Backtrader 数据篇
Backtrader 数据篇
上一篇已经学习了整个框架的大概划分模块,对于 Backtrader 这框架有了一个大概的认识,这篇将学习这框架基石--数据流程。
下面将会一一解答关于这框架 数据方面的疑问
怎么将数据填充到框架种?
数据组织形式是怎么样?
怎么访问数据?
在回测的过程种,数据流是以怎么形式传递?
怎么扩展其他回测指标?
数据填充
在简介篇,已经知道所有的模块有大脑统一控制管理,数据模块也不例外,所以首先要实例化 Cerebro ,然后往这 Cerebro 塞数据,再统一调度管理。
下面数据是以 dataframe 数据格式为例的介绍,当然 backtrader 也支持其他数据规范的格式,都差不多。
backtrader 把规范的数据包装成了 Data Feeds ,其实就是一个回测数据集合管理类。数据可以添加一个或者多个股票数据。
如何填充数据?
只需要指定数据源,回测时间段,即可添加多个股票数据源。
| 参数 | 描述 |
|---|---|
| dataname | 数据源 |
| fromdate | 回测开始时间 |
| todate | 回测结束时间 |
示例代码
# 股票查询开始和结束时间
start_query = '2022-01-01'
end_query = '2022-09-01'
# 回测开始和结束时间
start_date = datetime.datetime(2022, 7, 10)
end_date = datetime.datetime(2022, 8, 10)
cerebro = bt.Cerebro()
# 添加几个股票数据
codes = [
'300015',
'300347',
'300760',
'603127',
'600438'
]
# 添加多个股票回测数据
for code in codes:
data = sdb.stock_daily(code, start_query, end_query)
data.index.names = ['datetime']
date_feed = bt.feeds.PandasData(dataname=data, fromdate=start_date, todate=end_date)
cerebro.adddata(date_feed, name=code)
print('添加股票数据:code: %s' % code)
注意:查询的数据时间段与回测时间段是分开的,最终数据流是以回测时间段测试数据。
参数 name 是这张表的表名。 self.datas[0]._name 可以打印表名。
存储方式
把每个股票数据看作为一张表,其实就是一张指标维度和时间维度的表,self.datas 就是集合了多个股票的数据集,形成了一个三维数据源,分别是: 数据表维度、时间维度、指标维度。 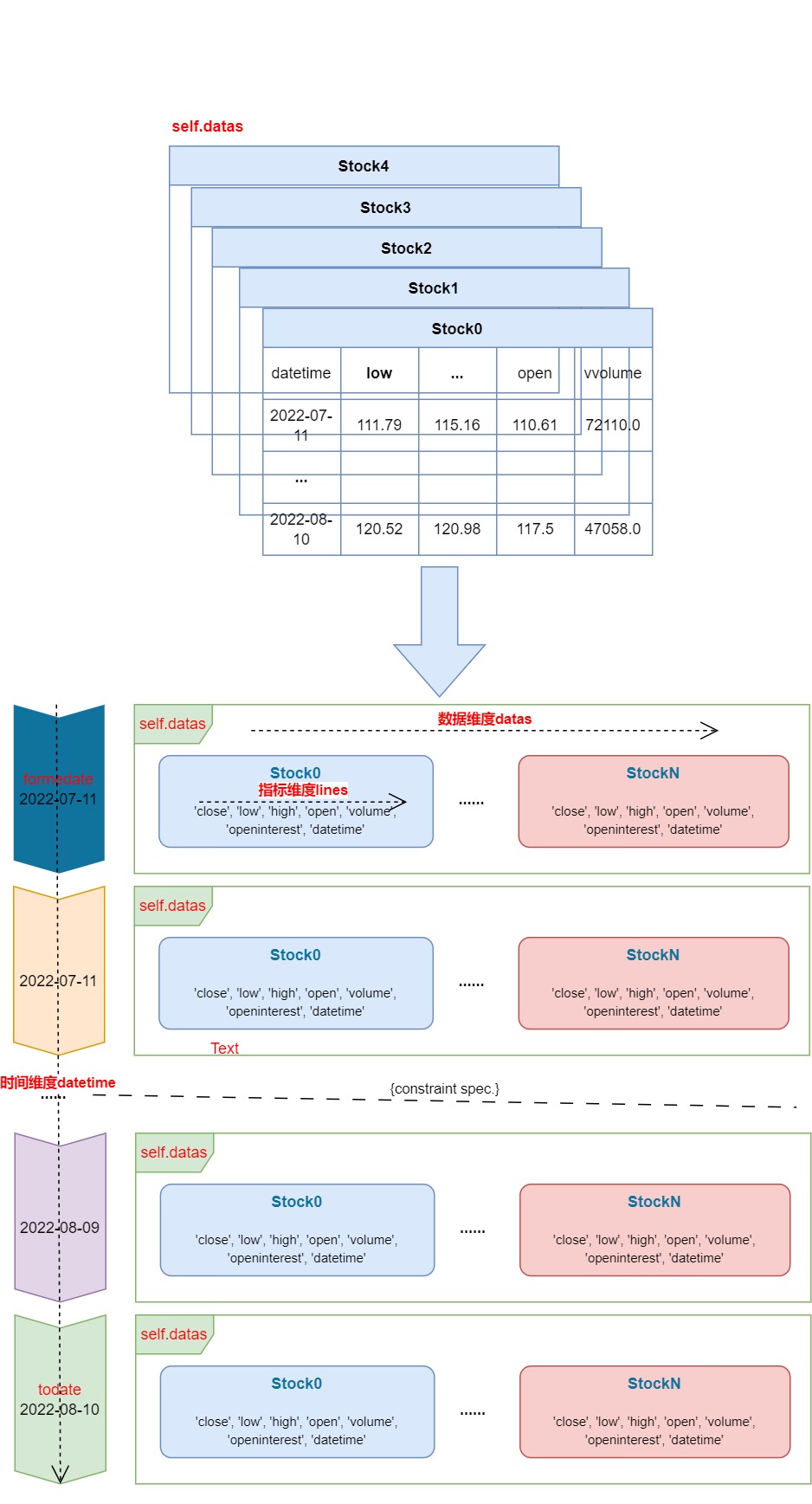
如上图所示,Data Feeds 种的 self.datas 数据类型是 list. 每个元素是一张包含时间维度和指标维度的股票数据表。
数据表维度
该维度其实就是 list 集合,集合了所有添加进来了股票数据,每个股票数据都有时间维度和指标维度构成的数据表。
