

导论
自然语言处理,NLP,接下来的几篇博客将从四方面来展开:
(六)Expectation-Maximization
(七)Machine Translation
(五)Seq2seq/Transformer/BERT
一、Seq2seq
二、Transformer
1.Attention机制
(1)
attention可以知道大概内容,需要更详细内容时候,去Decoder找。
attention可以认为是一种Soft对齐。
(2)缺点
顺序依赖,无法并行,速度慢;
单向信息流。编码一个词的时候,需要看前后。
普通attention需要外部“驱动”,来做内容提取。
2.Self-attention
(1)
Self-attention的特色:天涯若比邻。所有单词无论远近都是一样的。
①自驱动,编码第t个词,用当前状态驱动。
②Self-attention和全连接网络FNN区别
Self-attention每一个输出需要全部输入,而FNN不需要全部输入,只要有a1就可以计算b1,不需要a2。
③Self-attention与普通attention对比
可以认为普通attention是Self-attention的一种特例。
普通attention中,query是decoder的隐状态。key和value是encoder的输出。
Self-attention中,query、key和value都是来自当前的向量,都是通过变换矩阵来学习的。
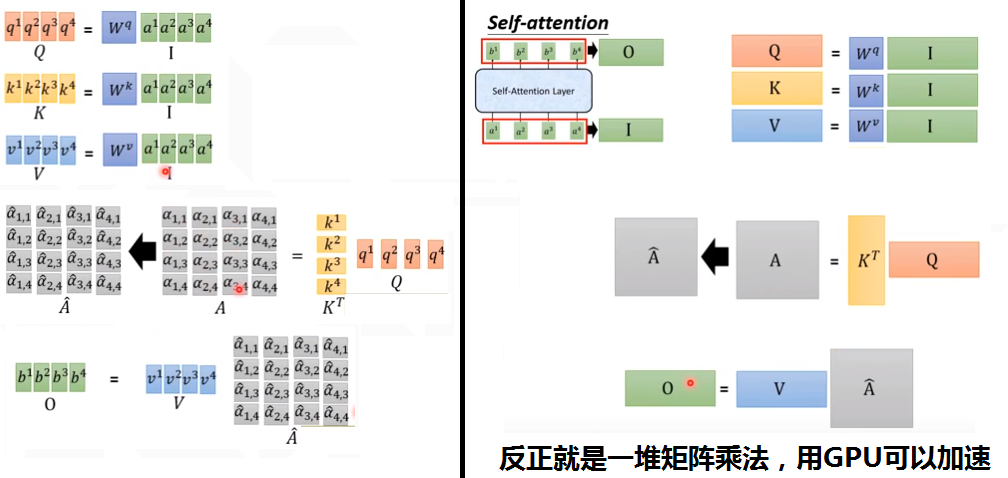
(2)self-attention layer做了什么?
