python 量化提速必备技能
量化必备技能进程、线程、协程
最近再做量化系统的时候,由于 python 不是很熟悉,日行情下载数据和数据清洗计算等都是单线程处理的,其速度无法忍受。
例如:日行情数据的更新,5000 左右个股票,更新一次,等待的时间可以把你验证想法的热情都浇灭,单线程的情况下,更新行情数据,你是可以去喝茶了,喝完茶再来看吧。还有后续的数据清洗计算、指标计算呢,时间指数级别递增。
为了解决这个痛点,学习了并发,并行的运行原理,学完后重构量化系统的下载和指标计算部分功能。
进程
进程是资源分配的基本单位,进程间的内存是隔离的。所以多进程间通信需要利用管道或队列。
参数介绍
| 参数 | 描述 |
|---|---|
| target | 表示调用对象,即子进程要执行的任务 |
| args | 表示调用对象的位置参数元组,args=(1,2,'a',) |
| kwargs | 表示调用对象的字典,kwargs= |
| name | 为子进程的名称 |
方法介绍
| 方法 | 描述 |
|---|---|
| start() | 启动进程 |
| run() | 进程启动时运行的方法,正是它去调用target指定的函数 |
| terminate() | 强制终止进程p |
| is_alive() | 如果p仍然运行,返回True |
| join([timeout]) | 主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态) |
属性介绍
| 属性 | 描述 |
|---|---|
| p.daemon | 默认值为False,如果设为True,代表p为后台运行的守护进程, 当p的父进程终止时,p也随之终止,并且设定为True后, p不能创建自己的新进程,必须在p.start()之前设置 |
| p.name | 进程的名称 |
| p.pid | 进程的pid |
| p.exitcode | 进程在运行时为None、如果为–N,表示被信号N结束(了解即可) |
| p.authkey | 进程的身份验证键 |
进程使用
写一个任务函数,然后进程直接调用
args 是传递给任务函数的参数,以元组的方式,注意最后一个逗号不能省略。
import time
from multiprocessing import Process, current_process
def task(name):
print('%s is running' % name, current_process().pid)
time.sleep(3)
print('%s is done' % name)
if __name__ == '__main__':
p_l = []
for i in range(1, 4):
p = Process(target=task, args=(f'大海{i}',))
p_l.append(p)
p.start()
for p in p_l:
p.join()
print('主程序', current_process().pid)
守护进程
守护进程会在主进程代码执行结束后就终止 ,但是父进程会等待子进程结束才正式结束。
注意:代码结束是指代码运行到了最后一行,并不代表进程已经结束了。
import time
from multiprocessing import Process
def func():
count = 1
while True:
print('*' * count)
time.sleep(1)
count += 1
def func2():
print('普通进程开始')
time.sleep(5)
print('普通进程结束')
if __name__ == '__main__':
p1 = Process(target=func)
p1.daemon = True
p1.start()
Process(target=func2).start()
time.sleep(3)
print('主进程')
保活案例:
import time
from multiprocessing import Process
def Guard():
while True:
time.sleep(2)
print('我还活着') # 向某个机器汇报我还活着,具体该怎么写汇报的逻辑就怎么写,这里只是示范
if __name__ == '__main__':
p = Process(target=Guard)
p.daemon = True
p.start()
# 主进程的逻辑(主进程应该是一直运行的,不应该有代码结束的时候)
time.sleep(3)
print('主进程')
while True:
time.sleep(100)
线程
线程是 cpu 的执行单位,线程存在于进程单位内,多线程共享进程内的资源,不需要借助任何机制。
线程使用
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(3)
print(f'{name} is done')
if __name__ == '__main__':
t = Thread(target=task, args=('线程1',))
t.start()
print('主')
使用方法其实和进程的使用方法差不多,使用场景不一样,多进程适合 cup 密集型场景,多线程适合 io 密集型场景。
GIL全局解析锁
什么是 GIL 全局锁解析锁?