self.datas[N]
指标维度
该维度是回测时使用的指标,除了常用指标还可以自定义指标。
self.datas[N].lines.xxx[M]
参数
| 字段 | 类型 | 描述 |
|---|---|---|
| datetime | float | 日期,如果打印日期, 用datetime.date[0] |
| open | float | 开盘价 |
| high | float | 最高价 |
| low | float | 最低价 |
| close | float | 收盘价 |
| volume | float | 成交量 |
| openinterest | float | 持仓量,一般没使用 |
| 其他扩展指标 | 其他 | 自定义或扩展指标,列如 pe 、pb |
所有的指标
self.data.lines.getlinealiases()
控制台
>> lines ('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime')
时间维度
时间维度其实是回测时间段,fromdate ~ todate 之间。
self.data[N].lines.datetime.date(M)
数据索引
self.datas 数据类型是 list
- 下标索引:self.datas[N],其中 N 为 0 到 N-1 时,是正向,N 为 -1 到 -N 时为反向
- 缩写索引,self.dataN ,注意不是 datas 。N 为 0 到 N-1。
- 表名索引,self.getdatabyname('name'),其中 name 为导入数据时 adddata(date_feed, name=code) 时设置的表名。
- 第一个数据集索引,self.datas[0] 等价 self.data0 等价 self.data
注意:self.datas 和 self.data 的区别,self.datas 是数据集合 list. self.data 是第 0 个数据。self.dataN 的访问是没有 s 的。
self.datas[N].lines
索引方式
日期:self.datas[N].lines.datetime.date(N)
其他:self.datas[N].lines.其他字段名(open、high、low、close、volume)[N]
注意:datetime 是以 float 数据类型存储,访问是需要借助 xxx.date(N) 函数进行转换。
示例
# 访问第一个数据表的 close 指标的索引 0
self.data[0].lines.close[0]
切片方式
self.data1.lines.close.get(ago=N, size=M))
| 参数 | 描述 |
|---|---|
| ago | 索引开始位置 |
| size | 切片大小 |
返回值:array 数组 [close[N-(M-1)],...,close[N-1],close[N]]
如果 N - (M - 1) <1,返回空数组 []。
列如:N = 3 ,M = 4,返回 [].