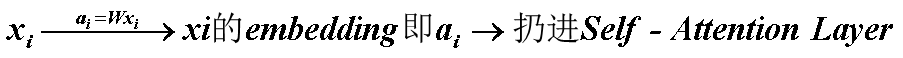

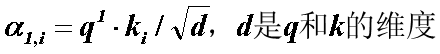
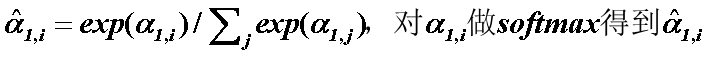
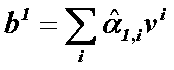
(2) 写成矩阵乘法形式
3. 变形muti-head self-attention
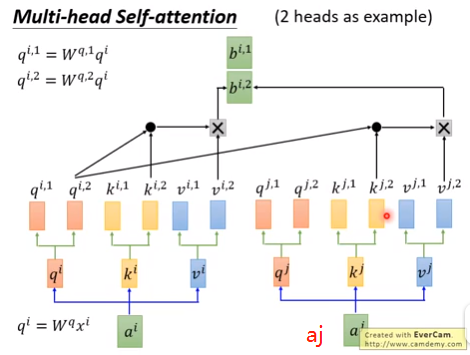
(1)原理
①多个Attention(Q,K,V)。
②也可能一种Attention head是给it做消解的,一种关注上下位的,一种关注首都国家对应关系的。每一种attention都可以把向量变成Q K V。
③如果有8个head,3个输入单词a1 a2 a3,则有8个bi1~bi8,拼成一个8维的向量,信息有冗余,需要降维。需要左乘一个8*1的矩阵,压缩成1个数bi,最后输出是3个数b1 b2 b3。
④下图是2个head的示意图。
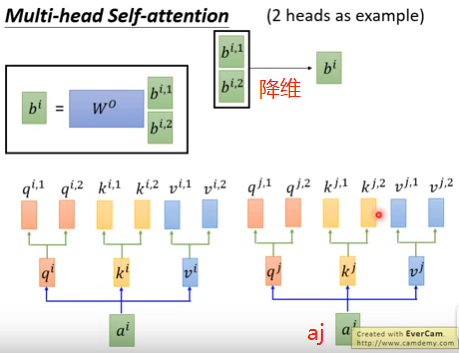
(2)好处
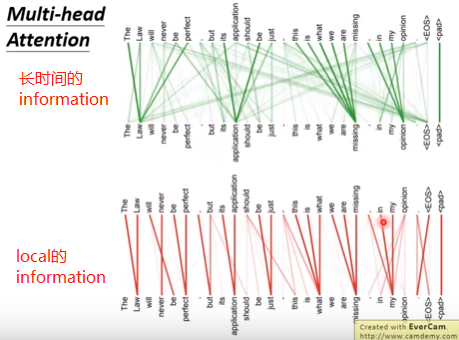
①不同head关注点不一样,每个head可以专注于自己的任务。下图,有的attention head关注local的邻居的资讯,有的关注的是global的长时间的资讯。
4.positional encoding
Self-attention不考虑顺序/位置因素,因此需要加入位置信息。
