面向对象第一单元总结回顾
OO第一单元总结回顾
1.前言
OO第一单元的作业围绕表达式化简。考虑到增量式开发需要程序具有良好的可拓展性,三次作业都采用递归下降的方法,表达式、项、因子逐级分析,再针对不同层次采用不同的化简、合并策略。下面对各次作业展开分析。
2.各次作业分析
2.1第一次作业
Part 1. 基本思路
第一次作业要求读入一行表达式,展开其中的所有括号后输出。数据限制包括:括号深度最多一层,指数不为负数等。性能分数则根据输出字符串的长度决定,越短越高。
第一次作业建立的递归下降架构是后续作业的基础,参考了实验课提供的递归下降例程,本人的程序类图如下:
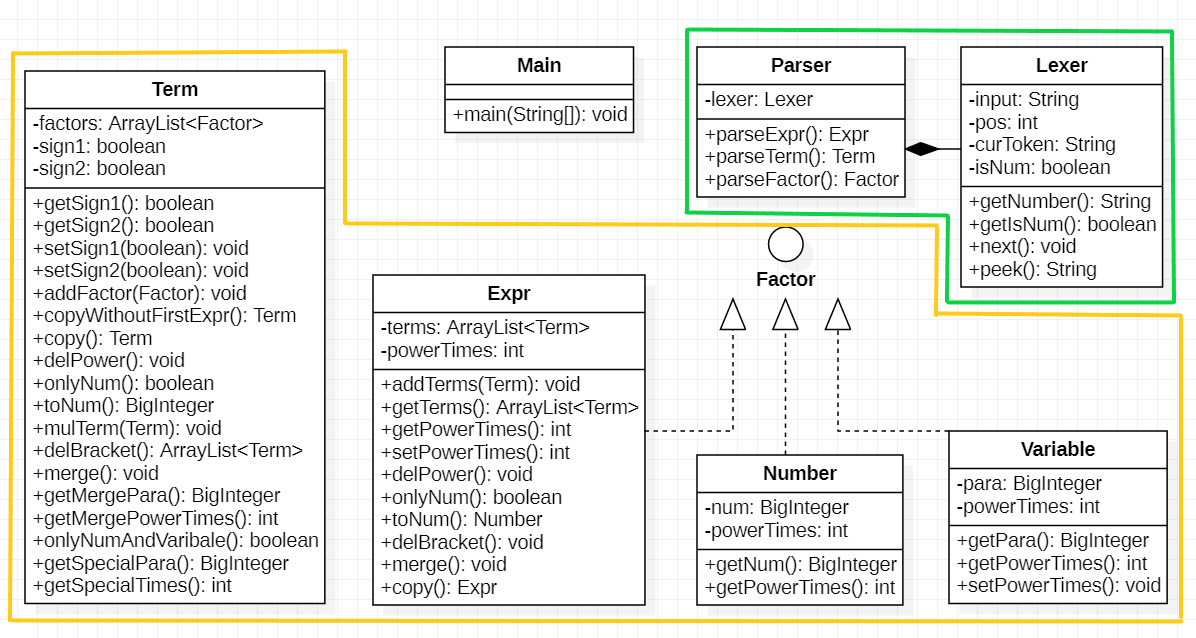
绿色框中的类用于解析表达式,橙色框中的类用于构成表达式树。
程序对表达式的处理步骤如下:
- 首先以字符串形式的表达式创建
Lexer对象,并由Lexer对象创建Parser对象; - 调用
Parser对象的parseExpr()方法,后者递归调用parseTerm()方法,parseFactor()方法,建立表达式树,并返回建立的Expr对象; - 调用
Expr对象的delPower()方法,将所有指数大于1的表达式化简为多个表达式相乘; - 调用
Expr对象的delBracket()方法,使用乘法分配律展开括号; - 调用
Expr对象的merge()方法,将表达式的各项同类项合并,并输出化简后的表达式。
Part 2. 优化点
由于作业一实现相对容易,我转而在优化上投入了大量时间,尽可能地达到最佳性能。采取的优化策略包括:
- 指数为0的项化简为数字1;
- 合并所有同类项;
- 输出时,参数为正数的项优先作为首项输出,并省略其正号;
- 输出时,指数为1的项不输出指数;
- 输出时,参数为1且含有变量x的项不输出参数;
- 输出时,指数为2的幂函数,不输出
x**2,转而输出x*x
