

python day2
目录:
1.模块初识
2.pyc是什么
5.列表的使用
6.元组
8.字符串常用操作
9.字典的使用
10.三级菜单实例
一.模块初识
模块也可以叫库,前面用的getpass就是一个模块。模块分两种,一种是标准模块,一种是第三方模块。
模块使用 import 模块名 来导入
备注:py文件名不能和import导入的模块名一样,切记
1.sys模块
1)path方法:
sys.path python的path环境变量
import sys print(sys.path)
执行结果:
"C:\Program Files\Python35\python.exe" "E:/py/py_cmr/day 2/sys_mod.py" ['E:\\py\\py_cmr\\day 2', 'E:\\py\\py_cmr', 'C:\\Program Files\\Python35\\python35.zip', 'C:\\Program Files\\Python35\\DLLs', 'C:\\Program Files\\Python35\\lib', 'C:\\Program Files\\Python35', 'C:\\Program Files\\Python35\\lib\\site-packages']
也就是说python在查找文件或者模块的时候默认从这些位置查找
C:\\Program Files\\Python35\\lib\\site-packages 这是python第三方模块的存放目录
C:\\Program Files\\Python35\\lib\\这是python标准模块的存放目录,大多数标准模块都在这目录下
import 模块
导入模块的时候,python默认在脚本所在路径下查找模块,找不到则在全局变量中查找
2)argv方法:(获取脚本的执行参数用的就是这个方法)
import sys print(sys.argv) #打印本文件相对路径,以及后面跟的参数,以列表的形式打印
执行结果:

取出其中的一个参数:
import sys print(sys.argv[2]) #打印列表中的第三个值,计算机计数是从0开始的
执行结果:

2.os模块
和操作系统交互的模块
system方法:python中执行操作系统的命令,并显示在屏幕上
dir:windows系统中列出目录文件
import os os.system("dir")
执行结果:
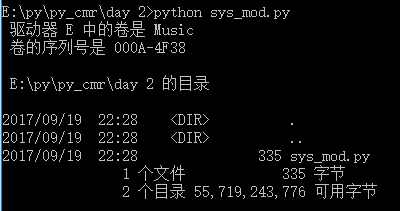
把os.systme("dir")的结果 直接赋值给变量是否可行?
import os dir = os.system("dir") print("--->",dir)
执行结果:
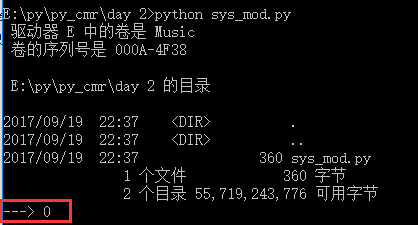
可以看出,变量打印出来的是0,这个其实是命令执行成功返回的0.
也就是说 os.system方法只执行命令,并显示在屏幕上,不会保存结果...
popen方法:可以执行命令,切保存结果在内存中
dir = os.popen("dir") print(dir)
执行结果:

可以看出,打印的其实是命令执行结果存放在内存中的一个地址
如果要想把结果读取打印出来,如何操作?
加上.read() 把结果读出来
dir = os.popen("dir").read() print(dir)
执行结果:

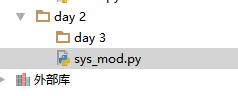
mkdir方法:在脚本当前路径下创建新目录
创建一个day 3 目录
import os os.mkdir("day 3")
执行结果:
二.pyc是什么
首先python和java一样也是一门基于虚拟机的语言,当我们执行py脚本的时候,其实是激活了python的解释器,告诉解释器要开始干活了,但是,在“解释”之前,其实执行的第一个工作是“编译”。可以这么描述,ptyhon是一门先编译后解释的语音。
当python程序运行时,编译的结果保存在内存中的PyCodeObject中,当python程序运行结束时,python解释器将PyCodeObject写回到pyc文件中。当python程序第二次运行时,首先会在硬盘中查找pyc文件,如果有,则比较pyc和py脚本的修改时间,如果py脚本时间更新,那么重新执行编译,如果时间一致,那么直接载入pyc文件。可以说pyc文件是PyCodeObject的持久化保存文件
三.数据类型初识
1.数字
int(整型)
66就是一个整型数字,在python2.x中 还有一个长整型(就是大一些的整型)。举个例子:2的32次方是整型,2的64次方就是长整型
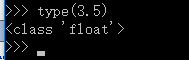
在python3.X中,取消了长整型,只有整型。如下图,在3.x中 2的65次方,数据类型是 int
type() 查看数据类型