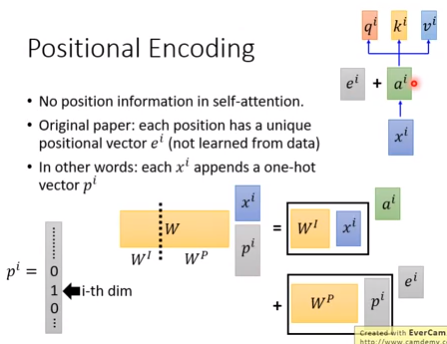
(1)Original paper
把ei加到ai里面。ei是手动设计的。
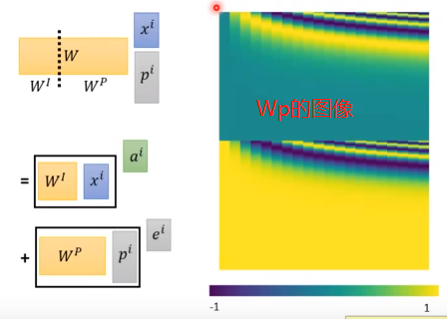
(2)另一种解释
每一个xi接上一个one-hot向量pi,W·xi之后,就得到ai+ei,而Wp需要手工设计。
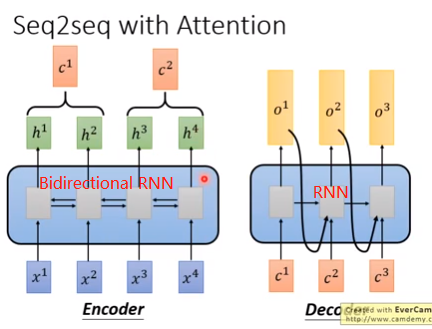
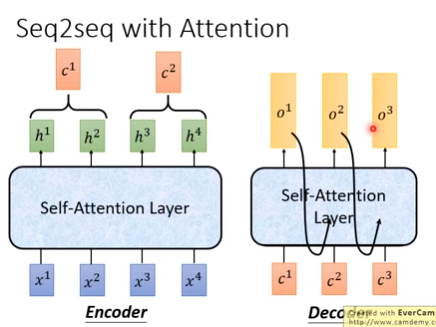
5.Seq2Seq model中的self-attention
(1)RNN的Seq2Seq (2)Self-attention的Seq2Seq
6.Transformer
(1)
多层Encoder和Decoder,可以并行计算,因此可以训练很深。
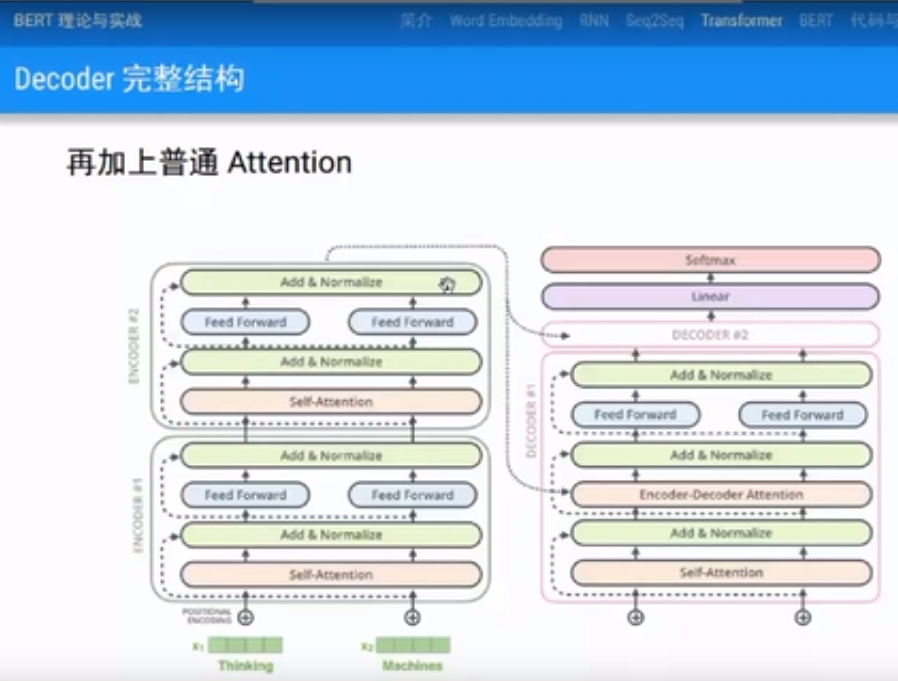
每一层有,Encoder,Decoder。Encoder有Self-Attention层和Feed Forward全连接层;Decoder比Encoder多一个普通的Encoder-Decoder Attention,翻译时候用来考虑Encoder输出做普通Attention。
(2)Transformer结构
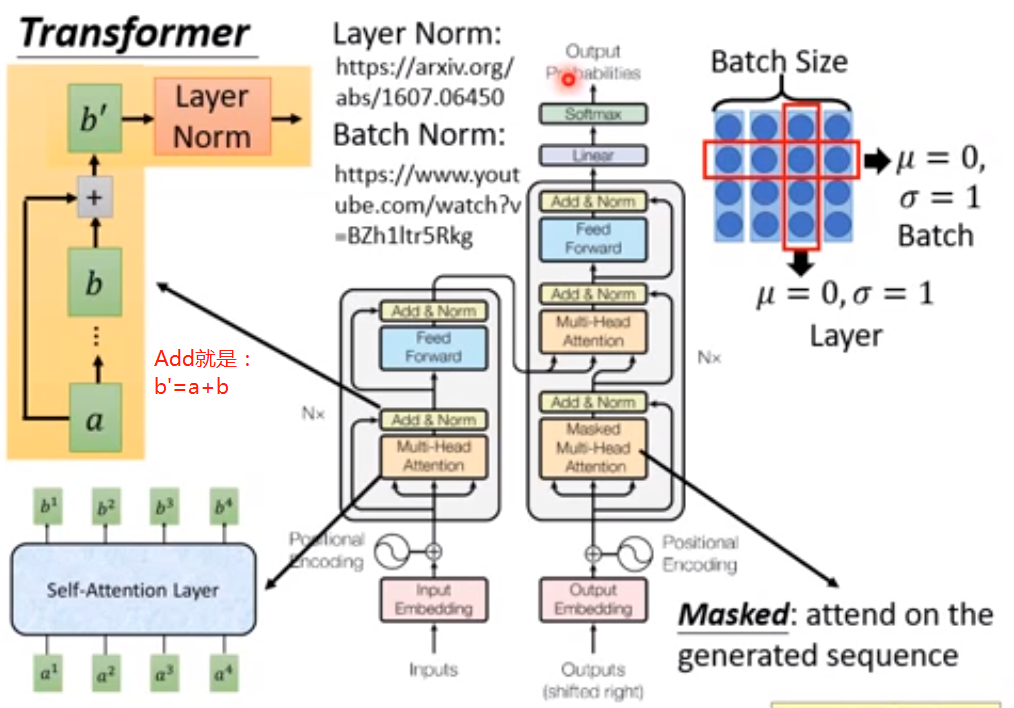
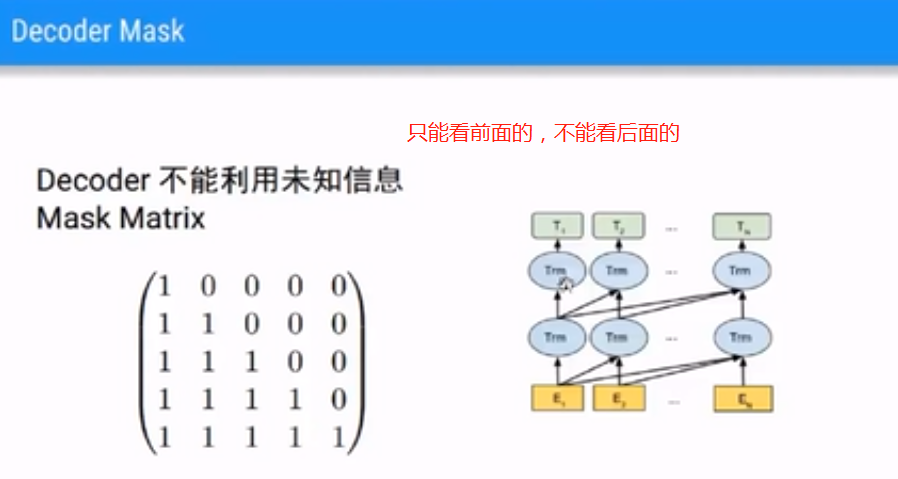
(3)Decoder Mask