互斥锁是把多个任务的共享数据的修改由并发变成串行,代码运行先拿到 cpu 的权限,还需要把代码丢给解析器,再在进程里面的线程运行。
GIL 本质就是一把互斥锁,相当于执行权限。
每个进程里面都会存在一把 GIL ,同一个进程内的多个线程必须抢到 GIL 之后才能使用解析器来执行自己的代码,即同一进程内的多线程无法实现并行,用不了多核(多个 CPU)优势。但是可以实现并发,因为多线程遇到 io 操作后就会释放 GIL 锁。
为啥要有 GIL?是因为垃圾回收机制并不是线程安全的。
每个进程内都存在一把 GIL ,意味着有锁才能计算,多进程适合处理计算密集型,多线程适合处理 io 密集型,所以多线程多核优势没有意义。
进程池和线程池
计算机开进程或线程是受限于计算机本身的硬件,进程池或线程池限制最大的进程或线程,不会造新的进程或线程,避免了浪费。
两种提交方式
同步调用:提交完一个任务后,就原地等待,等待任务完运行完毕拿到结果后再执行下一段代码,会导致任务串行执行。所谓的串行是指任务的运行状态。
异步调用:提交完一个任务后,不在原地等待,结果换个方式获取,提交完任务后会立即执行下一段代码,会导致任务并发执行。
同步调用
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time, os, random
def task(name):
print('%s %s is running' % (name, os.getpid()))
time.sleep(random.randint(1, 3))
return 123
if __name__ == '__main__':
p = ProcessPoolExecutor()
for i in range(20):
# 返回值
future = p.submit(task, '进程pid')
print(future.result())
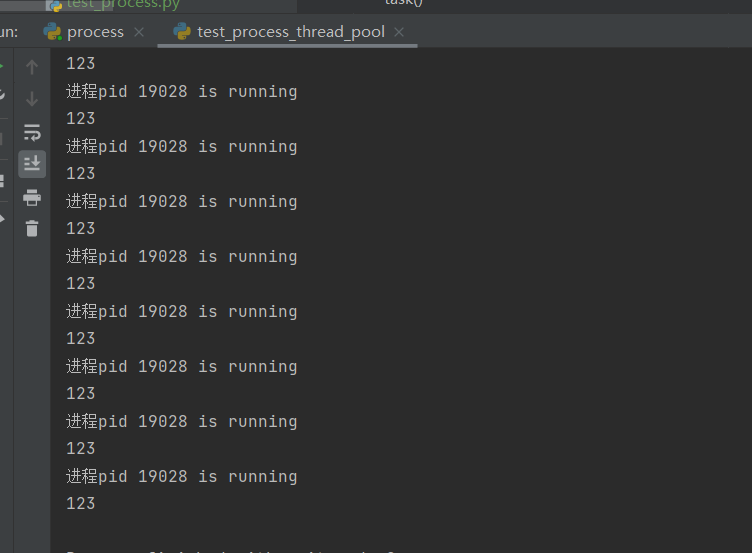
结果:
可以看出,任务是串行执行的。
异步调用
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time, os, random
if __name__ == '__main__':
p = ProcessPoolExecutor()
f_l = []
for i in range(5):
future = p.submit(task, '进程pid')
# 添加到列表
f_l.append(future)
# 关闭线程池入口,并在原地等待进程池所有任务运行完毕
p.shutdown(wait=True)
for future in f_l:
# 一次性全部拿到结果
print(future.result())
print('main')
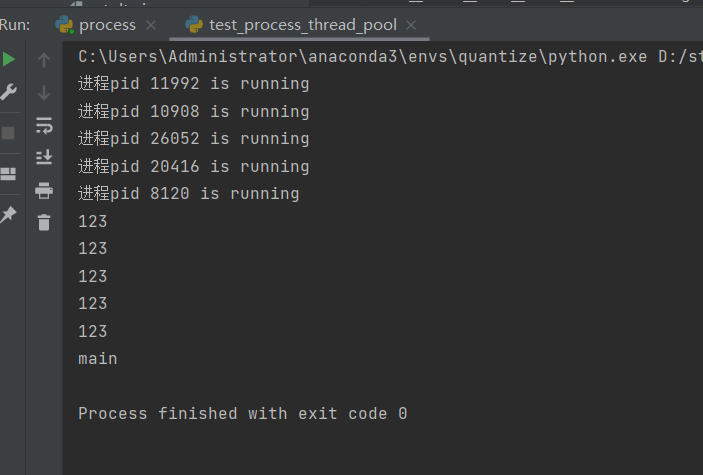
结果:
可以看出,任务是并行执行的。
进程池另外一种写法
import os
from multiprocessing import Pool
import requests
def scrape(url):
try:
requests.get(url)
print(f'URL {url}, Scrape pid: {os.getpid()}')
except requests.ConnectionError:
print(f'URL {url} not Scrape pid: {os.getpid()}')
if __name__ == '__main__':
pool = Pool(processes=3)
urls = [
'https://www.runoob.com/python3/python3-multithreading.html',
'https://developer.aliyun.com/article/609341',
'https://xueqiu.com/9708088213/218827030',
