

导论
自然语言处理,NLP,接下来的几篇博客将从四方面来展开:
(六)Expectation-Maximization
(七)Machine Translation
(四)Language Models
NLP的基本任务。给定句子w,预测句子w1...wk的概率,P(w)=P(w1,...,wk)=∏P(wk|wk-1 ... w1)
(1)传统语言模型
N-gram:统计的语言模型。通过词的历史来预测当前值。
2个大问题:①长距离的依赖问题。N-gram只能看前面2-5个词,而看的词太多的话,参数太多,训练数据也不够,学不到那么复杂的关系。
②泛化能力差,不能共享上下文参数的问题。
eg:我要去北京/上海,概率应该一样大,而N-gram根据历史记录,出现的次数多的概率大。而RNN可以解决问题②。
(2)RNN模型
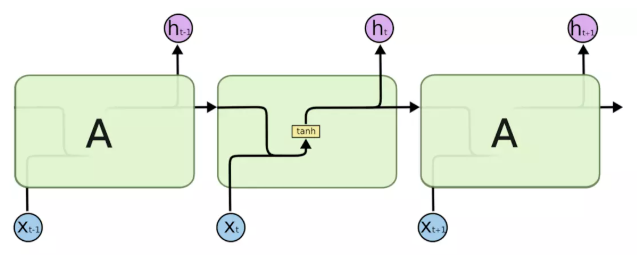
标准RNN中,重复模块具有非常简单的结构,例如单个tanh层,上图是标准RNN网络。
①Word2Vec:
CBOW,Context预测中心词;
Skip-Gram,中心词预测Context;
Word2Vec缺点:不考虑上下文,编码“bank”时候,只能把两个意思编码进去。用RNN可以解决这个问题,因为RNN有记忆能力。
②Vanilla RNN
缺点:梯度消失和梯度爆炸问题。LSTM可以解决这个问题。
③长短期记忆网络(Long Short Term Memory networks,LSTMs)
LSTMs是一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。
LSTMs也具有RNN的重复块链式结构,但是它的重复单元不同于标准RNN网络里的单元只有一个网络层,它的内部有四个网络层。LSTMs的结构如下图所示。
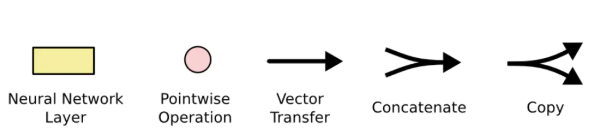
图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。
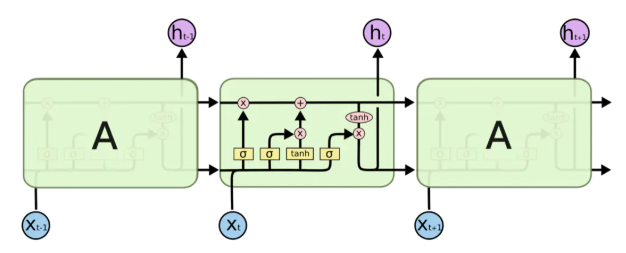
有两个记忆单元:隐状态h(hidden state)和cell state。
通过门控制来避免梯度消失。
通过遗忘门来控制cell state是否要抹掉这个信息。
④GRU
把遗忘门和输入门合并成一个更新门。
一个RNN问题:一个句子翻译到另一个句子,不可能两个句子位置一一对应。Seq2Seq可以解决。
⑤Seq2Seq
使用两个RNN,Encoder和Decoder。
可以做其他NLP任务:翻译,对话,问答。
缺点:
需要固定长度的context向量编码原句子的所有语义,很困难。只记住了大概,细节问题难以记忆。
Attention机制可以解决问题。
(3)Attention
内容在下一部分讲解
作者:西伯尔
出处:http://www.cnblogs.com/sybil-hxl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

