

ELMO, BERT, GPT讲解
1.导论
(1)过去计算机怎么读人类文字的?
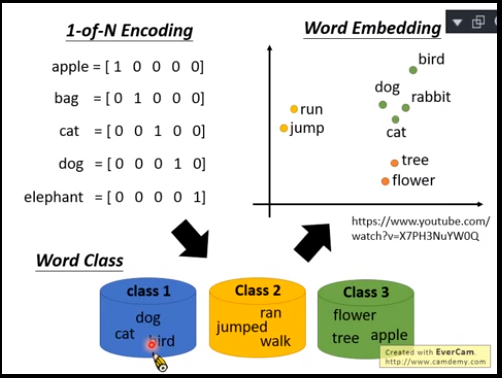
1-of-N Encoding:每个单词有一个编码,但是这样单词之间没有关联。
Word Class:按照类别分,但是太粗糙了,无法细分。
Word Embedding:向量表示,接近的向量有近似的语义。
(2)一个word有不同sense(意思)
①embedding
传统embedding,不同token(唯一标识)可以是相同的type(外形),每一个type都有相同的embedding(词义)。
需求,不同token可以是相同type,但是同一个type可以有不同embedding(词义)。相当于一词多义。
传统解决方案,查词典,一个单词有两种含义,训练按照其含义分2类。bank,银行,河岸。
不够,原因是,不同词典一个单词可能有三种含义,语义很微妙。bank,银行(存储),河岸,血库(存储)。你说银行和血库是相同还是不同?
现在embedding,每一个token都有一个embedding。即Contextualized Word Embedding。上下文越接近的embedding,sense越接近。可以实现这个的技术是ELMO。
②补充说明:token & type&embedding
word type,就是单词外形,"grape"和"apple",就是两个word type,不同句子中的“bank”是同一个type。
word token,更多相当于唯一标识,与id类似。是独立于时间以及空间存在。我现在说"grape"和十秒后再念一次"grape",就是两个token,不同句子的同一个“bank”也是两个token。