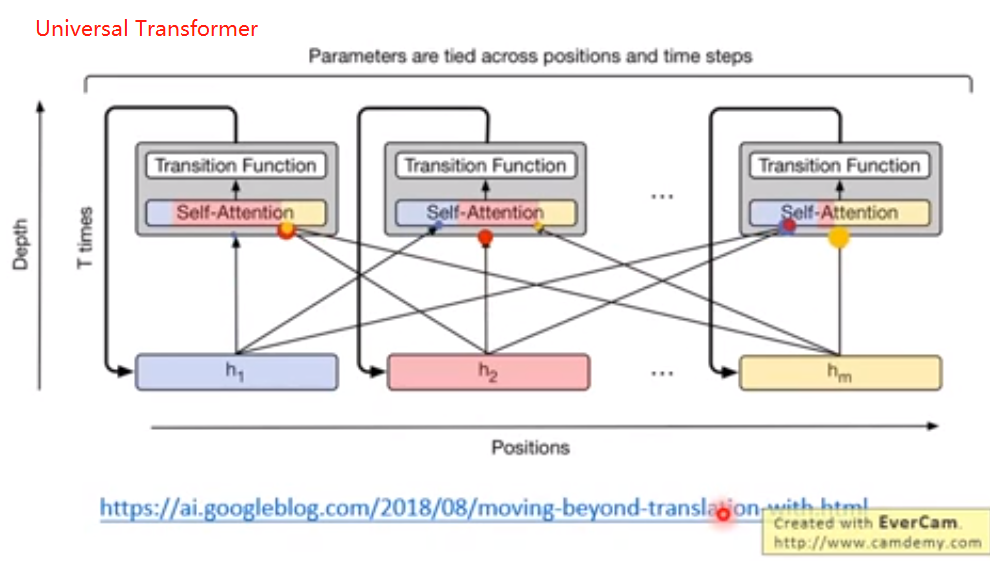
7.Universal Transformer
横向,时间上是m个Transformer,纵向是RNN。
8.Transformer用于图像处理

9.Transformer优缺点
RNN问题:没有双向信息流,不能并行计算。Transformer通过Self-attention和Positional encoding解决了RNN的问题。
缺点:数据稀疏问题仍然未解决
三、BERT
1.Contextual Word Embedding(今天主题)
数据稀疏仍是个问题。机器翻译可以有很多语料,但是其他任务没有语料,Transformer可以学习,但是需要监督数据来驱动,数据还是太少。
问题:Word Embedding无上下文;监督数据太少。
解决:用Contextual Word Embedding。考虑上下文的Embedding;无监督。
李宏毅:现在embedding,每一个token都有一个embedding。即Contextualized Word Embedding。上下文越接近的embedding,sense越接近。可以实现这个的技术是ELMO。
2.ELMO
(1)
Embeddings from Language Model,简称ELMO。2018年提出。
如果问一个普通的Word Embedding,“bank”什么意思,它会告诉你所有的意思。
如果问ELMO,它说我不知道,你得给我一个句子,然后它会根据句子上下文,给出具体答案。
(2)具体怎么考虑上下文?
