
概念区分
性能度量vs损失函数
损失函数、代价函数与目标函数
损失函数(Loss Function):是定义在单个样本上的,是指一个样本的误差,度量模型一次预测的好坏。
代价函数(Cost Function)=成本函数=经验风险:是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均,度量平均意义下模型预测的好坏。
目标函数(Object Function)=结构风险=经验风险+正则化项=代价函数+正则化项:是指最终需要优化的函数,一般指的是结构风险。
正则化项(regularizer)=惩罚项(penalty term)。
损失函数vs风险函数
损失函数度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
风险函数分为两种,不考虑正则项的是经验风险(Empirical Risk),考虑过拟合问题,加上正则项的是结构风险(Structural Risk)。
一、损失函数
(一)回归损失函数
1.损失函数
(1)平方损失函数(quadratic loss function)
是MSE的单个样本损失,又叫平方损失(squared loss)
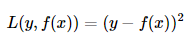
是指预测值与实际值差的平方。
有时候为了求导方便,在前面乘上一个1/2。
(2)绝对(值)损失函数(absolute loss function)
是MAE单个样本损失,又叫绝对误差(absolute Loss)
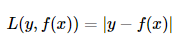
(3)对数损失函数(logarithmic loss function)
又称,对数似然损失函数(loglikelihood loss function)。
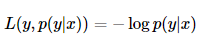
这个损失函数就比较难理解了。事实上,该损失函数用到了极大似然估计的思想。
P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失应该越小,前面加了一个负号是因为log函数是单调递增的,在前面加上负号之后,最大化p(y|x)就等价于最小化L。因此再加个负号取个反。
下面说两点:
第一点就是对数损失函数非常常用。logistic回归,softmax回归等都用的是这个损失。
第二点就是对于这个公式的理解。这个公式的意思是在样本x在分类为y的情况下,我们需要让概率p(y|x)达到最大值。就是利用目前已知的样本分布,找到最有可能导致这种分布的参数值。