Part 3. 类方法分析
使用MetricsReloaded工具分析各类的方法,得到如下结果:
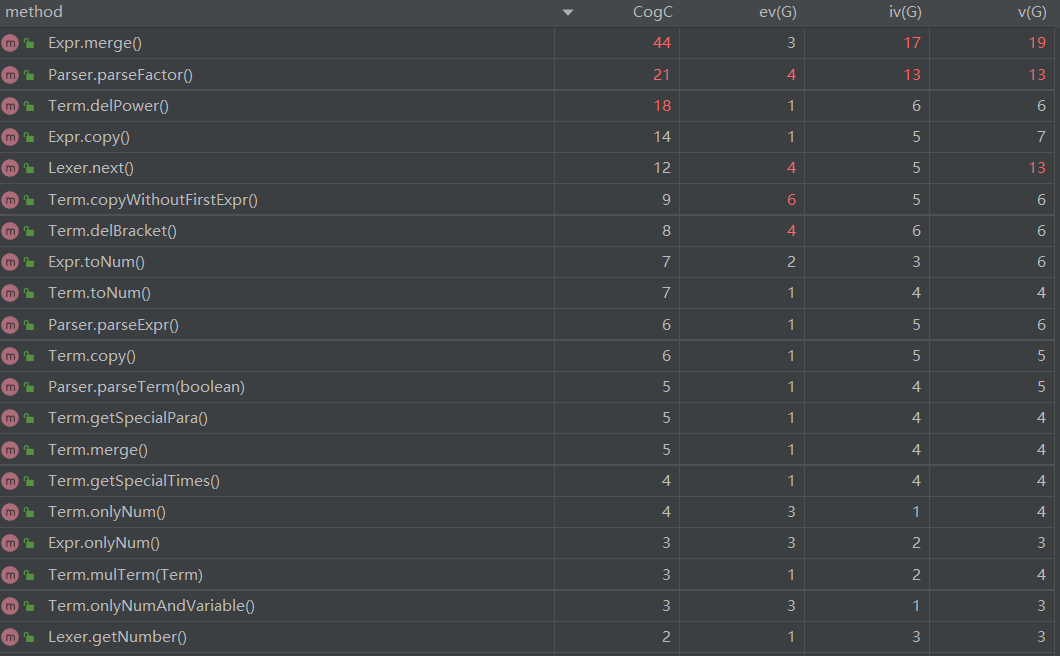
以上图片截取了复杂度最高的方法。分析表明,Expr类的merge()方法复杂度最高,这是因为该方法同时完成合并同类项和输出结果的任务,任务过重,属于设计时的缺陷;Parser类的parseFactor()方法复杂度较高,这是因为该方法需要同时考虑Number类,Variable类和Expr类的解析;Term类的delPower()方法复杂度较高,这是因为该方法特判了指数为0的情况,比较繁琐。
Part 4. 类分析
使用MetricsReloaded工具分析各类,得到如下结果:
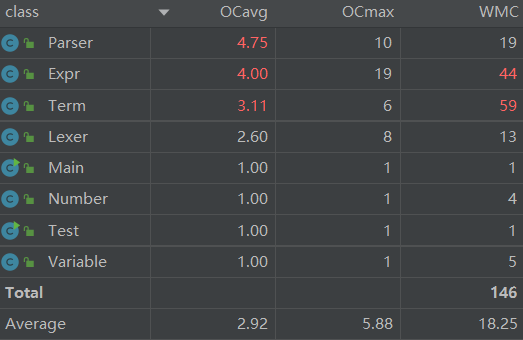
分析表明,Parser类的平均圈复杂度最高,这是因为Parser类在解析表达式、项、因子时需要考虑许多细节问题,例如表达式是否包含指数等;Expr类和Term类的平均圈复杂度,总圈复杂度都很高,这是因为这两个类的方法大多比较复杂,同时,两个类方法过多,任务过重,也导致了总循环复杂度较高。
2.2 第二次作业
Part 1. 基本思路
第二次作业要求在第一次作业的基础上增加了三种新的因子:三角函数、自定义函数和求和函数,程序功能拓展为展开所有的自定义函数和求和函数,并展开除三角函数调用的括号以外的所有括号。同时,第二次作业不再限制括号深度。
第二次作业的实现中,我增加了TriFunc类用于表示三角函数,增加了CustomFuncManage类和CustomFunc类分别用于管理和处理自定义函数,增加了SumFunc类用于处理求和函数。此外,为了满足三角函数带来的复杂化简需求,增加了MergeTerm类和MergeFactor类用于同类项合并和化简。
程序类图如下(红色方框中的类为本次新增的类):
