|
实验内容与完成情况:
- 基本操作
代码(注释操作)
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder.appName("test_app").master("local[*]").getOrCreate()
# (1) 加载JSON数据并查询所有数据
df = spark.read.json("./data/employee.json")
df.show()
# (2) 查询所有数据,并去除重复的数据
df_distinct = df.dropDuplicates()
df_distinct.show()
# (3) 查询所有数据,打印时去除 id 字段
df_without_id = df.select("name", "age")
df_without_id.show()
# (4) 筛选出 age>30 的记录
df_filter_age = df.filter(df["age"] > 30)
df_filter_age.show()
# (5) 将数据按 age 分组
df_group_by_age = df.groupBy("age").count()
df_group_by_age.show()
# (6) 将数据按 name 升序排列
df_sort_by_name = df.sort("name")
df_sort_by_name.show()
# (7) 取出前 3 行数据
df_top3 = df.limit(3)
df_top3.show()
# (8) 查询所有记录的 name 列,并为其取别名为 username
df_username = df.withColumnRenamed("name", "username")
df_username.select("username").show()
# (9) 查询年龄 age 的平均值
avg_age = df.agg({"age": "avg"}).collect()[0][0]
print(f"Average Age: {avg_age}")
# (10) 查询年龄 age 的最小值
min_age = df.agg({"age": "min"}).collect()[0][0]
print(f"Minimum Age: {min_age}")
# 停止SparkSession
spark.stop()
运行结果:
+----+---+-----+
| age| id| name|
+----+---+-----+
| 36| 1| Ella|
| 29| 2| Bob|
| 29| 3| Jack|
| 28| 4| Jim|
| 28| 4| Jim|
|null| 5|Damon|
|null| 5|Damon|
+----+---+-----+
+----+---+-----+
| age| id| name|
+----+---+-----+
| 36| 1| Ella|
| 29| 3| Jack|
|null| 5|Damon|
| 29| 2| Bob|
| 28| 4| Jim|
+----+---+-----+
+-----+----+
| name| age|
+-----+----+
| Ella| 36|
| Bob| 29|
| Jack| 29|
| Jim| 28|
| Jim| 28|
|Damon|null|
|Damon|null|
+-----+----+
+---+---+-----+
|age| id| name|
+---+---+-----+
| 36| 1| Ella|
+---+---+-----+
+----+-----+
| age|count|
+----+-----+
| 29| 2|
|null| 2|
| 28| 2|
| 36| 1|
+----+-----+
+----+---+-----+
| age| id| name|
+----+---+-----+
| 36| 1| Ella|
| 29| 2| Bob|
|null| 5|Damon|
|null| 5|Damon|
| 29| 3| Jack|
| 28| 4| Jim|
| 28| 4| Jim|
+----+---+-----+
+---+---+-----+
|age| id| name|
+---+---+-----+
| 36| 1| Ella|
| 29| 2| Bob|
| 29| 3| Jack|
+---+---+-----+
+--------+
|username|
+--------+
| Ella|
| Bob|
| Jack|
| Jim|
| Jim|
| Damon|
| Damon|
+--------+