(4)Huber损失 (huber loss)
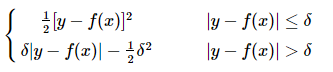
2.各自优缺点
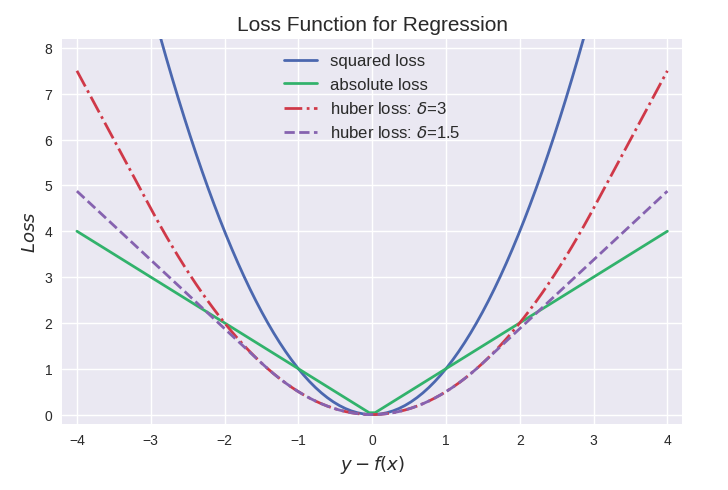
其中最常用的是平方损失,然而其缺点是对于异常点会施以较大的惩罚,因而不够robust。
如果有较多异常点,则绝对值损失表现较好,但绝对值损失的缺点是在f(x)=0处不连续可导,因而不容易优化。
Huber损失是对二者的综合,当|y-f(x)|小于一个事先指定的值δ时,变为平方损失,大于δ时,则变成类似于绝对值损失,因此也是比较robust的损失函数。
<br>
三者的图形比较如下:
(二)分类损失函数
1.损失函数
(1)0-1损失函数(0-1 loss function)
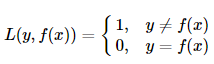
也就是说,当预测错误时,损失函数为1,当预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度。只要错误,就是1。
0-1损失不连续、非凸,优化困难,因而常使用其他的代理损失函数进行优化。
(2)Logistic loss(对数似然)
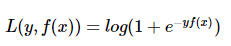
logistic Loss为Logistic Regression中使用的损失函数。
证明:https://www.cnblogs.com/massquantity/p/8964029.html
(3)铰链损失(Hinge loss)
Hinge loss一般分类算法中的损失函数,尤其是SVM。

hinge loss为svm中使用的损失函数,hinge loss使得yf(x)>1的样本损失皆为0,由此带来了稀疏解,使得svm仅通过少量的支持向量就能确定最终超平面。
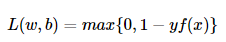
Hinge loss一般分类算法中的损失函数,尤其是SVM。 其中 y=+1或y=−1,f(x)=wx+b,当为SVM的线性核时。
推导:https://www.cnblogs.com/massquantity/p/8964029.html
https://www.its203.com/article/qq_37960402/96140306
(4)指数损失(Exponential loss)
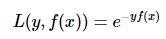
exponential loss为AdaBoost中使用的损失函数,使用exponential loss能比较方便地利用加法模型推导出AdaBoost算法 (具体推导过程)。