先回到2003年的神经网络语言模型NNLM(Neural Network Language Model),Bengjo在《A Neural Probabilistic Language Model》提出了神经概率语言模型NPLM,NNLM思想来源于该论文。
2018年,我们的LSTM可以是多层双向的LSTM,不再是2003年那么简单了。
①预训练学习LSTM语言模型
先通过pretrain学习一个语言模型,也就是学习一个多层双向LSTM,也就是用前面出现的所有words预测后面的一个word。
②接下来怎样做具体任务?(eg:情感分类,文本分类)
假如是一个分类任务,来了一个句子,首先用多层双向LSTM把每一个单词进行编码,这个编码是考虑了上下文的。
每一个词通过n层双向LSTM,就会产生2n个向量。然后把这2n个向量组合起来,得到一个新的向量。我们就可以把这个新的向量作为固定的一个特征,之后该怎么处理就怎么处理。
③ELMO思路总结
所以ELMO相当于一个特征提取的方法,通过pretrain得到一个双向多层LSTM语言模型。来一个句子,这个LSTM语言模型就可以把它变成一个序列的向量。这些向量是考虑了上下文的,而且是做过消歧的,是做过指代消解的,所以是一种比Word Embedding更好的方法。LSTM编码完之后,这个向量就定住了。之后再往上加LSTM,加CNN,加全连接网络,该怎么玩儿就怎么玩儿。
3.OpenAI GPT
(1)
GPT 也是通过LSTM学习语言模型。不同于ELMO的是,这个语言模型不是固定的,而是会根据任务进行Fine Tuning,微调。
问题:
Contextual Word Embedding作为特征。
不适合特定任务。
解决:
根据任务进行Fine-Tuning
使用Transformer代替ELMO的多层RNN/LSTM
(2)怎么用transformer做语言模型?
Transformer包括Encoder和Decoder,可以实现翻译任务,一个英语句子一个法语句子,两个句子。但是语言模型只有一个句子,显然不能直接使用Transformer。
GPT其实相当于transformer的decoder。Decoder就和语言模型很像,编码一个单词的时候,只能看前面的句子,而不能看后面的。Self Attention是带了Masked,也就是只能Attention到前面的句子,不能Attention到后面的。因为没有了Encoder,也就没有了Encoder和Decoder之间的Attention。
GPT有很多层模块,每一层只有带Masked Self Attention,再加上全连接层。Transformer做翻译用了6个,而GPT用了12个,参数更多,效果更好。
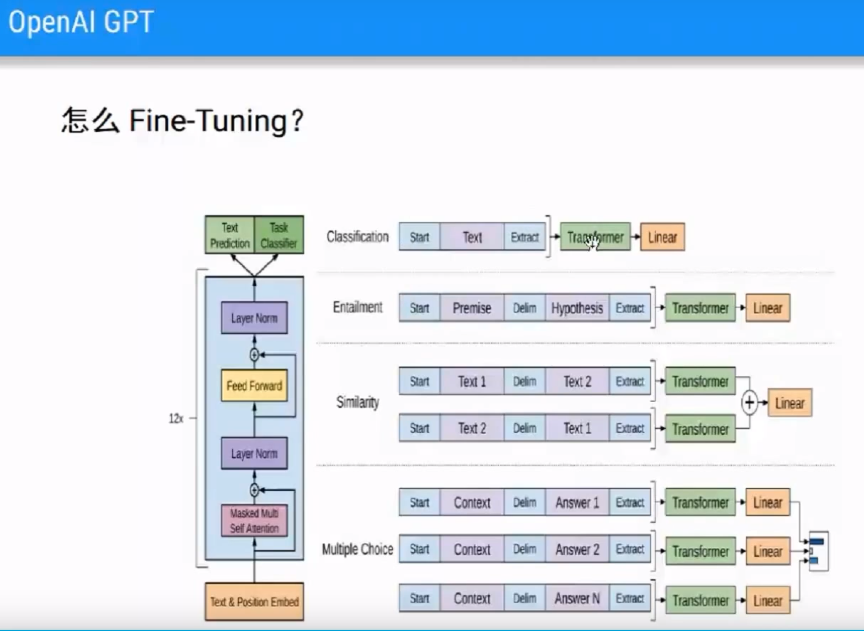
(3)怎么Fine-Tuning?