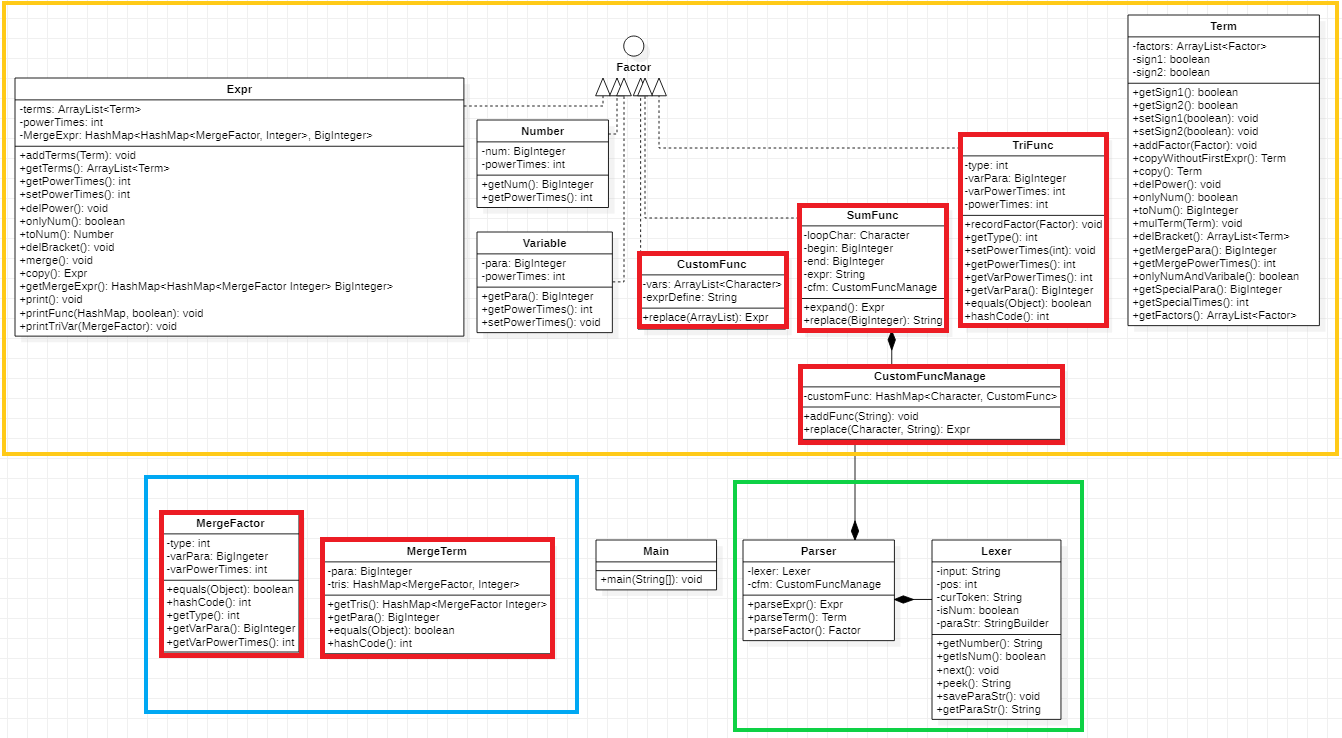
程序的类主要分为三个部分:绿色框中的类用于解析表达式,橙色框中的类用于构成表达式树,蓝色框中的类用于表达式化简。
程序的执行步骤与第一次作业类似,此处仅指出不同点:
- 在调用
Parser类的方法解析时,parseFactor()方法增加了对三角函数、自定义函数和求和函数的解析,其中后两者会直接处理字符串,返回替换后的表达式 - 为了减轻
Expr类和Term类的负担,并实现三角函数合并,化简工作交由MergeFactor类和MergeTerm类完成,两个类都重写了equals()和hashCode()方法,用于判断两项是否可以合并。
Part 2. 优化点
本次作业的优化策略相较于第一次作业,主要体现在增加了三角函数的合并。
Part 3. 类方法分析
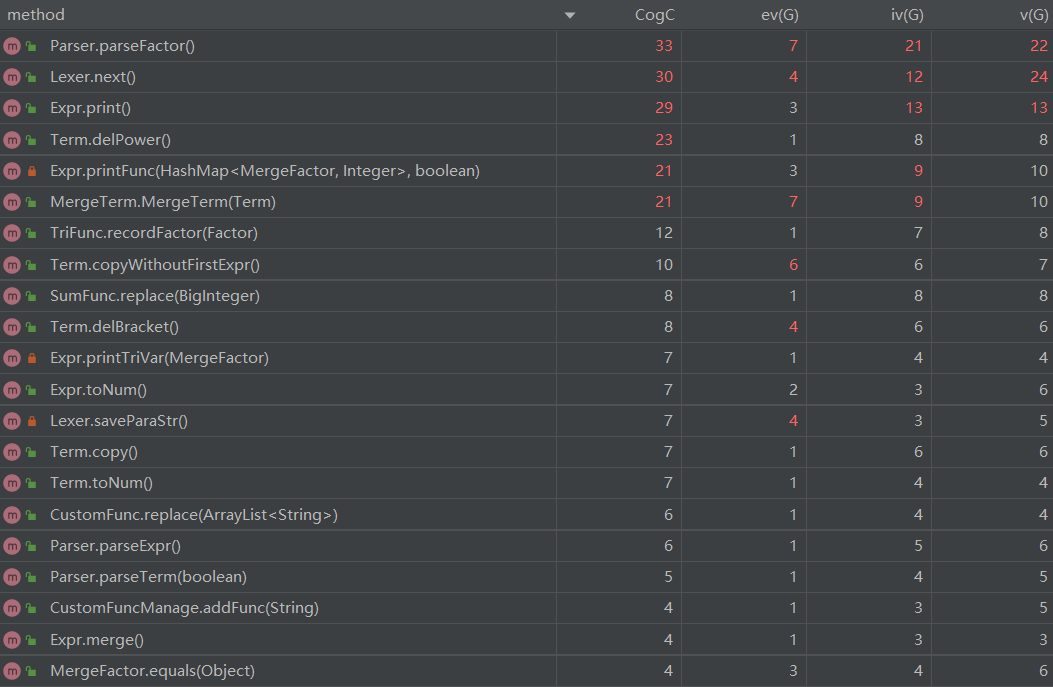
以上分析仅截取了复杂度最高的部分方法。分析表明,Parser类的parseFactor()方法和Lexer类的next()方法复杂度较高,这是因为随着因子种类的变多,两个方法不可避免地需要增加分支来判断新的因子;Expr类的print()方法和printFunc()方法为了减少字符串长度,设置了各种条件语句来匹配可以优化的地方;Term类的delPower()方法和MergeTerm类的MergeTerm()方法因为根据不同因子类型采用不同的化简指数和合并策略,所以复杂度较高。
Part 4. 类分析
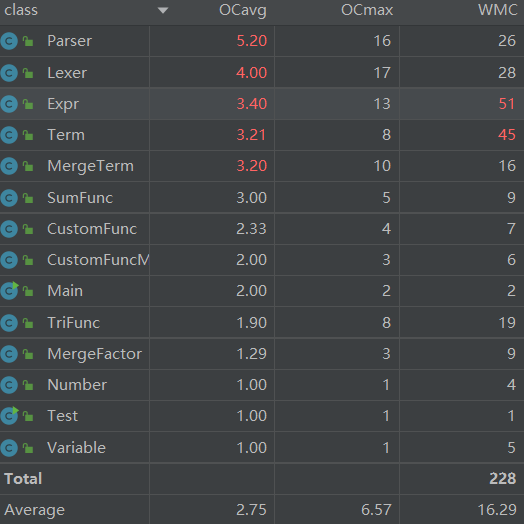
分析表明,Parser类, Lexer类, Expr类, Term类, MergeTerm类的平均圈复杂度较高,大都因为这些类需要对不同因子分别判断和处理。
2.3 第三次作业
Part 1. 基本思路