策略中的数据流
回测长度:N = self.data.buflen()
索引下标 0 的含义
索引下标 0 在 init() 函数和 next() 函数是不一样的,在 init() 函数中索引 0 是代表回测时间 todate ,在 next() 函数中 索引 0 是代表当前回测的时间。
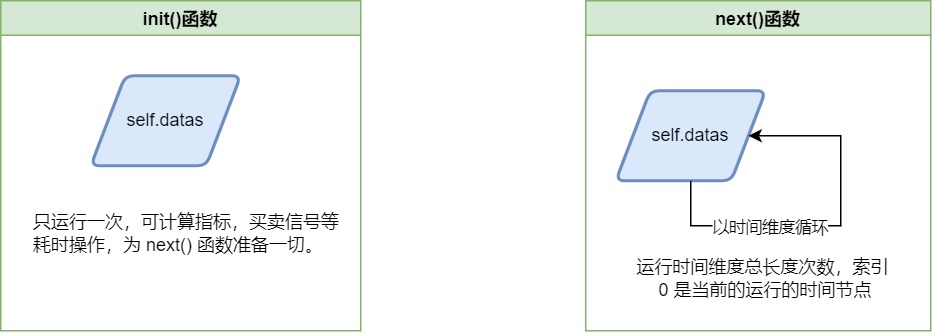
init()函数中的数据流
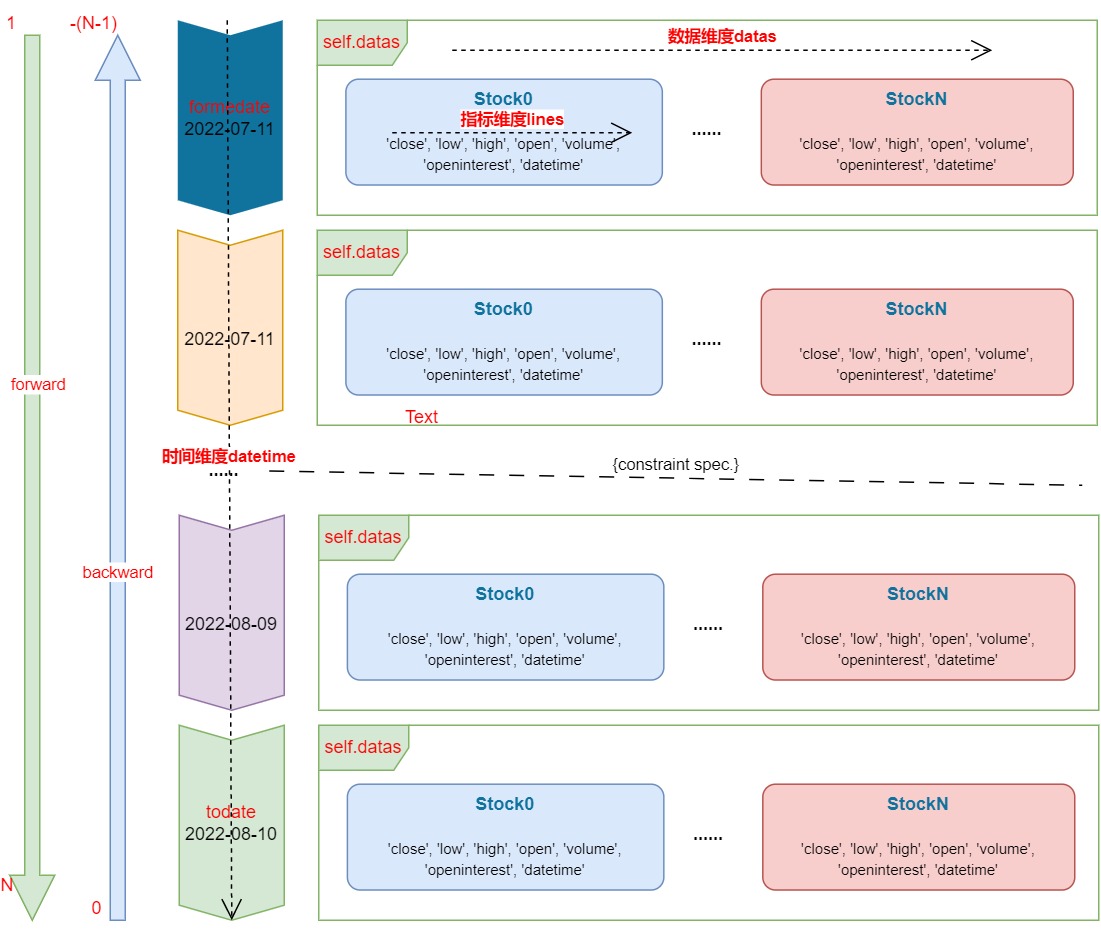
在 init() 函数中,索引 0 是 todate ,索引 1 是 fromdate. 支持 正向和反向访问的两种方式。
- 正向索引的索引下标为 1、2 ... N
- 反向索引下标为 0 、-1、-2 ... -(N-1).
