每日总结
今天下的小雨,上了软件企业文化和大型数据库,完成了数据库的作业。
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt
创键文件
之后进入hive进行操作:
- create table docs(line string);
- load data inpath 'file:///usr/local/hadoop/input' overwrite into table docs;
- create table word_count as
- select word, count(1) as count from
- (select explode(split(line,' '))as word from docs) w
- group by word
- order by word;
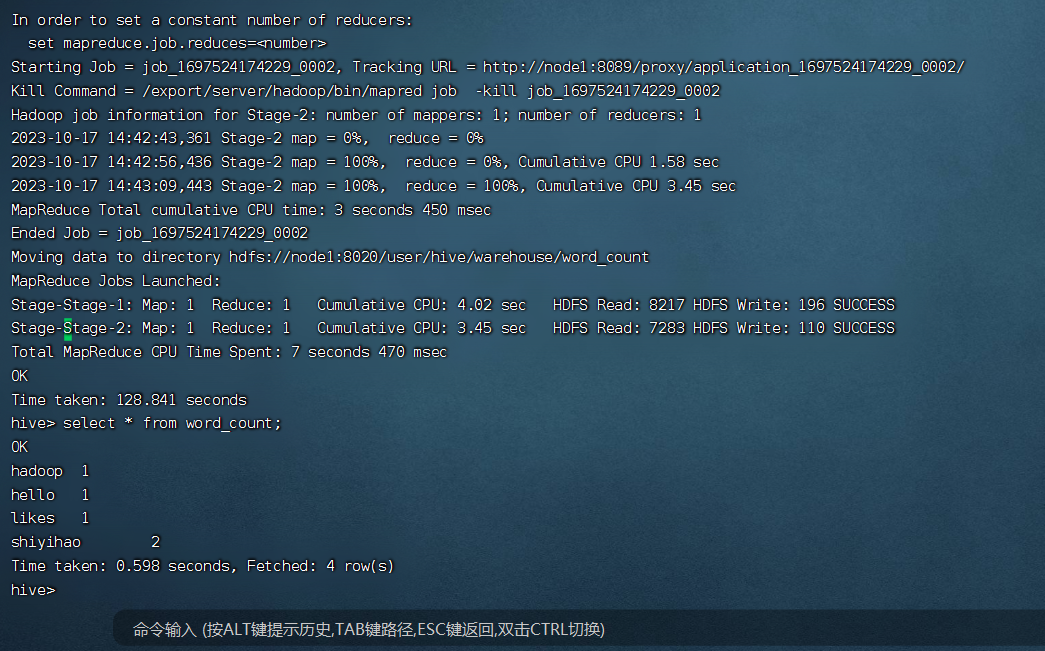
最后查询表word_count;
select * from word_count;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通