float(浮点型)
浮点型可以简单的理解为小数的一种,知道就行,不用太深究。
complex(复数)
基本用不到。。。
2.布尔值
真(1,True)或假(0,False)
布尔值只有2个值
注:这里要区别0 不是 程序执行成功返回的0
3.字符串
四.bytes数据类型
在python3.x中 网络传输数据,必须是二进制bytes 所以需要转换成bytes
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr name = '呵呵哒' print(name) #utf-8编码成二进制字节bytes print(name.encode('utf-8')) #二进制解码成utf-8 print(b'\xe5\x91\xb5\xe5\x91\xb5\xe5\x93\x92'.decode('utf-8'))
五.列表的使用
列表的基本操作:
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr #列表 names = ["水银灯","C.C","真红","鲁鲁修",["呵呵","哈哈"]] #这是一个列表,列表中可以再放列表 print(names) print(names[2]) #取出位置为2 的 值 print(names[0:2]) #取出下标0至2 的值 注意:有个特性 顾首不顾尾,也就是0会取出来 但是 2不会取出来 print(names[-1]) #-1 表示取出列表最后一个值,最后一个值是列表,所以取出的也是列表 print(names[-1][0]) #取出最后一个值 是列表,取出这个列表第一个值 print(names[-3:-1]) #取出最后3个值 因为列表取数是从左向右的 所以-3:-1 又因为顾首不顾尾的特性 所以-1这个最后值没有打出来 print(names[-3:]) #取出最后3个值,:后面不填,就会答应出最后一个值 names.append("柯南") #末尾追加一个值 print(names) names.insert(1,"柯南") #在1这个位置 插入一个值 print(names) names[2] = "哈哈" #修改位置为2的值 names.remove("真红") #删除 真红 print(names) print("柯南的位置",names.index("柯南")) #查找柯南的位置,如果有多个,只能查出第一个的位置 print("柯南的数量",names.count("柯南")) #统计 有几个 “柯南” names.pop() #pop 如果不指定位置 默认删除最后一个 print(names) names.pop(0) #删除第一个 从0开始数 print(names) del names[2] #删除的另一种写法 删除第二个 print(names) names2 = [1,2,3,4,5,6] names.extend(names2) #扩展,把names2的列表的值 扩展到names列表中 print(names) names3 = names.copy() #复制names的值 赋值给names3 print(names3) names.clear() #清空列表 print(names) del names #删除列表
执行结果:

列表的复制
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr names = ["水银灯","C.C","真红","鲁鲁修",["呵呵","哈哈"]] names2 = names.copy() print(names) print(names2) #修改names的值,names2的值兵不变 names[2] = "蔷薇" print(names) print(names2) #如果修改names中列表的第一个值 那么这个修改是names2是生效的 #这里的copy是一个浅copy 只copy一层,列表中的 列表[1,2]的值是第二层 并不会被copy 因为浅copy只复制了这个列表的内存地址, # 只能能找到这个列表,但是其中的值没有被复制 所以names2也生效 names[-1][0] = 1 print(names) print(names2) print("------------------------------------------") #深copy 能够复制列表中的列表的值 import copy names3 = ["水银灯","C.C","真红","鲁鲁修",["呵呵","哈哈"]] names4 = copy.deepcopy(names3) #深copy 可以完全复制,包括其中列表的值 print(names) print(names4) names[-1][0] = 1 print(names) print(names4)
执行结果