'http://joyfulpandas.datawhale.club/Content/ch10.html'
]
pool.map(scrape, urls)
pool.close()
异步解耦
大概意思是有上下文联系的多步步骤解耦在进程池或线程池里面进行执行,多部步骤而不是串行执行。
进程解耦示例
场景:一个下载 download() 函数,一个解析函数 parse(),想要的效果是谁先下载完先解析,两个函数都放在进程池或线程池里面跑。
import os
import random
import time
from concurrent.futures import ProcessPoolExecutor
def download(i):
print('%s 下载进程 %s ' % (os.getpid(), i))
time.sleep(random.randint(1, 3))
# 耦合的情况下是谁下载,谁解析
# parse(i)
return i
def parse(i):
# 上一个进程的Future
i = i.result()
print('%s 解析进程结果为%s ' % (os.getpid(), i))
time.sleep(1)
if __name__ == '__main__':
p = ProcessPoolExecutor(4)
start = time.time()
for i in range(9):
future = p.submit(download, i)
# 上一步进程的结果,扔到下一个进程解析,实现解耦,异步的9个进程,当闲下来的时候会做解析parse里面的事情
future.add_done_callback(parse)
p.shutdown(wait=True)
print('主', time.time() - start)
print('主', os.getpid())
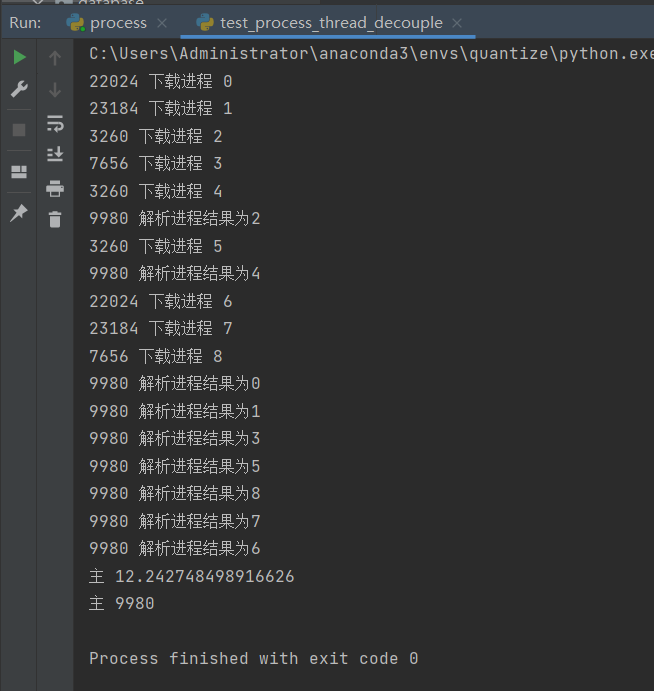
结果:
可以看出下载进程的 pid 与解析进程的 pid 是不一样的。future.add_done_callback() 函数是把上一步的 future 的结果传递到下一步 parse() 函数中, parse 接收到实参是上一步的 future 结果。
线程解耦示例
import os
import random
import time
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
def download(i):
print('%s 下载线程 %s ' % (current_thread().name, i))
time.sleep(random.randint(1, 3))
# 耦合的情况下是谁下载,谁解析
# parse(i)
return i
def parse(i):
# 上一个进程的Future
i = i.result()
print('%s 解析线程结果为%s ' % (current_thread().name, i))
time.sleep(1)
if __name__ == '__main__':
p = ThreadPoolExecutor(4)
start = time.time()
for i in range(9):
future = p.submit(download, i)
# 上一步线程的结果,扔到下一个线程解析,实现解耦,异步的线程,当闲下来的时候会做解析parse里面的事情
future.add_done_callback(parse)
p.shutdown(wait=True)
print('主', time.time() - start)
print('主', os.getpid())
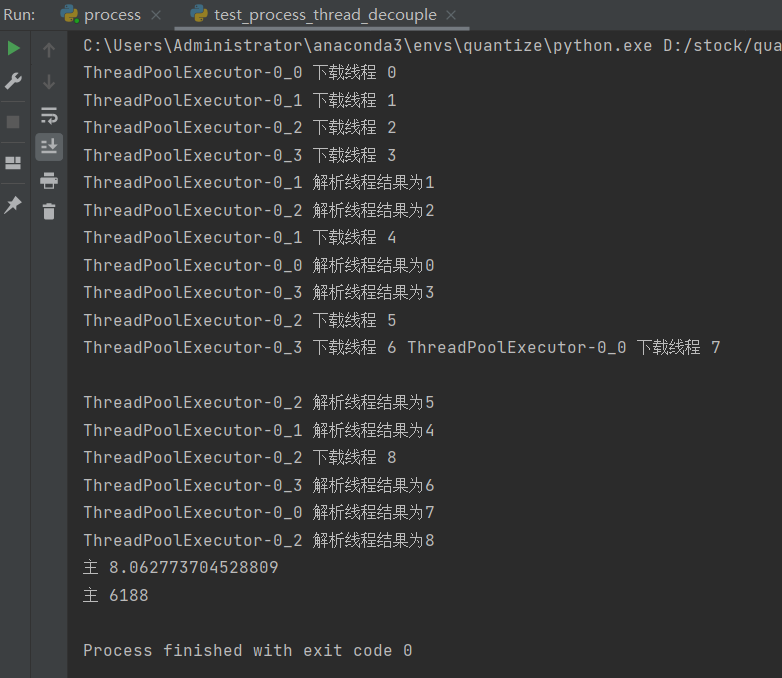
结果:
可以看出,使用上和进程池的使用差不多,只是换了 api 接口函数。
协程
协程解决了什么?
