Java集合之HashMap(二)
前言
本篇文章是Map系列的第二篇(第一篇可参考Java集合之Map),主要内容为:HashMap 底层实现原理是什么?HashMap的一些实现细节以及JDK8对HashMap做了哪些优化?
正文
HashMap是如何实现的?
在JDK1.8之前,HashMap是以数组加链表的形式组成的:数组即用来存储值;链表即用来处理哈希冲突:具有同一hash值的元素都存储在同一个链表中。这样做的问题就是:当一个链表中的元素过多时,通过链表依次查找的效率较低。由于红黑树具有快速增删改查的特点,所以在JDK1.8中,HashMap新增了红黑树的组成结构:当链表长度超过8并且HashMap中数组的length超过64时,链表结构就会转换成红黑树结构,这样就大大减少了查找时间。JDK1.8中HashMap的组成结构如下图所示:
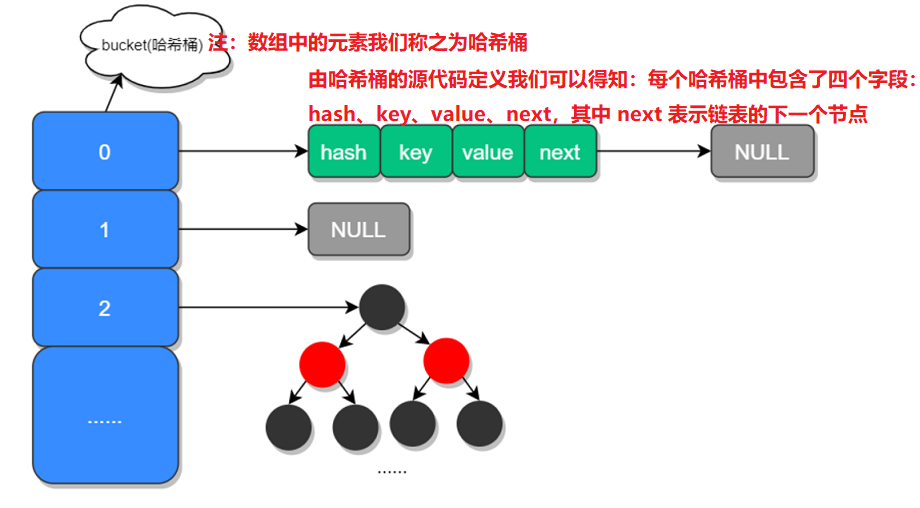
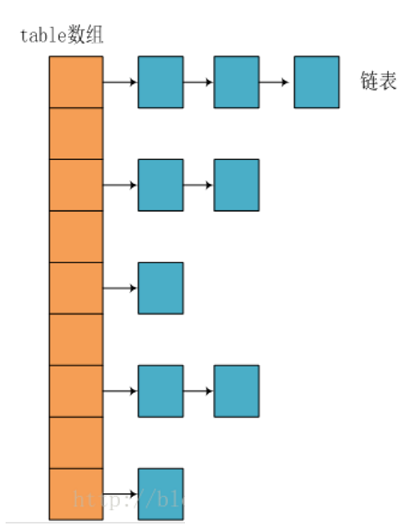
JDK1.8以前HashMap的组成结构如下图所示:
有关HashMap的一些细节
通过查看JDK1.8的HashMap源码,我们可以发现下面变量:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
我们需要注意的第一个细节就是:什么是负载系数?它的值为什么是0.75?
负载系数其实也叫扩容系数,它是用来判断何时进行扩容的。比如:假设负载系数是0.5,HashMap的初始容量是16,那么当HashMap中有16*0.5=8个元素时,HashMap就会进行扩容。这个系数之所以为0.75而不是其他数的原因其实就是容量和性能之间平衡的结果:当负载系数过大时,扩容发生的概率降低,占用的空间相对较小,但是发生哈希冲突的概率提高了;相反当负载系数过小时,发生哈希冲突的概率降低,但是扩容发生的概率提高了,占用的空间相对较多。
我们需要注意的第二个细节是HashMap中三个重要的方法:get()、put()和resize()。
对于HashMap的get()我们要注意:当发生哈希冲突(即hash值相同)时,会再判断key值是否相同。
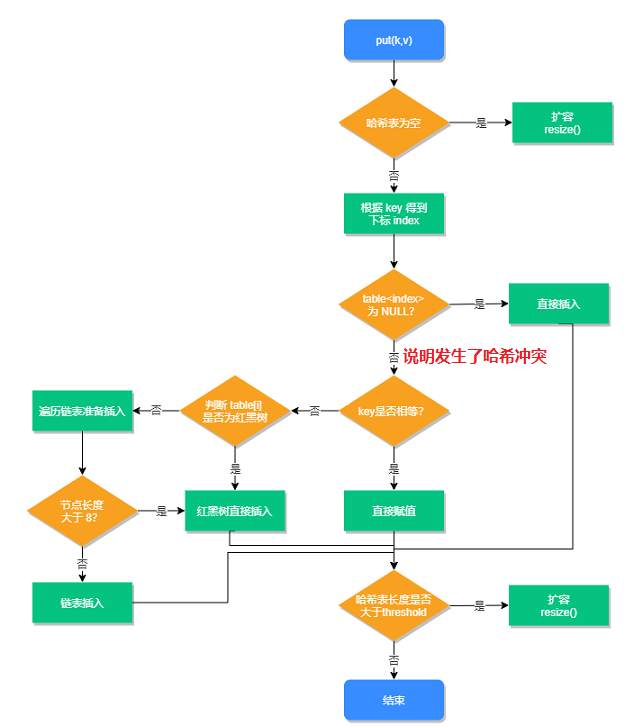
对于HashMap的put()我们要注意下图展示的该方法的执行流程:
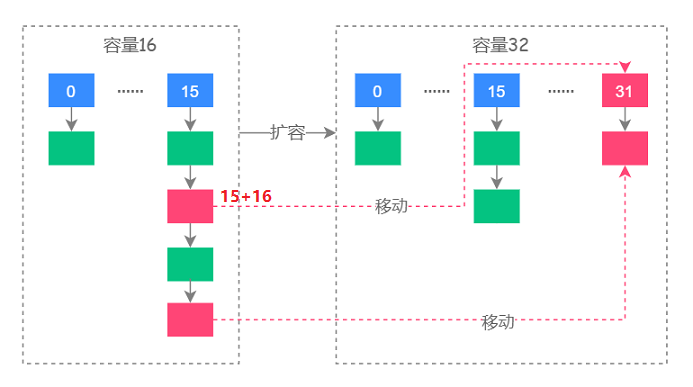
对于HashMap的resize()我们要注意:JDK1.7在扩容时是重新计算每个元素的哈希值;而JDK1.8在扩容时是通过位运算(源码为:e.hash & oldCap)来确定元素怎样移动:当得到的结果高一位为0时表示元素在扩容时位置不会发生任何变化;当得到的结果高一位为1时表示元素在扩容时位置发生了变化,新的位置等于原位置+原数组长度。如下图:
HashMap源码中的以下方法保证了哈希表的大小总是2的幂。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}