Average Age: 30.0
Minimum Age: 28
Process finished with exit code 0
- 编程实现将 RDD 转换为 DataFrame
代码:
from pyspark.sql import SparkSession
# 创建SparkSession
spark =
SparkSession.builder.appName("test_app").master("local[*]").getOrCreate()
# 2. RDD 转换为 DataFrame
rdd =
spark.sparkContext.textFile("./data/employee.txt")
df_from_rdd = rdd.map(lambda line: line.split(",")).map(lambda attributes: (int(attributes[0]),
attributes[1], int(attributes[2]))).toDF(["id", "name", "age"])
df_from_rdd.show(truncate=False)
# 停止SparkSession
spark.stop()
运行结果:
- 编程实现利用 DataFrame 读写 MySQL 的数据
总体代码:
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder.appName("test_app").master("local[*]").getOrCreate()
# 2. RDD 转换为 DataFrame
# rdd = spark.sparkContext.textFile("./data/employee.txt")
# df_from_rdd = rdd.map(lambda line: line.split(",")).map(lambda attributes: (int(attributes[0]), attributes[1], int(attributes[2]))).toDF(["id", "name", "age"])
# df_from_rdd.show(truncate=False)
# 3. 编程实现利用 DataFrame 读写 MySQL 的数据
# 插入数据到MySQL
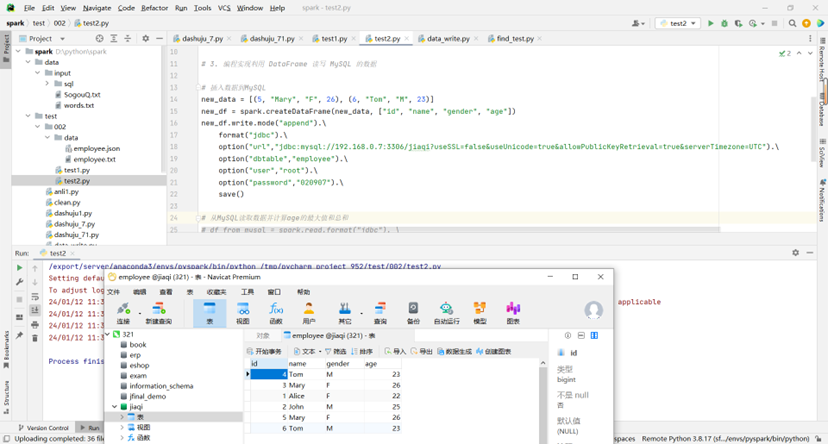
new_data = [(5, "Mary", "F", 26), (6, "Tom", "M", 23)]
new_df = spark.createDataFrame(new_data, ["id", "name", "gender", "age"])
new_df.write.mode("append").\
format("jdbc").\
option("url","jdbc:mysql://ip:3306/jiaqi?useSSL=false&useUnicode=true&allowPublicKeyRetrieval=true&serverTimezone=UTC").\
option("dbtable","employee").\
option("user","root").\
option("password","020907").\
save()
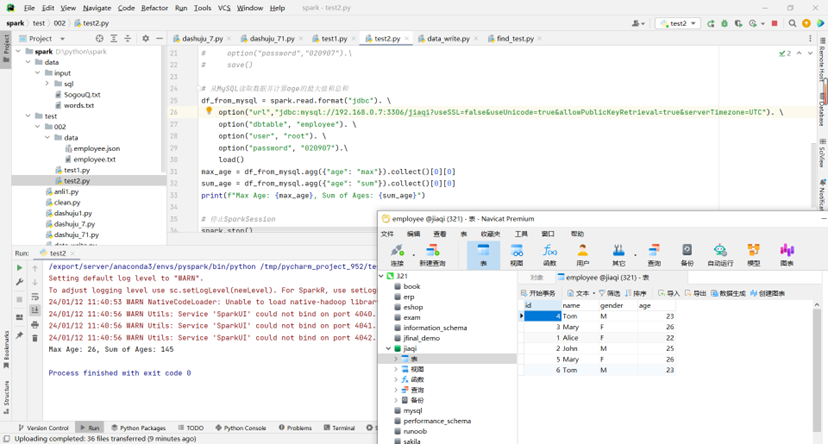
# 从MySQL读取数据并计算age的最大值和总和
df_from_mysql = spark.read.format("jdbc"). \
option("url","jdbc:mysql://ip:3306/jiaqi?useSSL=false&useUnicode=true&allowPublicKeyRetrieval=true&serverTimezone=UTC"). \
option("dbtable", "employee"). \
option("user", "root"). \
option("password", "020907").\
load()
max_age = df_from_mysql.agg({"age": "max"}).collect()[0][0]
sum_age = df_from_mysql.agg({"age": "sum"}).collect()[0][0]
print(f"Max Age: {max_age}, Sum of Ages: {sum_age}")
# 停止SparkSession
spark.stop()
运行结果:
写入:
读出并计算:
|


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通