其中,对应下标值是相同
| 正向索引 | 反向索引 |
|---|---|
| 0 | N |
| 1 | -(N-1) |
| 2 | -(N-2) |
| ... | ... |
| N-1 | -1 |
| N | 0 |
next()函数中的数据流
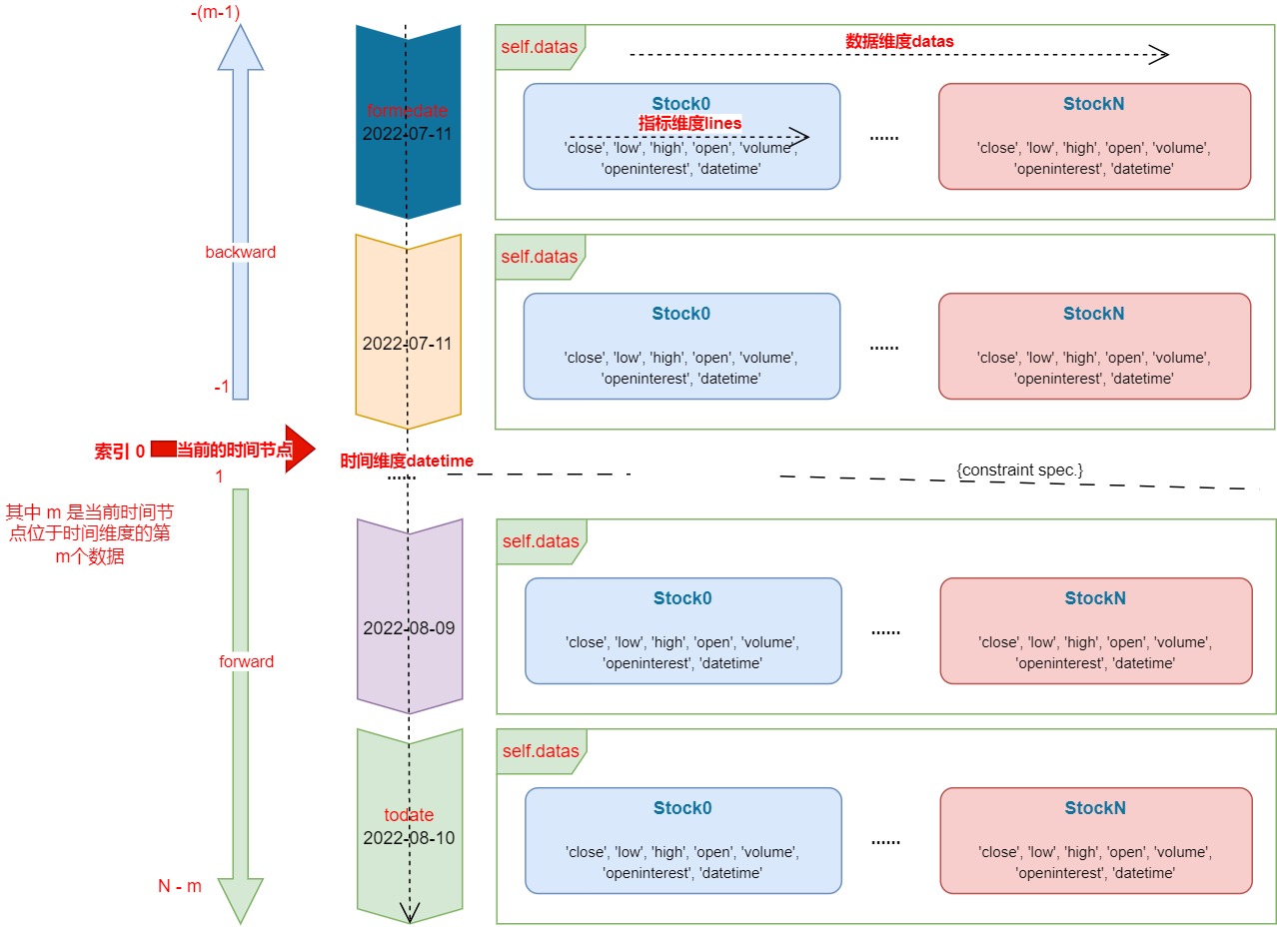
在 next() 函数中,索引 0 永远是当前的时间节点,索引 0 随着以时间维度的循环,不停的移动。backtrader 是已经回测过的了,forward 是还没有回测到的。
自定义读取数据
如果你觉得每次都要设置这么多参数来告知指标位置很麻烦,那你也可以重新自定义数据读取函数,自定义的方式就是继承数据加载类 GenericCSVData、PandasData 再构建一个新的类,然后在新的类里统一设置参数:
class My_PandasData(bt.feeds.PandasData):
params = (
('fromdate', datetime.datetime(2019, 1, 2)),
('todate', datetime.datetime(2021, 1, 28)),
('nullvalue', 0.0),
('dtformat', ('%Y-%m-%d')),
('datetime', 0),
('time', -1),
('high', 3),
('low', 4),
('open', 2),
('close', 5),
('volume', 6),
('openinterest', -1)
)
新增指标
backtrader 除了提供基本的指标外('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime'),还提供给用户自定义扩展。例如:macd,pe,pb等等指标。
如何扩展?
- 继承 bt.feeds.PandasData 类,定义新指标。
- 数据源扩展新指标对应的列,并初始化新指标值。
示例
# 继承
class PandasData_more(bt.feeds.PandasData):
lines = ('pe', 'pb',) # 要添加的线
# 设置 line 在数据源上的列位置
params = (
('pe', -1),
('pb', -1),
)
# 数据源新增列
# 股票查询开始和结束时间
start_query = '2022-01-01'
end_query = '2022-09-01'
# 回测开始和结束时间
start_date = datetime.datetime(2022, 7, 11)
end_date = datetime.datetime(2022, 8, 10)
cerebro = bt.Cerebro()
# 添加几个股票数据
codes = [
'300015',
'300347',
'300760',
'603127',
'600438'
]
# 添加多个股票回测数据
for code in codes:
data = sdb.stock_daily(code, start_query, end_query)