六.元组
元组就是不能改变的列表
元组只有2个方法 count 和 index
元组使用()括起来 list=('a','b','c')
七.购物车程序练习

#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr shopping_cart = [] goods = [ ('iphone',8888), ('xioami TV',3999), ('computer',4999), ('宝马轿车',888888) ] print("--------欢迎来到购物广场!!!--------") balance = input("请输入您的工资:") if balance.isdigit(): #isdiget 判断是否是数字, balance = int(balance) while True: print("商品列表如下:"," ","余额:\033[32;1m%s\033[0m"%(balance)) #\033[32;1m内容\033[0m 颜色代码 print("---------------------------------") for item in goods: print(goods.index(item),item) #打印商品列表 user_choice = input("请输入你要购买的商品编号(q退出):") if user_choice.isdigit(): user_choice = int(user_choice) if user_choice < len(goods) and user_choice >=0: #len()获取列表的长度 判断选择的数字是否超出列表范围 buy_item = goods[user_choice] if buy_item[1] <= balance: #买的起 balance = balance - buy_item[1] #扣钱 shopping_cart.append(buy_item) #添加购物车 print("添加【%s】至购物车中,您的当前余额:\033[31;1m%s\033[0m" %(buy_item[0],balance)) else: #买不起 print("余额不足...") else: print("商品不存在!") elif user_choice == 'q': print("----------您购买了如下产品--------------") for p in shopping_cart: print(p) print("您的余额:%s"%(balance)) exit() else: print("商品不存在!")
八.字符串常用操作
name = 'Alex Li'
name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 '---------------------Alex Li----------------------' name.count('lex') 统计 lex出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格 name.find('A') 查找A,找到返回其索引, 找不到返回-1
print(name[name.find('e'):]) 类似于列表的切片,通过查找A的索引位置,从这个位置开始取值到字符串的最后一个字符 输出:ex Li format : >>> msg = "my name is {}, and age is {}" >>> msg.format("alex",22) 'my name is alex, and age is 22' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("alex",22) 'my name is 22, and age is alex' >>> msg = "my name is {name}, and age is {age}" >>> msg.format(age=22,name="ale") 'my name is ale, and age is 22' format_map >>> msg.format_map({'name':'alex','age':22}) 'my name is alex, and age is 22' msg.index('a') 返回a所在字符串的索引 '9aA'.isalnum() True '9'.isdigit() 是否整数 name.isnumeric name.isprintable name.isspace name.istitle name.isupper "|".join(['alex','jack','rain']) 'alex|jack|rain' maketrans >>> intab = "aeiou" #This is the string having actual characters. >>> outtab = "12345" #This is the string having corresponding mapping character >>> trantab = str.maketrans(intab, outtab) >>> >>> str = "this is string example....wow!!!" >>> str.translate(trantab) 'th3s 3s str3ng 2x1mpl2....w4w!!!' msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') >>> "alex li, chinese name is lijie".replace("li","LI",1) 'alex LI, chinese name is lijie' msg.swapcase 大小写互换 >>> msg.zfill(40) '00000my name is {name}, and age is {age}' >>> n4.ljust(40,"-") 'Hello 2orld-----------------------------' >>> n4.rjust(40,"-") '-----------------------------Hello 2orld' >>> b="ddefdsdff_哈哈" >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 True
九.字典的使用
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr #字典的格式 key:value #字典是无序存放的 classes = { 'no_1':'苍井空', 'no_2':'小泽玛利亚', 'no_3':'饭岛爱', } #查看 print(classes['no_3']) #这种方法 如果key不存在 就会报错 print(classes.get('no_5')) #这种方法,如果key不存在,返回none ,建议使用这种方法 print(classes.keys()) #把字典中的key全部打印出来 print(classes.values()) #把字典中的value全部打印出来 print(classes.setdefault('no_3','tokyo-hot')) #kye存在value 则使用那个value,不存在,则创建一个新的,且value是tokyo-hot print(classes.items()) #把字典变成列表打印 #增加和修改 classes['no_4'] = '泷泽萝拉' # 存在同个key 则替换 ,不存在则新增 print(classes) classes['no_3'] = '泷泽萝拉' # 存在同个key 则替换 ,不存在则新增 print(classes) #删除的两种姿势 del classes['no_1'] classes.pop('no_2') print(classes) #循环 for i in classes: print(i,classes[i])
字典的嵌套
av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } } av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" print(av_catalog["大陆"]["1024"])
#输出结果 '全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
10.三级菜单实例
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:cmr data = { '福建':{ '福州':{ '鼓楼':['软件园','体育中心'], '台江':['万达','红星美凯龙'], '仓山':['万达','爱琴海'] }, '厦门':'呵呵哒', '泉州':'呵呵哒', }, '江西':'呵呵哒', '广东':'呵呵哒', } exit_flag = False #定义一个退出的标识 while not exit_flag: #not false 就是true for i in data: print(i) #打印省的名单 choice = input("选择进入(省),q 退出:") #输入一个省的名字 进入下一层 if choice in data: #判断输入的省名字 是否在字典中 while not exit_flag: for ii in data[choice]: print(">>>",ii) choice2 = input("选择进入(市),b 返回,q 退出:") if choice2 in data[choice]: while not exit_flag: for iii in data[choice][choice2]: print('>>>>>>',iii) choice3 = input("选择进入(区),b 返回,q 退出:") if choice3 in data[choice][choice2]: while not exit_flag: for company in data[choice][choice2][choice3]: print(company) choice4 = input("当前是最后一层,输入b 返回,q 退出:") if choice4 == 'b': #输入b 跳出当前区的循环 进入市的循环 break elif choice4 == 'q': #输入q exit_flag=True 那么while not exit_flag = False 每一级的while循环条件都不成立 退出当前循环,直到退出整个循环,最后退出程序 exit_flag = True elif choice3 == 'b': break elif choice3 == 'q': exit_flag = True elif choice2 == 'b': break elif choice2 == 'q': exit_flag = True elif choice == 'q': exit_flag = True