第三次作业要求在第二次作业的基础上增加嵌套因子,允许任何因子充当三角函数和自定义函数调用的因子。简单来说,程序需要能在解析表达式时递归解析另一个表达式。
为了支持三角函数嵌套因子,我增加了TriExprFunc类。该类继承TriExpr类并支持三角函数内含表达式因子。我的程序类图如下(红色方框中的类为本次新增的类):

程序的类主要分为三个部分:绿色框中的类用于解析表达式,橙色框中的类用于构成表达式树,蓝色框中的类用于表达式化简。
Part 2. 优化点
由于本次作业优化较为困难且容易出错,本次作业未进行优化。
Part 3. 类方法分析
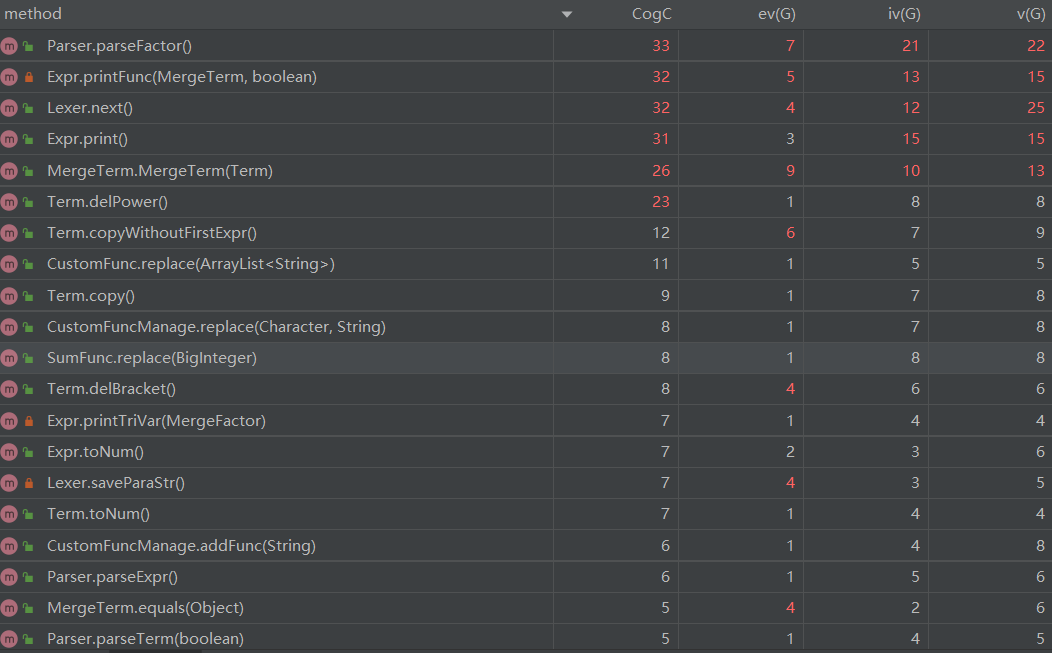
以上分析仅截取了复杂度最高的类方法。第三次作业类方法分析结果与第二次作业非常接近,在此不再论述。
Part 4. 类分析
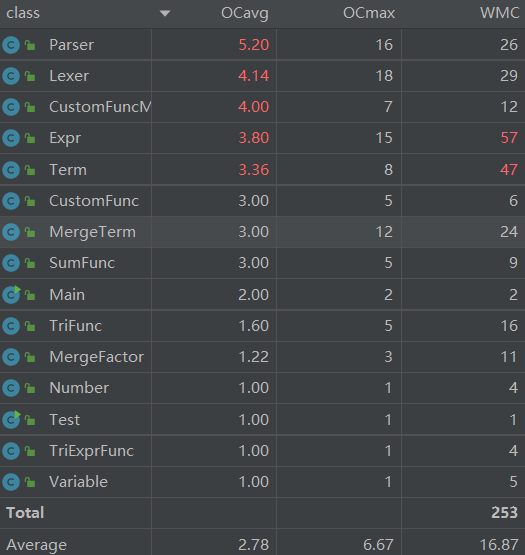
类分析结果与第二次作业类似,新增的TriExprFunc类复杂度较低,在此不再展开论述。
3 优缺点分析
三次作业的实现方法优缺点并存,分析如下:
优点:
- 采用递归下降方法,结构清晰,易于拓展;
- 设计的类逻辑合理,符合人类思维;各个类分工合理,基本做到高内聚低耦合;
- 采用了继承和接口实现,增加了代码复用性和可读性;
- 采用多种方法提升性能。
缺点:
- 部分类和类方法任务过重,缺乏分工,复杂度较高;
- 正确性和性能的实现相互分离,分别考虑,缺乏整体性。性能优化的代码非常冗余;
- 未找到既能保持低复杂度,又能支持多种因子解析的方法。
4 Bug分析
4.1 自己作业的Bug分析
第一次作业中,我因为BNF描述阅读不仔细,误以为常数因子处于int范围,导致Parser类的parserFactor()方法出现Bug,并花了较多时间发现这一问题。
第二次作业中,我本人并未发现Bug,却在强测中被测出一个Bug:由于追求性能分,我在Expr类的merge()方法中将部分三角函数化简为sin(x*x)或cos(x*x)的形式,然而这种形式并不符合BNF描述,所以未通过部分测试点。
