始位置要往前偏移
start_time = timeutils.time_str_delta(ind_start_time, format_str, days=-365)
if ind_start_time == end_time:
print(f'已经计算过 时间:{end_time}')
continue
print(f'任务{index} 开始位置:{start_index} 结束位置:{end_index}')
# 异步启动任务
pool.apply_async(self._update_common_ind_task,
args=(part_codes, start_time, end_time, success_list))
# 等待所有任务完毕
pool.close()
pool.join()
print(f'指标计算完毕,耗时:{time.time() - last_time}')
print(f'指标计算完毕 成功股票个数:{len(success_list)}')
# 更新配置信息
for code in success_list:
config_df.loc[config_df['code'] == code, 'ind_update_time'] = end_time
# 同步配置到本地
self.config.save_config()
# 操作完毕触发去重
sdb.optimize(sdb.STOCK_INDICATOR_TABLE)
要点分析:update_common_ind() 函数是全部股票根据 cpu 核数划分任务池。_update_common_ind_task() 是任务函数,每个进程领取的部分股票池计算。
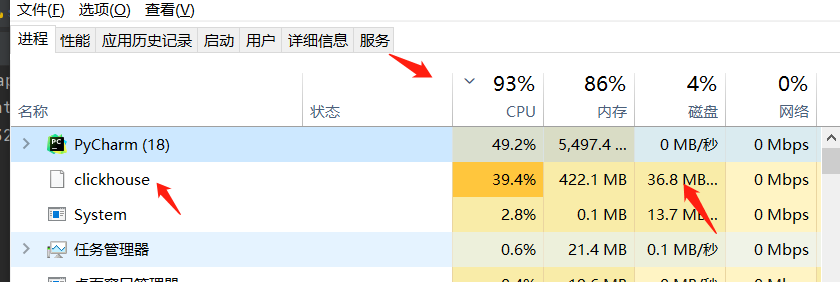
结果:
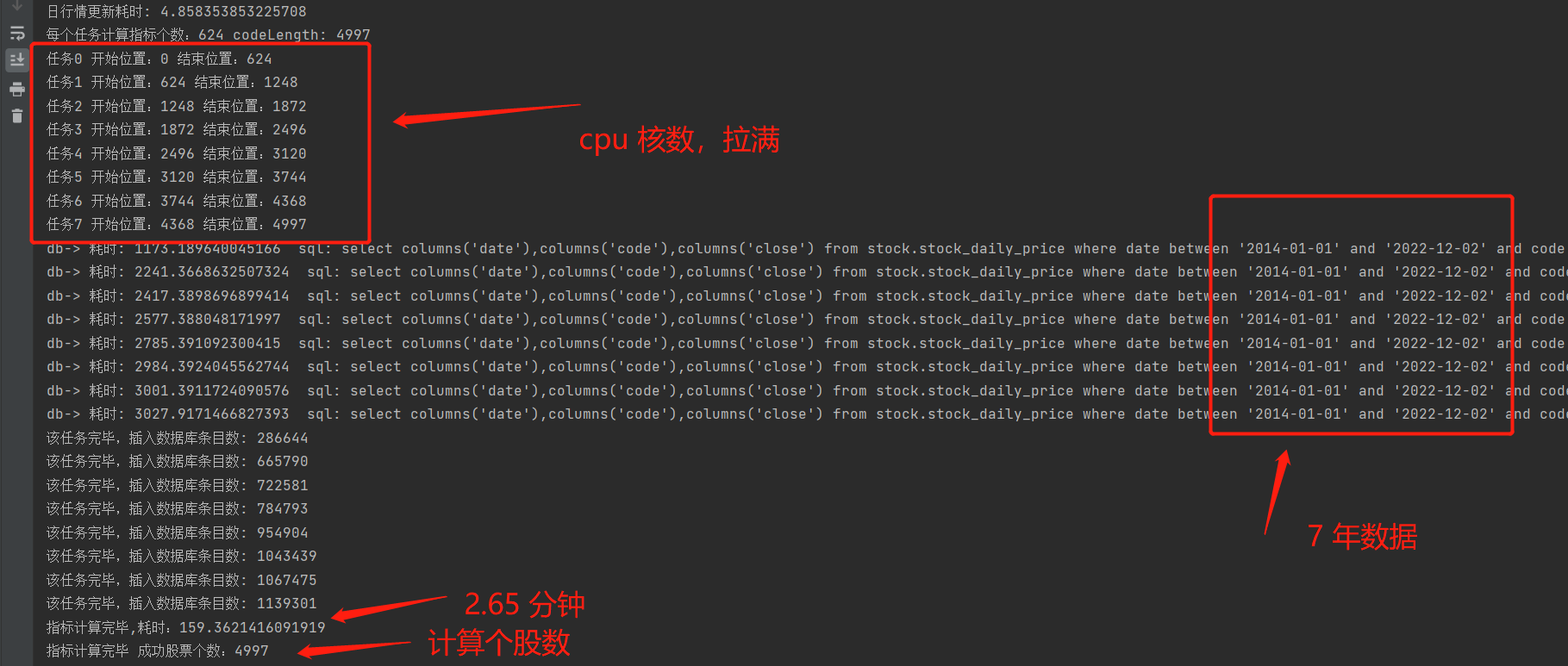
计算指标完毕后插入数据库时硬件使用情况,计算指标时可以看到 cpu 直接拉满。
参考链接
[1] 异步编程测试参考网址: https://afrankie.github.io/posts/一文搞懂python进程线程协程选择/
[2] 异步编程学习网址:https://gitee.com/paultest/asyncio_demo#协程--asyncio--异步编程
写于 2022 年 12 月 04 日 22:08:14
本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号