embedding,人类尝试用embedding表示sense。
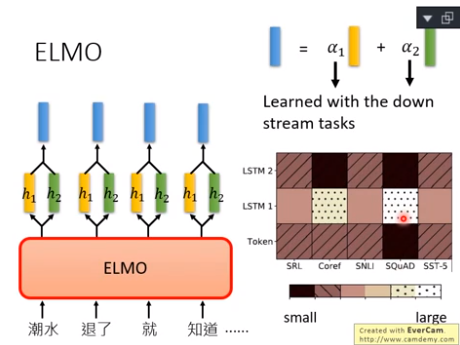
2.ELMO
Embeddings from Language Model,简称ELMO。
ELMO是一种RNN-based language models(只需要爬一大堆句子,这些句子不需要任何标注,就能训练一个RNN-based language model),任务是预测下一个token是什么。
学完以后的ELMO生成的Embedding,就是Contextualized Embedding。
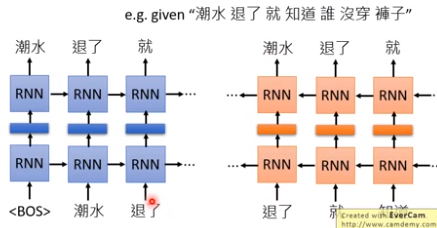
双向RNN:正向RNN的Embedding和逆向RNN的Embedding接起来。eg,“退了”这个词的Embedding就是把“退了”在正向RNN的Embedding和在逆向~接起来。
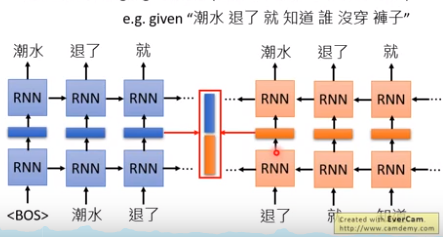
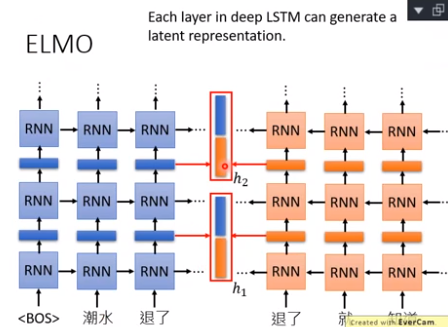
深度ELMO,有很多层,一个词就有很多Embedding,到底该选择哪个呢?ELMO的方案是,全都要。把所有的Embedding加权求和,权重αi是学习来的,先决定好任务,然后αi作为参数的一部分一起学习出来。
右图表明,Coref任何和问答任务SQuAD,特别需要LSTM1(权重大),其他任务的weight比较平均。
3.BERT
(1)
Bidirectional Encoder Representations from Transformers,BERT。