训练语言模型的时候,是一个句子,有的任务中不只是一个句子。
eg1:文本分类、情感分类问题,输入是一个句子,输出是一个类别。
eg2:两个或多个句子
Entailment即判断两个句子关系,蕴含关系、矛盾关系,是有两个句子的。
Similarity相似度计算,也是有两个句子的。
问答任务,更是有多个句子。
对于这种不止一个句子的情况,我们训练的时候仍然只需要一个句子,只有一个句子才能进行Fine-Tuning,一个句子一个模型。因此采用trikiler方法,强行把两个句子拼起来。
但是如果直接拼起来的话,我们会弄不清楚,这个词到底属于第一个句子还是第二个句子。所以在单词之间加了分隔符Delimit,当然前后也加了Start和Extract表示开始和结束。
4.BERT
(1)
OpenAI GPT问题:
单向信息流。
Pretraining(1个句子)和Fine-Tuning(2个句子)不匹配。
解决:
Masked LM(Language Model):解决单向信息流问题。
NSP(Next Sentence prediction) Multi-task Learning任务:变成2个句子的输入,把Pretrain变成2个句子。
是一种Encoder。
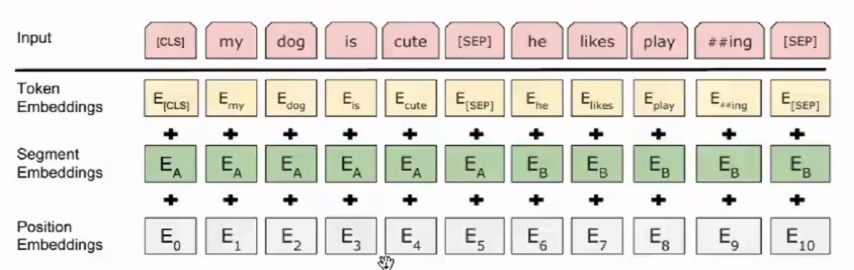
(2)BERT输入表示
输入分两段:输入两个句子,中间用[SEP] Separate分隔开,[CLS]表示句子开始。
BPE编码:机器翻译中常用的分词技巧,把词分得更系列的token。
输入2个句子,输出每个词的编码Token Embeddings,每个位置的编码Position Embeddings,词属于上一个片段还是下一个片段Segment Embeddings。
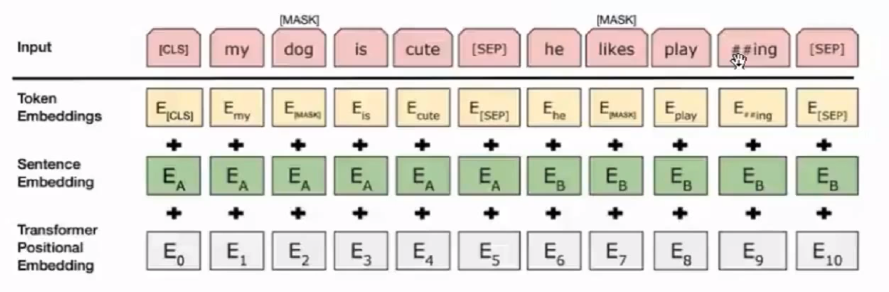
(3)Masked LM怎么解决单向信息流?
单向信息流的问题,实际上是预测任务的约束,也就是用前面的词预测后面的词,或者后面的词预测前面的词,也就是只有一个方向。
BERT直接换成Masked LM任务,类似于完形填空,随机Mask掉15%的词,让BERT来预测。
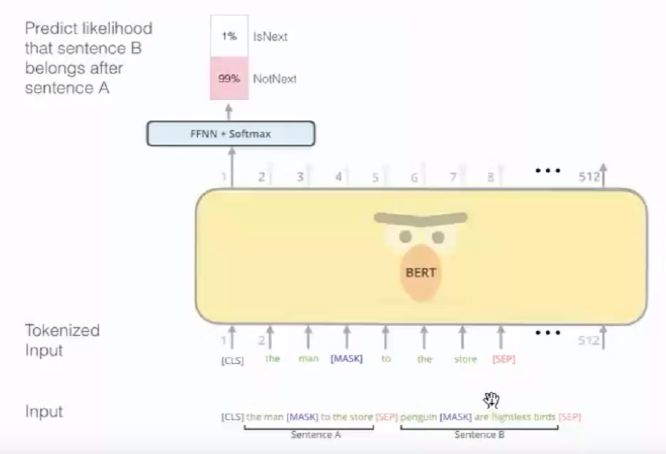
(4)怎样把Pretrain变成2个句子?