第三次作业中,同样因为BNF描述阅读不仔细,我漏掉了自定义函数调用中,自定义函数名和'('中间的空白符,导致Parser类的parserFactor()方法运行时错误。
总结本次作业中我的代码出现的Bug,可以得到如下经验:
- 形式化表述一定要逐字逐句仔细阅读。
- 追求性能分的同时一定要确保正确性不受影响。
同时,经过对比,我发现出现Bug的地方均是圈复杂度较高的地方(Expr类的merge()方法,Parser类的parserFactor()方法),由此可见圈复杂度较高的代码可能会对程序员造成干扰,这体现了追求低复杂度的意义。
4.2 发现的同屋Bug
我在本单元中自行设计了评测机,用于自测和互测。评测机通过python实现,分为三个步骤:测试样例随机生成、运行jar包获得程序输出、比对程序输出和正确输出。在实现中,我使用了python的sympy包用于表达式化简和比较,使用了subprocess包用于执行jar包。
通过评测机自动测试,我找到了同屋其他同学的一些Bug,列举如下:
- 第一次作业:解析部分错误,导致形如
1*-1这种乘法接负数的表达式出错; - 第二次作业:为了追求性能,导致当正确输出为0时不输出;
- 第二次作业:解析部分错误,导致形如
sin(-1)这种因子为负数的三角函数出错; - 第三次作业:支持的数据范围不满足要求,
sum(i,s,e,t)中的s和e不支持超长整数。
通过本次互测,可以总结出以下经验:
- 通过评测机测试远比人工测试更快速,有效;
- 同学们的错误主要集中于解析错误等,其根因在于形式化表述的解析过程不严谨,可见仔细阅读形式化表述的重要性。
5 架构设计体验
5.1 架构成型过程