然而其和squared loss一样,对异常点敏感,不够robust。
(5)modified Huber loss
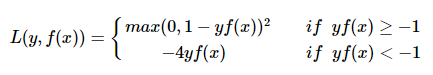
modified huber loss结合了hinge loss和logistic loss的优点,既能在yf(x)>1时产生稀疏解提高训练效率,又能进行概率估计。
另外其对于(yf(x)<−1)样本的惩罚以线性增加,这意味着受异常点的干扰较少,比较robust。scikit-learn中的[SGDClassifier](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html)同样实现了modified huber loss。
2.各自优缺点
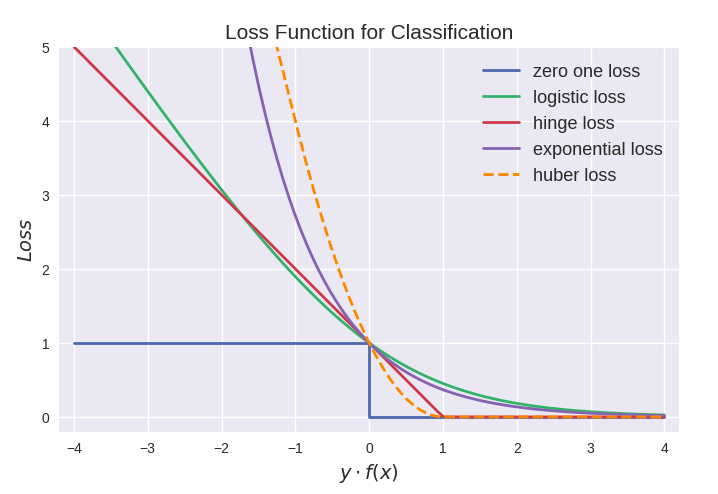
从上图可以看出上面这些损失函数都可以看作是0-1损失的单调连续近似函数,而因为这些损失函数通常是凸的连续函数,因此常用来代替0-1损失进行优化。
它们的相同点是都随着margin→−∞而加大惩罚;不同点在于,logistic loss和hinge loss都是线性增长,而exponential loss是以指数增长。
值得注意的是上图中modified huber loss的走向和exponential loss差不多,并不能看出其robust的属性。其实这和算法时间复杂度一样,成倍放大了之后才能体现出巨大差异:
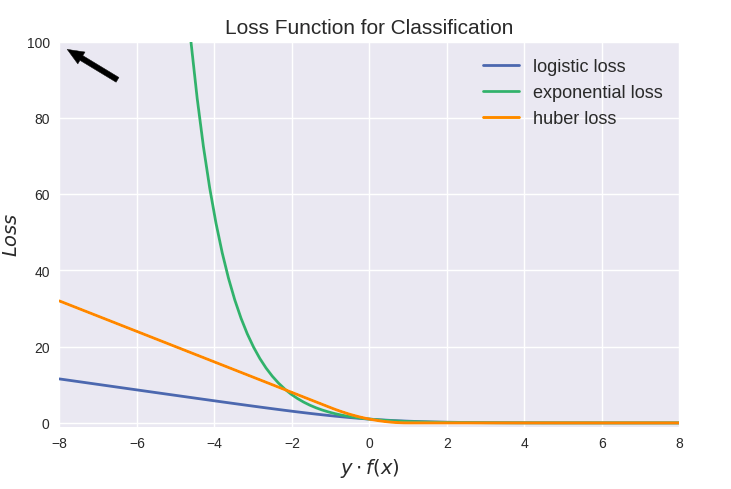
二、代价函数
(一)回归问题常用代价函数
1.均方差损失 Mean Squared Error Loss( L2 Loss)
均方差 Mean Squared Error (MSE) 损失是机器学习、深度学习回归任务中最常用的一种损失函数,也称为 L2 Loss,又叫最小平方误差、最小均方误差、平方损失(square loss)。
(1)公式

(2)高斯分布:MSE损 == 最大似然估计

2.平均绝对误差损失 Mean Absolute Error Loss(L1 Loss)
平均绝对误差 Mean Absolute Error (MAE) 是另一类常用的损失函数,也称为 L1 Loss,又叫最小绝对值偏差(LAE)。
(1)公式
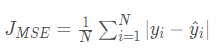
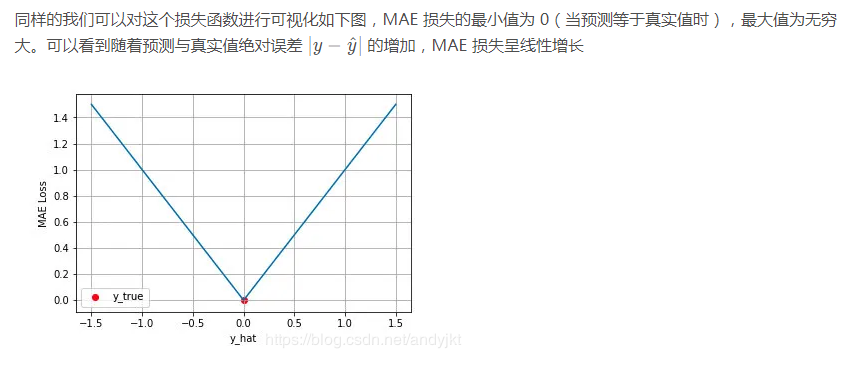
(2)MAE(L1)和 MSE(L2)作为损失函数的主要区别:
L2损失相比L1通常可以更快地收敛。
L1损失对于 outlier 更加健壮,即更加不易受到 outlier 影响。L2损失函数对异常点比较敏感,因为L2将误差平方化,使得异常点的误差过大,模型需要大幅度的调整,这样会牺牲很多正常的样本。
而L1损失函数由于导数不连续,可能存在多个解,当数据集有一个微笑的变化,解可能会有一个很大的跳动,L1的解不稳定。
(3)拉普拉斯分布:MAE损失 == 负对数似然

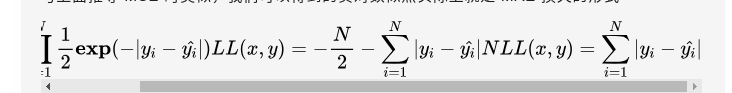
3.Huber Loss
Huber Loss 是一种将 MSE 与 MAE 结合起来,取两者优点的损失函数,也被称作 Smooth Mean Absolute Error Loss 。
其原理很简单,就是在误差接近 0 时使用 MSE,误差较大时使用 MAE。
(1)公式
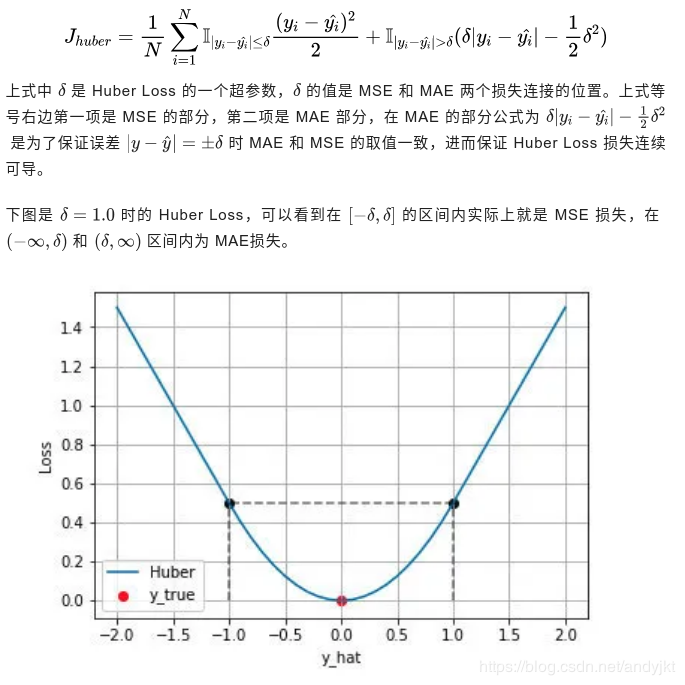
(2)Huber Loss 的特点
Huber Loss 结合了 MSE 和 MAE 损失,在误差接近 0 时使用 MSE,使损失函数可导并且梯度更加稳定;在误差较大时使用 MAE 可以降低 outlier 的影响,使训练对 outlier 更加健壮。缺点是需要额外地设置一个 \delta超参数。
(二)分类问题常用的代价函数
1.交叉熵损失函数 Cross Entropy Loss。
(1)二分类
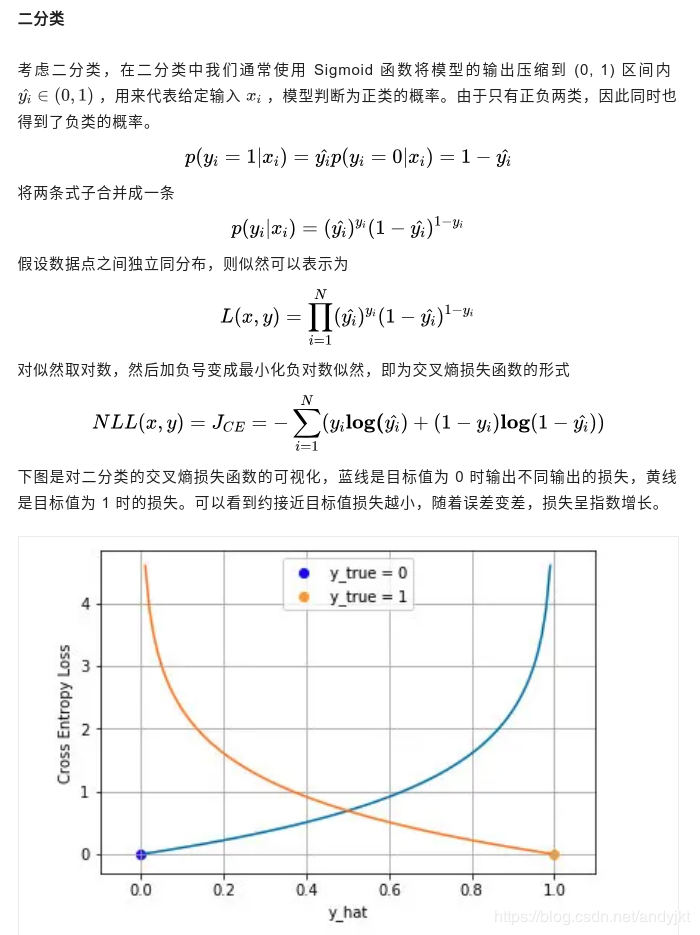
(2)多分类

(3)为什么用交叉熵损失

2.合页损失 Hinge Loss(用于SVM)
(1)公式
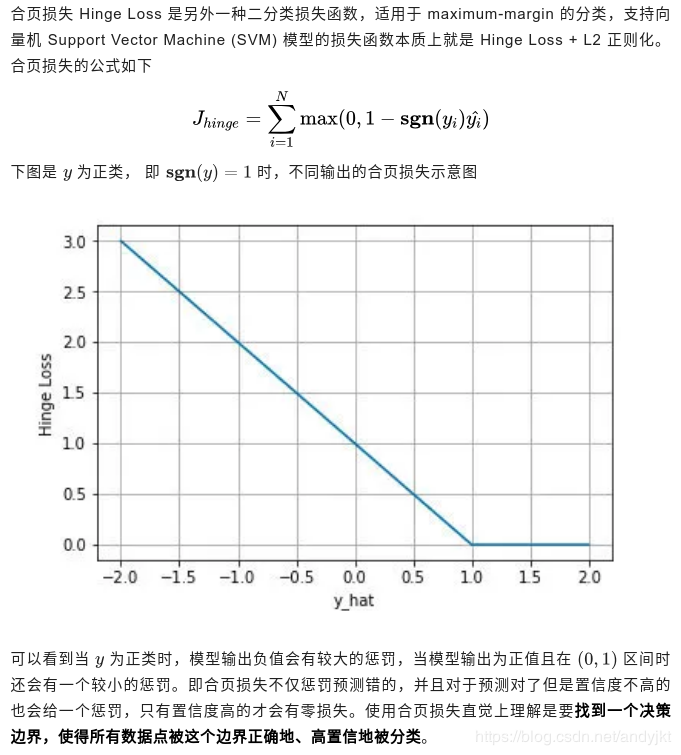
参考:
https://www.cnblogs.com/lliuye/p/9549881.html
https://blog.csdn.net/andyjkt/article/details/107599424
https://blog.csdn.net/Tianlock/article/details/88232467
https://www.cnblogs.com/massquantity/p/8964029.html
更多损失函数:https://blog.csdn.net/qq_14845119/article/details/80787753【未整理】
作者:西伯尔
出处:http://www.cnblogs.com/sybil-hxl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