BERT=Encoder of Transformer。
从未标记的大量文本学习。
BERT的功能:输入一个句子,输出每一个词的Embedding。
如果处理中文,训练BERT的时候,用“字”比“词”更合理,因为字是有限的,词无限,用one-hot encoding vector 描述字,维度不会太大。
(2)两种训练方法
训练的时候,下面两种方法是同时使用的,同时使用,效果最好。
①训练方法一:Masked LM
随机Mask掉15%的词汇。
BERT的任务:预测被Masked词汇。如果两个词填在相同的地方没有违和感,那他们就有相似的Embedding。
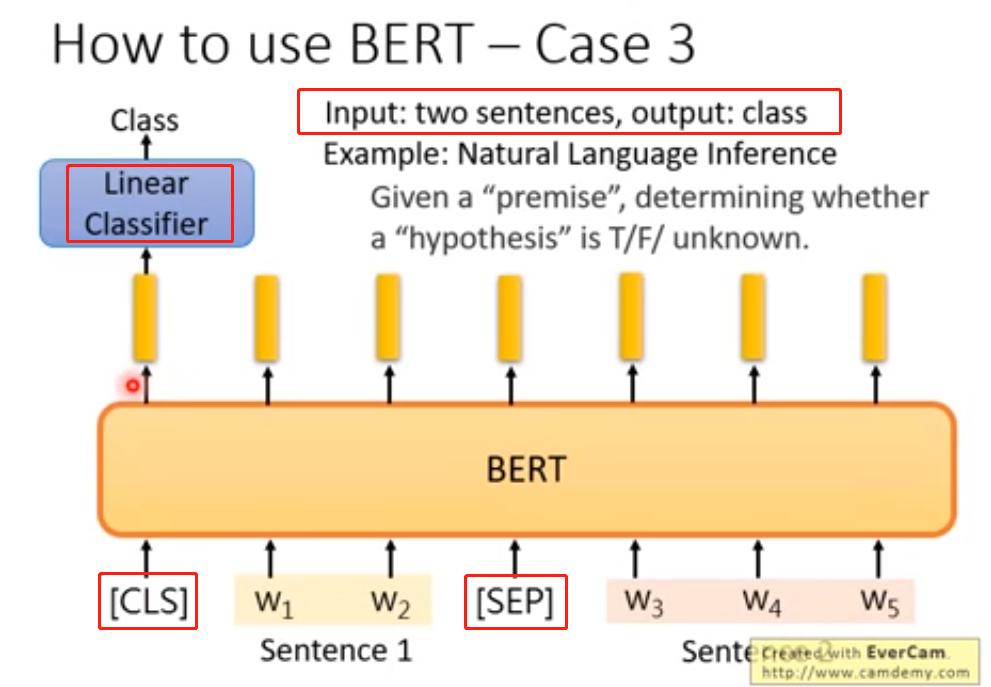
②训练方法二:Next Sentence Prediction
[SEP]:两个句子之间的界限。
[CLS]:表示这个位置要做分类,也就是用来作为分类器的依据,此位置的输出是分类器的输入。
[CLS]放在哪个位置随意,一般在句子开头。由于BERT中是Self-attention,特点是天涯若比邻,也就是说,位置无关。所以放在开头、中间、结尾,都是没有影响的。
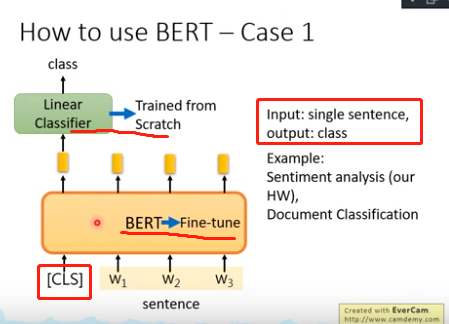
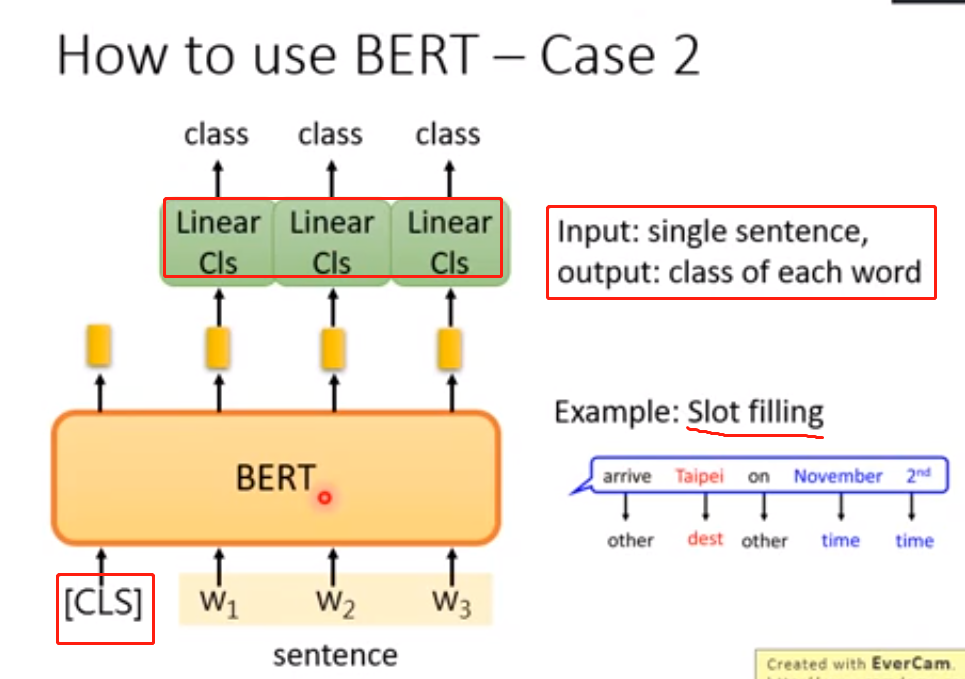
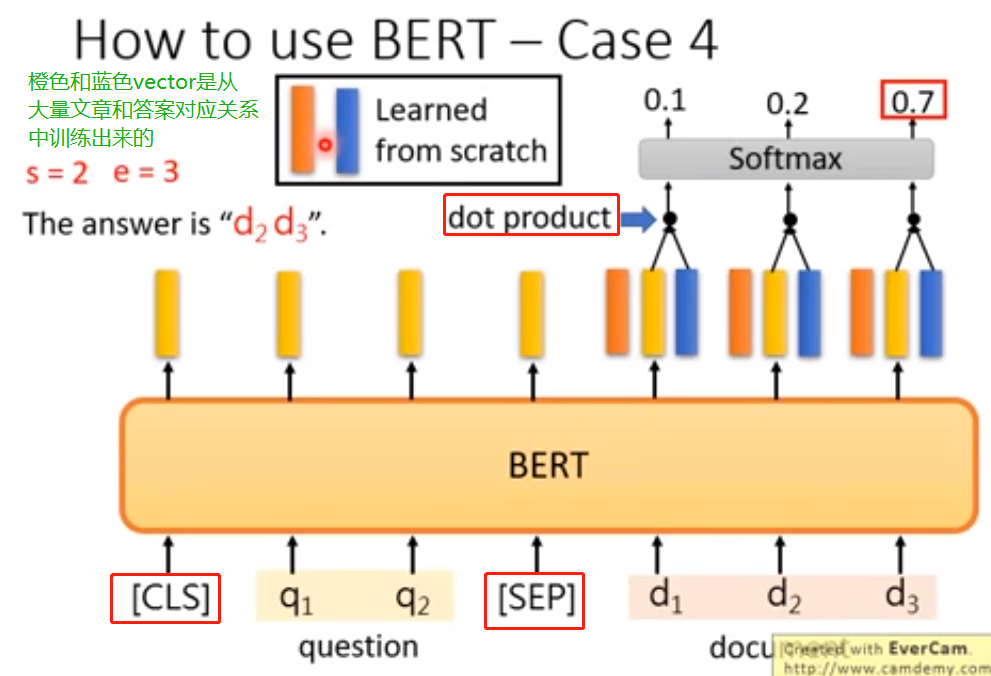
(3)怎样使用BERT

参考:
作者:西伯尔
出处:http://www.cnblogs.com/sybil-hxl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