由于第一次作业就采用了拓展性强的递归下降方法,在本单元中,我基本上没有需要重构的地方,可以直接针对需求增添新的功能模块。为了支持第二次作业,我增加了TriFunc等新的因子类和MergeTerm等新的合并类;为了支持第三次作业,我增加了TriExprFunc因子类用于三角函数嵌套因子,架构的成型过程循序渐进、连续一致。
5.2 心得体会
由于我上学期修过《Java程序设计》一课,Java使用比较熟练,因此本次作业中语言使用方面的问题几乎没有出现。与之相对,思路上的问题则让我觉得比较吃力。
第一次作业中,考虑到后续迭代开发,我决定使用递归下降算法。尽管课程组在课上实验提供了递归下降的模板代码,我依然花费了较多时间才得以理解。而从理解到自己能熟练使用,又需要更深入地学习。不过,由于第一次作业整体难度较低,最终还是较顺利地完成了。为了保证作业的正确性,我用剩余的时间写了一个评测机,较严谨地评测了自己的代码,最终在强测中取得满分。第一次作业的顺利完成很大地增长了我的信心。
第二次作业中,我遇到的难点在于深拷贝和equals()方法重写。由于第二次作业不再限制括号深度,我的代码不可避免地需要使用深拷贝;同时,为了合并同类项,又不得不重写equals()方法。为了解决这两个问题,我搜了许多网上的资料,学习了讨论区和助教们提供的许多方法,最终得以解决这两个问题。第二次作业给我带来的收获就在于提高了自己搜集资料,解决问题的能力。
第三次作业中,我在代码实现上基本没有遇到阻碍,很快就完成了迭代开发,但却被一个弱测点困扰了很久。这次作业的debug时间尤其漫长,我使用了各种方法,包括逐字逐句与第二次作业对比、使用各类自己的样例测试,最后使用评测机测试都没能解决问题。无奈之下只得自己重新一点一点看指导书和代码。最后发现问题出在形式化表述漏看了一个空白项。这次作业再次提醒我审题的重要性。
总而言之,OO第一次作业中,我收获了许多,也取得了不错的成绩。希望能在第二单元再接再厉!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架