引入新任务——预测句子关系,解决Pretraining和Fine-Tuning不匹配。
BERT以50%的概率随机抽取2个连贯句子,50%概率抽取随机2个句子,作为2个句子的输入。
连续的句子值为1,不连续值为0。通过对是否是连续句子的预测,学习到两个句子关系。这种关系在Entailment、Similarity、问答任务中很有用。
(5)怎样Fine-Tuning?
①单个句子的任务:文本分类、情感分类 。
根据CLS对应的Word Embedding输出进行分类。由于BERT使用了天涯若比邻的Self-attention,CLS位置随意,一般放开头。
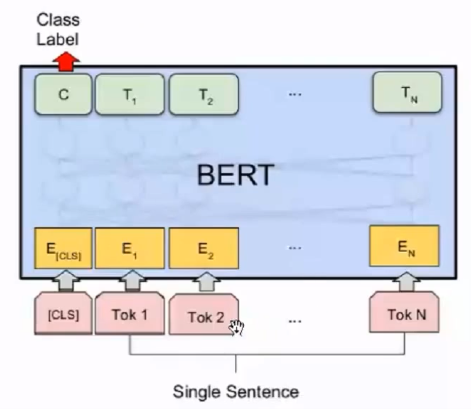
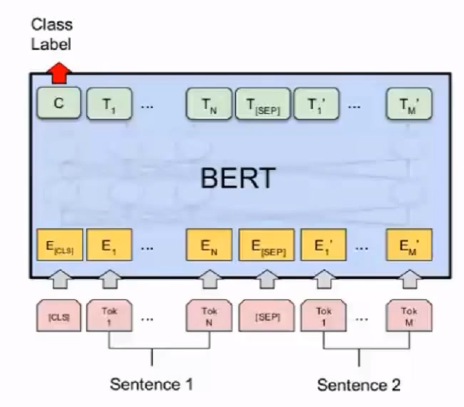
②两个句子的任务:Entailment、Similarity。
仍然用CLS对应的Word Embedding来做预测。
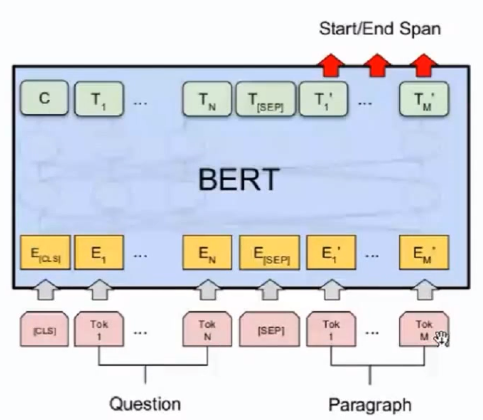
③问答类任务:输入两个句子,预测某个词是否是句子的开始或结束。
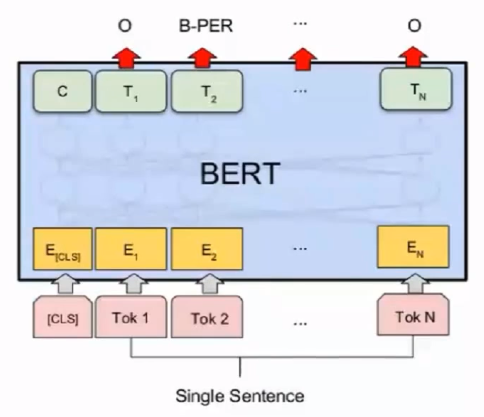
