

原Linux实验网址:http://dblab.xmu.edu.cn/blog/1757-2/
实验一: spark的基础使用
1.数据载入部分
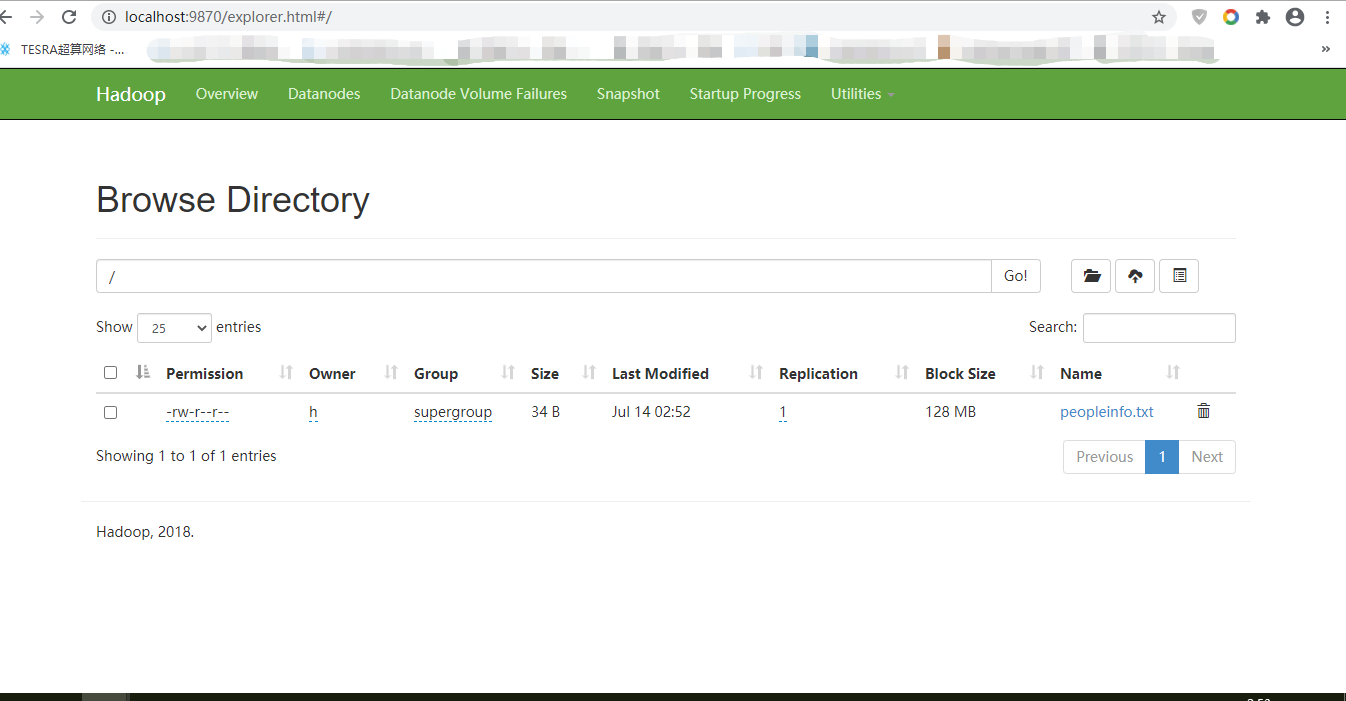
在本地 (可以是虚拟机,也可以是真实操作系统,需要在包含spark-hadoop的环境下) 创建一个文本peopleinfo.txt
1 F 170
2 M 178
3 M 174
4 F 165
将该文件上传到hadoop的文件系统hdfs中
sklsde@ubuntu:~$ hdfs dfs -put peopleinfo.txt /【Linux命令】
hdfs dfs -put D:\Spark\peopleinfo.txt /【win10命令,指定文件位置】
[请在此处贴出你的结果]
2.数据计算部分
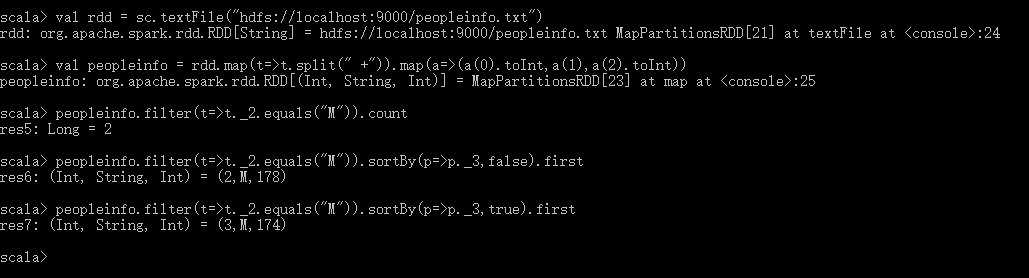
编写Spark应用程序,该程序对HDFS文件中的数据文件peopleinfo.txt进行统计,计算得到:
- 男性总数
- 女性总数
- 男性最高身高
- 女性最高身高
- 男性最低身高
- 女性最低身高。
spark可以使用 spark-submit 或者 spark-shell 两种方式访问。
[请仿照上面的例子计算女性的对等信息,并在此处贴出你的例子]
spark-shell的访问:
实验二: spark-submit 的使用
在 ${SPARK-HOME}/examples/jars 目录下有一个打包好的 jar, 使用 spark-commit命令将该jar提交给spark-master,任务将被自动运行,这也是spark在大多数情况下的使用方式.
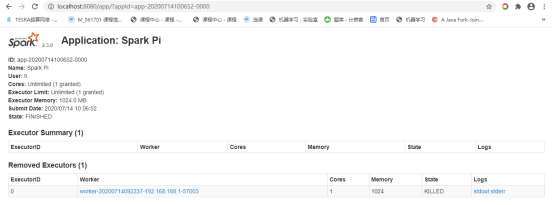
运行如下类似命令:【要在spark-2.3.0-bin-hadoop2.6\examples目录下运行,否则报错java.lang.ClassNotFoundException: org.apache.spark.examples.SparkPi】
spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.188.1:7077 spark-examples_2.11-2.3.0.jar【Linux和win10一样】
[运行完如上之后,spark master ui会出现变化,一般来说会出现一个 Spark Pi 的 Completed Applications 点开他,在这里展示其所展示的内容]
实验三: 统计微博信息
在本地创建一个文件 weiboinfo.txt,并将它上传到 hdfs 中
11111111 12743457
11111111 16386587
11111111 19764388
