


DOM4j 和 XPATH
- DOM 文档对象模型(Document Object Model),是W3C组织推荐的处理可扩展置标语言的标准编程接口,通过DOM树来读取所有元素
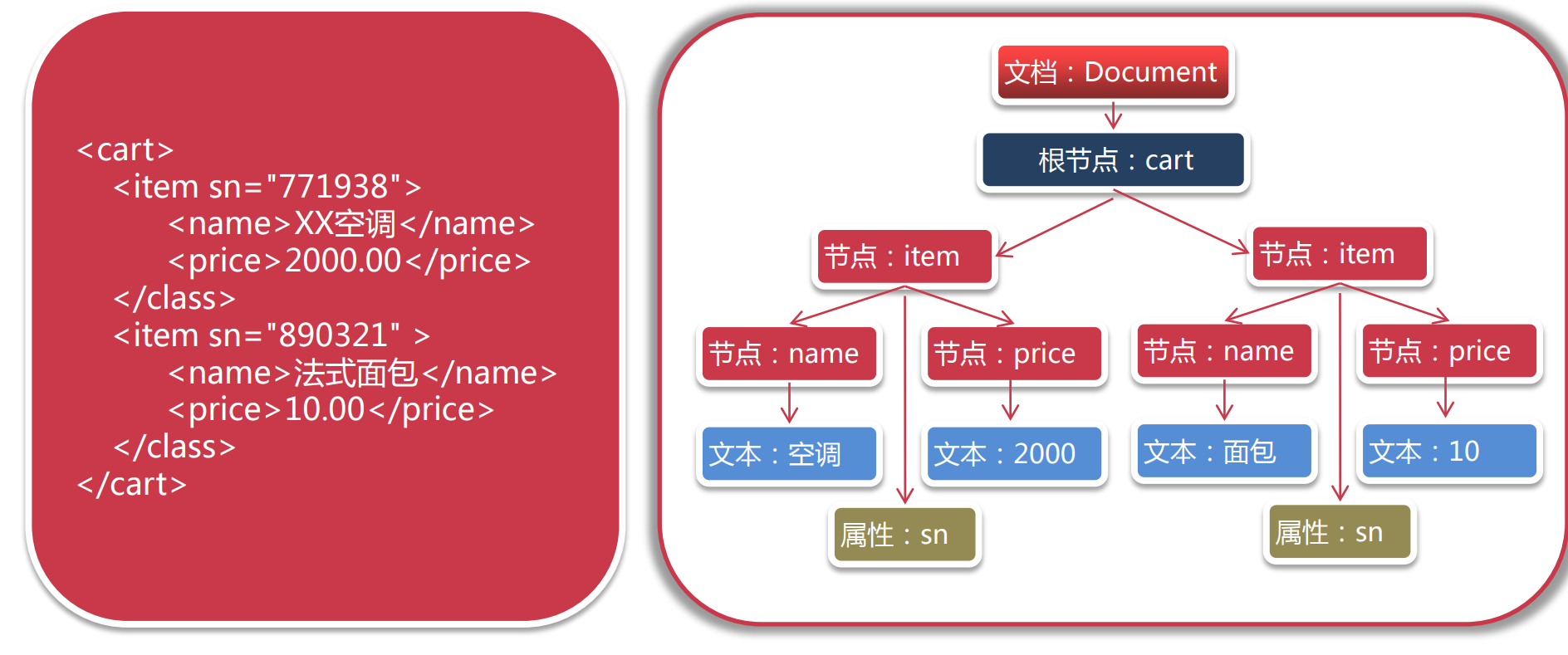
- Dom4j 开源XML解析包,应用于java平台 jar包下载地址:https://dom4j.github.io/
1. Dom4j 遍历 XML
import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class HrReader { public void readXml(){ String file = "d:/workspace/xml/src/hr.xml"; //SAXReader类是读取XML文件的核心类,用于将XML解析后以“树”的形式保存在内存中。 SAXReader reader = new SAXReader(); try { Document document = reader.read(file); //获取XML文档的根节点,即hr标签 Element root = document.getRootElement(); //elements方法用于获取指定的标签集合 List<Element> employees = root.elements("employee"); for(Element employee : employees){ //element方法用于获取唯一的子节点对象 Element name = employee.element("name"); String empName = name.getText();//getText()方法用于获取标签文本 System.out.println(empName); System.out.println(employee.elementText("age")); System.out.println(employee.elementText("salary")); Element department = employee.element("department"); System.out.println(department.element("dname").getText()); System.out.println(department.element("address").getText()); Attribute att = employee.attribute("no"); System.out.println(att.getText()); } } catch (DocumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { HrReader reader = new HrReader(); reader.readXml(); } }