data.index.names = ['datetime']
# 新增指标列
data['pe'] = 3
data['pb'] = 4
date_feed = PandasData_more(dataname=data, fromdate=start_date, todate=end_date)
cerebro.adddata(date_feed, name=code)
print('添加股票数据:code: %s' % code)
cerebro.addstrategy(TestStrategy)
cerebro.run()
常用函数手册
| 函数 | 描述 |
|---|---|
| self.data.buflen() | 回测总长度 |
| len(self.data) | 已经处理的数据位置 |
| self.data.lines.getlinealiases() | 指标列表 |
| bt.Strategy.init() | 一次调用,策略初始化函数 计算指标值,买卖信号等耗时操作 |
| bt.Strategy.next() | 多次调用,策略回测调用函数 循环所有的回测时间段 |
| self.datas[N].lines.datetime.date(N) | 日期索引 |
| self.datas[N].lines.close.date(N) | 指标close索引 |
| self.getdatabyname('name') | 表名索引,表名建议以code命名 |
| self.dataT.lines.close.get(ago=N, size=M)) | 切片函数 |
| bt.num2date() | 时间 datatime 格式将其转为“xxxx-xx-xx xx:xx:xx”这种形式 |
测试示例
import datetime
import backtrader as bt
import stock_db as sdb
class PandasData_more(bt.feeds.PandasData):
lines = ('pe', 'pb',) # 要添加的线
# 设置 line 在数据源上的列位置
params = (
('pe', -1),
('pb', -1),
)
class My_PandasData(bt.feeds.PandasData):
params = (
('fromdate', datetime.datetime(2019, 1, 2)),
('todate', datetime.datetime(2021, 1, 28)),
('nullvalue', 0.0),
('dtformat', ('%Y-%m-%d')),
('datetime', 0),
('time', -1),
('high', 3),
('low', 4),
('open', 2),
('close', 5),
('volume', 6),
('openinterest', -1)
)
class TestStrategy(bt.Strategy):
