索引 概念原理
面试场景
1、谈谈你对数据库索引的理解
数据库索引其实就相当于字典上面的拼音目录,在进行大数据量查询时,是优化数据库性能的重要方法。
他可以快速定位到某个数据在哪一行,从而避免全文匹配,提高查询效率。
mysql索引的底层是采用B+TREE实现的,B+TREE是由 平衡二叉树 、 B树 过渡来的,
B+TREE的特点就是(为什么要采用B+TREE树呢?因为它有两个特点):
1)非叶子节点不存储数据,在叶子节点上存储数据,这样一个非叶子节点就能够存储更多的索引key,就能使树的度(degree)变大,I/O的效率变高
2)在叶子节点上面有指向相邻叶子节点的指针,这样就提高了范围查找的效率
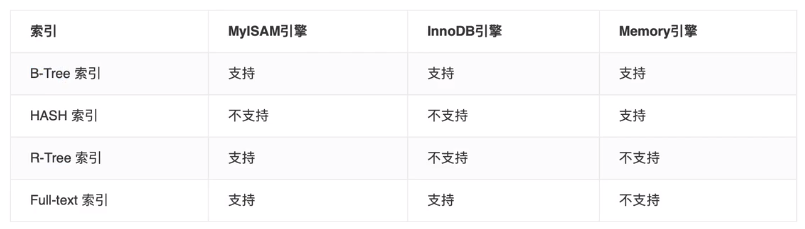
mysql索引主要用到的是MyISAM和InnoDB两种存储引擎,
这两种存储引擎的区别是(这两种存储引擎有很大区别):
1)MyISAM的数据和索引是分开存储的,有单独的两个文件,属于非聚簇索引;而InnoDB是放在同一个文件里面存储的,他的数据文件本身就是主键索引文件,属于聚簇索引;
2)两者都支持B+TREE,但是都不支持hash
3)MyISAM是非事务安全型的,而InnoDB是事务安全型的
4)MyISAM锁的粒度是表级,而InnoDB支持行级锁定。
应用场景:
1)MyISAM用来管理非事务表,他提供高速存储和检索,如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。
2)InnoDB是事务安全型的,具有很多特性,如果应用中需要执行大量的INSERT或UPDATE操作,就应该使用InnoDB,这样就可以提高多用户并发操作的性能。
索引的好处:
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
学习笔记
鲁班学院 https://www.bilibili.com/video/av37254744/?redirectFrom=h5
蚂蚁课堂 http://www.mayikt.com/course/video/2089
常用数据结构、算法动画演示 https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
1、hash数据结构
就是根据字段值计算出hash值,从而进行定位
优点:查询速度快
缺点:不支持范围查询
2、平衡二叉树搜索树
参考链接:https://blog.csdn.net/tanrui519521/article/details/80935348
这是由二叉搜索树过渡来的,二叉搜索树的概念:
1)若他的左子树不为空,则左子树上所有节点的值都小于根节点的值
2)若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
3)它的左右子树也分别是二叉搜索树
但是二叉搜索树会有极端的情况,就是左右高度差过大,如下图所示
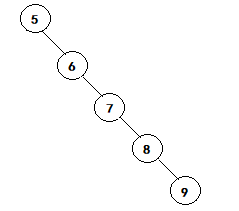
这棵树,说是树,其实它已经退化成链表了,但从概念上来看,它仍是一棵二叉搜索树,只要我们按照逐次增大,
如1、2、3、4、5、6的顺序构造一棵二叉搜索树,则形如上图。那么插入的时间复杂度就变成了O(n),
导致这种糟糕的情况原因是因为这棵树极其不平衡,右树的重量远大于左树,因此我们提出了叫平衡二叉搜索树的结构,
又称之为AVL树,是因为平衡二叉搜索树的发明者为Adel’son-Vel’skii 和Landis二人。
AVL树的性质:
1)左子树与右子树高度之差的绝对值不超过1
2)树的每个左子树和右子树都是AVL树
3)每一个节点都有一个平衡因子(balance factor),任一节点的平衡因子是-1、0、1(每一个节点的平衡因子 = 右子树高度 - 左子树高度)
做到了这点,这棵树看起来就比较平衡了,那么如何生成一棵AVL树呢?算法相对来说复杂,随着新节点的加入,树自动调整自身结构,达到新的平衡状态,这就是我们想要的AVL树。
当树不平衡时,我们需要做出旋转调整,有四种调整方法。
左单旋、右单旋、左右单旋、右左单旋
优点:可以支持范围查询
缺点:进行范围查询时,需要回旋,所以效率很低
3、B树
为了减少磁盘I/O次数,由平衡二叉搜索树过渡到了B树,
B树最大的特点就是一个非叶子节点上面可以放多个索引key(称为度),这样原来要搜四次,现在只要搜1次了;
4、B+树
在B树上面再做一层优化,形成了B+树,就是现在mysql使用的索引数据结构
B树只是一个根节点上可以同时存储多个元素,这样就减少了I/O操作
特点:
1)非叶子节点不存储数据,在叶子节点上存储数据,这样一个非叶子节点就能够存储更多的索引key,就能使树的度(degree)变大,I/O的效率变高
2)在叶子节点上面有指向相邻叶子节点的指针,这样就提高了范围查找的效率
备注
1)like模糊查询如果前面用了%,那是不会用到索引的
2)导致索引失效的条件
3)innodb是效率最高的,使用主键索引,不用辅助索引
4)B-Tree索引是B+树吗?
5)innodb的.ibd文件保存了数据和索引
=》Myisam的.MYD是保存的数据文件,.MYI保存的索引文件
6)索引属于存储引擎级别的概念,主要包括MyISAM、InnoDB、Memory引擎等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号