11111111 12364375
11111111 13426275
11111111 12356363
11111111 13256236
11111111 10000032
11111111 10000001
11111111 10000001
11111111 10000001
11111112 12743457
其中,第1列和第2列都是表示用户ID,表中的数据是表示第1列的用户关注了第2列用户
本实验需要完成下列任务:
- (1) 请统计出一共有多少个不同的ID
- (2) 统计出一共有多少个不同的(ID,ID)对
- (3) 统计出每个用户的粉丝数量
- (1) 统计出每个用户的粉丝数量,并且把统计结果写入到HDFS文件follows.txt中
创建一个工作目录,在其中创建一个 build.sbt
name := "spark weibo project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0"
在原地执行命令: sbt
在工作环境下创建源码文件 /src/main/scala/SparkWeibo.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object SparkWeibo{
def main(args:Array[String]){
val conf = new SparkConf().setAppName("Weibo info")
val sc = new SparkContext(conf)
val records = sc.textFile("hdfs://192.168.154.129:9999/weibo.txt")
records.collect().foreach(println)
/**
* 剩余部分请使用自己的逻辑完成本实验的四个任务
*/
}
}
[可以用命令行输出print的方式一起完成任务(1)(2)(3),贴图关键部分]
[展示 hdfs webui 中存在用户粉丝数文件 /follows.txt ]
[通过命令行,调用hdfs中的一个命令将follows.txt拉回本地,并展示其内容]
类似
问答区:
1.同样是执行spark程序,为什么只有`spark-submit --master...`显示在了spark master ui 中,而run-example或者spark-shell却都没有显示在其中呢?
2.写出本实验从头到尾使用到的rdd算子
3.除了本实验中使用过的rdd算子,请在列举3-5个其他的rdd算子,并解释其功能和含义
作者:西伯尔
出处:http://www.cnblogs.com/sybil-hxl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