2. Dom4j 更新 XML
import java.io.FileOutputStream; import java.io.OutputStreamWriter; import java.io.Writer; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class HrWriter { public void writeXml(){ String file = "d:/workspace/xml/src/hr.xml"; SAXReader reader = new SAXReader(); try { Document document = reader.read(file); Element root = document.getRootElement(); Element employee = root.addElement("employee"); employee.addAttribute("no", "3311"); Element name = employee.addElement("name"); name.setText("李铁柱"); employee.addElement("age").setText("37"); employee.addElement("salary").setText("3600"); Element department = employee.addElement("department"); department.addElement("dname").setText("人事部"); department.addElement("address").setText("XX大厦-B105"); Writer writer = new OutputStreamWriter(new FileOutputStream(file) , "UTF-8"); document.write(writer); writer.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { HrWriter hrWriter = new HrWriter(); hrWriter.writeXml(); } }
3.XPATH 路径表达式 XML中的查询语言
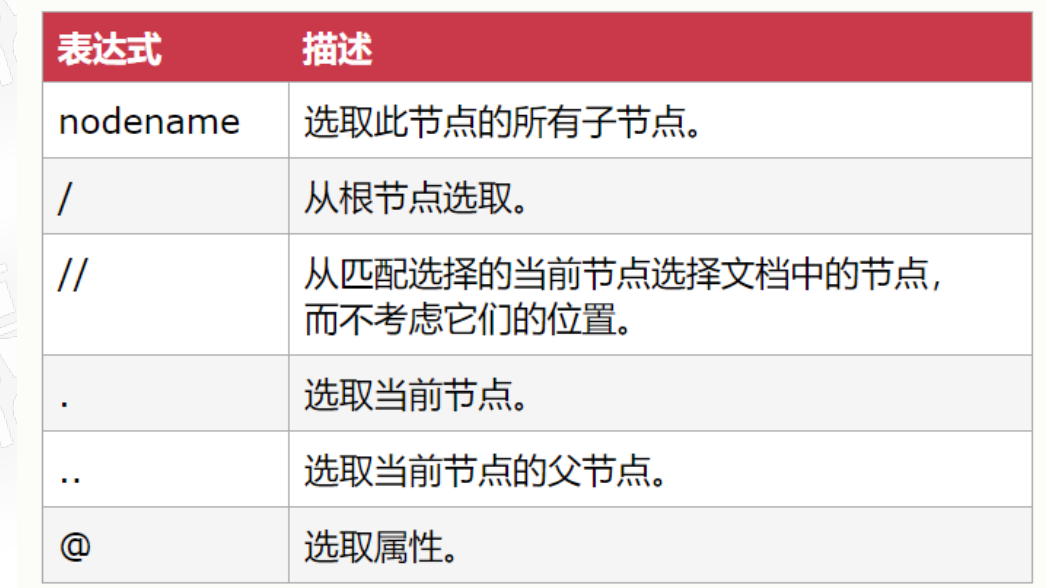

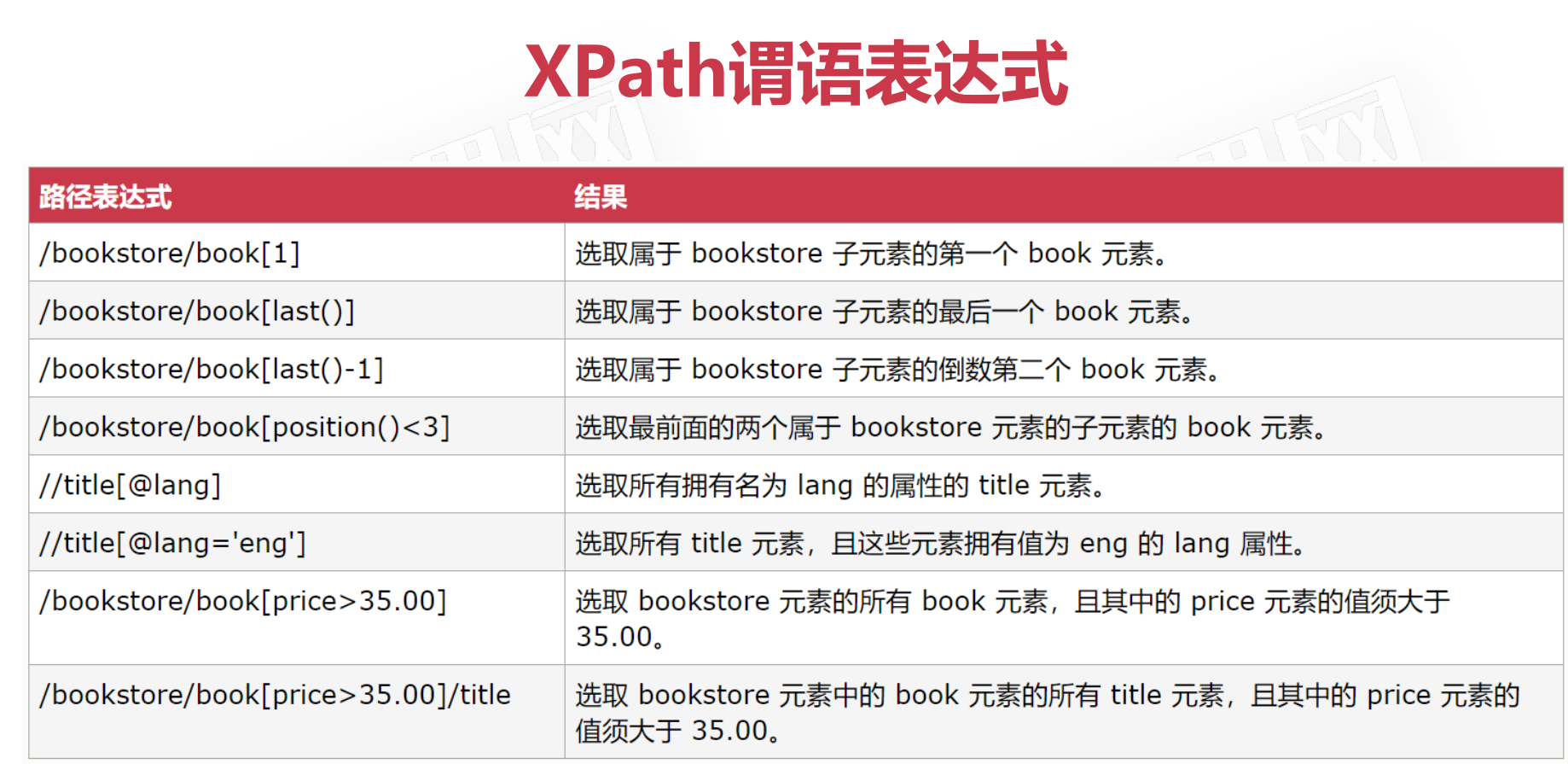