在学习协程之前,先回顾下多线程并发。
操作系统最小的调度单位是线程,所以多个线程并发看起来是同时执行,其实是操作系统处理了线程的切换、保存和恢复,这操作是耗性能的。
多进程其实也是多个线程,线程分散到了不同进程中执行,发挥多核的作用,在一个进程下多线程在遇到 io 上才发挥真正上的意义,遇到 io 让出 cup 时间片段给其他线程运行。
好的,那么既然多线程下的并发会在线程切换的情况下有性能损耗,如何才能发挥单线程的最大效率呢?那么主角协程来了。
协程是单线程的并发,又称微线程。注意了,协程并不是操作系统调度的,操作系统调度只有进程和线程,而协程是编程语言层面上搞出来的东西。
所以单线程下,遇到 io 就通过协程来切换,应为没到操作系统层级,所以可以最大程度发挥单线程的效率。协程没有遇到 io 切换会降低效率,遇到 io 切换会提高效率。
开始
安装依赖包
pip install gevent
示例代码:
from gevent import monkey
# 对所有 io 进行打包
monkey.patch_all()
# 导入 gevent 管理任务
from gevent import spawn, joinall
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
if __name__ == '__main__':
start = time.time()
g1 = spawn(play, '大海1')
g2 = spawn(eat, '大海2')
# 等待协程运行完毕
joinall([g1, g2])
print('主', time.time() - start)
异步协程
安装:
pip install aiohttp
示例:
import aiohttp, asyncio, aiofiles
import os
async def crawls(url):
"""
下载任务
:param url:
:return:
"""
async with aiohttp.ClientSession() as session:
async with session.get(url) as res:
if os.path.exists('images') is False:
os.mkdir('images')
async with aiofiles.open('./images' + url.split('/')[-1], 'wb') as f:
await f.write(await res.content.read())
async def run():
"""
构建任务
:return:
"""
url_list = [
'https://pic.netbian.com/uploads/allimg/210317/001935-16159115757f04.jpg',
'https://pic.netbian.com/uploads/allimg/210423/224716-16191892361adb.jpg',
'https://pic.netbian.com/uploads/allimg/220712/233259-1657639979a66c.jpg',
'https://pic.netbian.com/uploads/allimg/220814/231950-1660490390bbf4.jpg',
'https://pic.netbian.com/uploads/allimg/220827/223220-166161074052ed.jpg',
'https://pic.netbian.com/uploads/allimg/221009/194117-1665315677bc54.jpg'
]
tasks = []
for url in url_list:
tasks.append(crawls(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
起底协程
协程函数: 定义形式为 async def 的函数;
协程对象: 调用 协程函数所返回的对象。
关键字 async/await,在 python 3.5 后引入,async 被用来声明一个函数是协程,await 修饰协程函数是等待协程函数执行返回,await用来声明程序挂起,注意它是非阻塞的。
启动和运行一个事件循环(event loop),执行协程函数。
import asyncio
async def speak_async():
print('OMG asynchronicity!')
loop = asyncio.get_event_loop()
loop.run_until_complete(speak_async())
loop.close()
可等待对象
如果一个对象可以在 await 语句中使用,那么它就是 可等待 对象。许多 asyncio API 都被设计为接受可等待对象。
可等待 对象有三种主要类型: 协程, 任务 和 Future.
在线程或者进程池中执行代码
awaitable loop.run_in_executor(executor, func, *args)
import asyncio
import concurrent.futures
import time
def blocking_io():
time.sleep(3)
def cpu_bound():
return sum(i * i for i in range(10 ** 7))
async def main():
loop = asyncio.get_running_loop()
# 1. Run in the default loop's executor:
result = await loop.run_in_executor(None, blocking_io)
print('default thread pool', result)
# 2. Run in a custom thread pool:
with concurrent.futures.ThreadPoolExecutor() as pool:
result = await loop.run_in_executor(pool, blocking_io)
print('custom thread pool', result)
# 3. Run in a custom process pool:
with concurrent.futures.ProcessPoolExecutor() as pool:
result = await loop.run_in_executor(pool, cpu_bound)
print('custom process pool', result)
if __name__ == '__main__':
asyncio.run(main())
[1] 协程参考文档:https://docs.python.org/zh-cn/3/library/asyncio-eventloop.html
总结于 2022 年 11 月 28 日 23:14:15

本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号