④序列标注:预测每个时刻是某种标签。
5.代码
(1)文件结构
run_classifier.py 用来做文本分类任务
run_squad.py 用来做阅读理解类任务
(2)Fine-Tuning
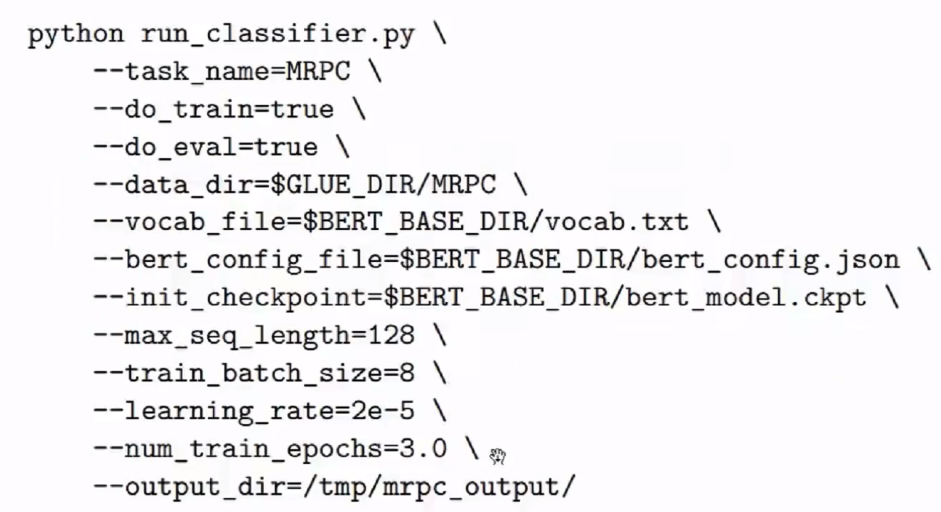
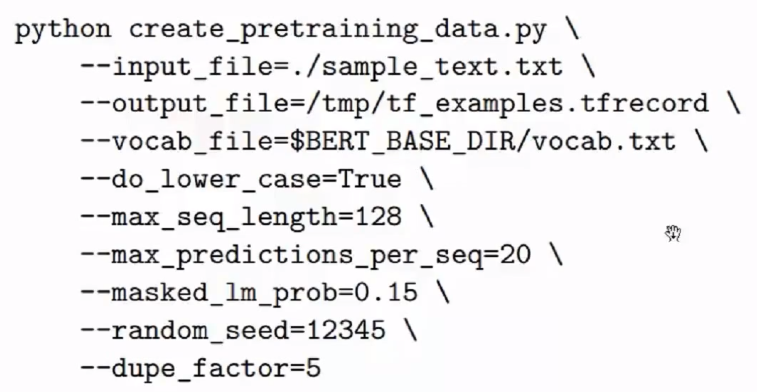
(3)有比较多的数据,想要更好的效果,需要Pretraining
①数据预处理:
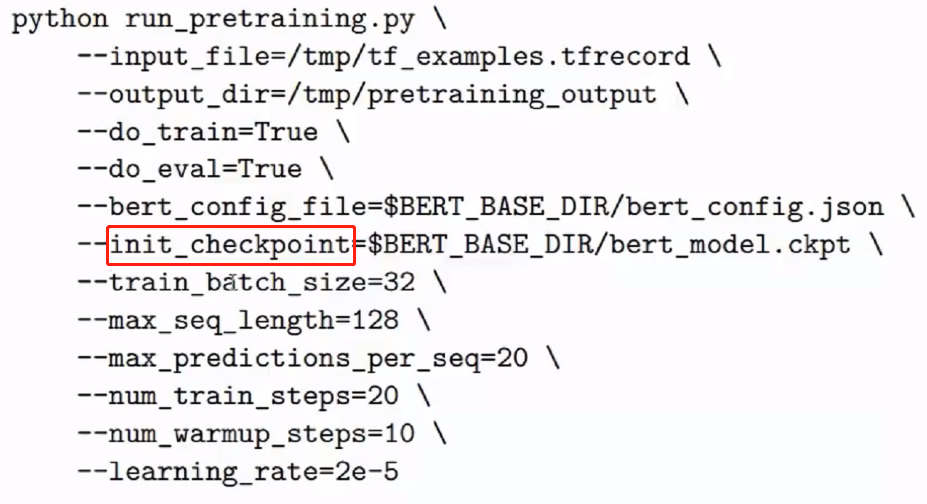
② pretraining:
由于耗时,通常使用Google的某个版本,在其基础上进行训练,需要指定init_checkpoint。
参考:
https://www.bilibili.com/video/BV1GE411o7XE?from=search&seid=8158434315525640721
作者:西伯尔
出处:http://www.cnblogs.com/sybil-hxl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