# 可选,设置回测的可变参数:如移动均线的周期
# params = (
# (..., ...), # 最后一个“,”最好别删!
# )
def log(self, txt, dt=None):
"""
可选,构建策略打印日志的函数:可用于打印订单记录或交易记录等
:param txt:
:param dt:
:return:
"""
dt = dt or self.datas[0].datetime.date(0)
print('%s,%s' % (dt.isoformat(), txt))
def __init__(self):
"""
必选,初始化属性、计算指标等
"""
print(type(self.datas[0].lines.datetime[0]))
print(type(self.datas[0].lines.volume[0]))
self.count = 0
print("------------- init 中的索引位置-------------")
print('lines', self.data1.lines.getlinealiases())
print('datas type', type(self.datas))
print("0 索引:", 'datetime', self.datas[1].lines.datetime.date(0), 'close', self.data1.lines.close[0])
print('-1 索引:', 'datetime', self.data1.lines.datetime.date(-1), 'close', self.data1.lines.close[-1])
print('-2 索引:', 'datetime', self.data1.lines.datetime.date(-2), 'close', self.data1.lines.close[-2])
print('1 索引: ', 'datetime', self.data1.lines.datetime.date(1), 'close', self.data1.lines.close[1])
print('2 索引: ', 'datetime', self.data1.lines.datetime.date(2), 'close', self.data1.lines.close[2])
print('从 0 开始往前取3天的收盘价:', self.data1.lines.close.get(ago=0, size=3))
print("从-1开始往前取3天的收盘价:", self.data1.lines.close.get(ago=3, size=3))
print("从-2开始往前取3天的收盘价:", self.data1.lines.close.get(ago=-2, size=3))
print("回测的总长度:", self.data.buflen())
pass
def notify_order(self, order):
"""
可选,打印订单信息
:param order:
:return:
"""
pass
def notify_trade(self, trade):
"""
可选,打印交易信息
:param trade:
:return:
"""
pass
def next(self):
"""
必选,编写交易策略逻辑
:return:
"""
print(f"------------- next 的第{self.count + 1}次循环 --------------")
print('当前节点(今日): ', 'datetime', self.data1.lines.datetime.date(0), 'close', self.data1.lines.close[0])
print("往前推1天(昨日):", 'datetime', self.data1.lines.datetime.date(-1), 'close', self.data1.lines.close[-1])
print("往前推2天(前日)", 'datetime', self.data1.lines.datetime.date(-2), 'close', self.data1.lines.close[-2])
print("前日、昨日、今日的收盘价:", self.data1.lines.close.get(ago=0, size=3))
# print("往后推1天(明日):", 'datetime', self.data1.lines.datetime.date(1), 'close', self.data1.lines.close[1])
# print("往后推2天(明后日)", 'datetime', self.data1.lines.datetime.date(2), 'close', self.data1.lines.close[2])
print("已处理的数据点:", len(self.data))
print("回测的总长度:", self.data.buflen())
self.count += 1
pass
# 股票查询开始和结束时间
start_query = '2022-01-01'
end_query = '2022-09-01'
# 回测开始和结束时间
start_date = datetime.datetime(2022, 7, 11)
end_date = datetime.datetime(2022, 8, 10)
cerebro = bt.Cerebro()
# 添加几个股票数据
codes = [
'300015',
'300347',
'300760',
'603127',
'600438'
]
# 添加多个股票回测数据
for code in codes:
data = sdb.stock_daily(code, start_query, end_query)
data.index.names = ['datetime']
# 新增指标列
data['pe'] = 3
data['pb'] = 4
date_feed = PandasData_more(dataname=data, fromdate=start_date, todate=end_date)
cerebro.adddata(date_feed, name=code)
print('添加股票数据:code: %s' % code)
cerebro.addstrategy(TestStrategy)
cerebro.run()
# cerebro.plot()
if __name__ == '__main__':
pass
写于 2022 年 10 月 05 日 14:24:59


 浙公网安备 33010602011771号
浙公网安备 33010602011771号