4.jaxen java编写的开源XPATH库 jar包下载地址:https://maven.aliyun.com/mvn/search 搜索jaxen 即可 加入项目中
import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; public class XPathTestor { public void xpath(String xpathExp){ String file = "E:/lianxi/xml/hr.xml"; SAXReader reader = new SAXReader(); try { Document document = reader.read(file); //用来执行XPATH表达式的,Node就是Element和attribute的父类 List<Node> nodes = document.selectNodes(xpathExp); for(Node node : nodes){ Element emp = (Element)node; System.out.println(emp.attributeValue("no")); System.out.println(emp.elementText("name")); System.out.println(emp.elementText("age")); System.out.println(emp.elementText("salary")); System.out.println("=============================="); } } catch (DocumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { XPathTestor testor = new XPathTestor(); // testor.xpath("/hr/employee"); // testor.xpath("//employee"); // testor.xpath("//employee[salary<4000]"); // testor.xpath("//employee[name='李铁柱']"); // testor.xpath("//employee[@no=3304]"); // testor.xpath("//employee[1]"); // testor.xpath("//employee[last()]"); // testor.xpath("//employee[position()<3]"); //提取第三名和第八名员工的信息 testor.xpath("//employee[3] | //employee[8]"); } }
前篇:XML简单知识

