yaml数据驱动以及封装xpath方法
5数据驱动
5.1 Yaml数据存储文件
简介:YAML
是一种可读性非常高,与程序语言数据结构非常接近。同时具备丰富的表达能力和可扩展性,并且易于使用的数据标记语言。
yaml和yml是一个东西,所以这两个后缀名都可以。
语法规则:
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用tab,只能是空格(pycharm中tab会自动被换为空格)
- 缩进的空格数量无所谓,只要同一层级的关系缩进的空格是一样的即可
支持的数据结构:
键值对组合:映射、哈希、字典
数组:列表、序列
纯量:单个的,不可再分的值(不可再往下分的,比如列表中可以包含字典,字符串,但是字符串不能再分,纯量大概包含:(字符串、布尔值、整数、浮点数、null、时间、日期)
5.2 字典和列表在yaml中的写法
首先在pycharm中新建一个yaml文件,假如名字为data.yaml或者data.yml
字典写法:
# 字典
name: 'sy'
age: 18
字典是键值对的形式,yaml中,先写键,然后紧接着写冒号,再写一个空格,再写值,键不需要写引号,yml会自动加上写完一个键值对,回车继续写,写完以后,如果正确的话,会变颜色,如图:

新建一个py文件,内容为:
import yaml def main(): # 读取刚写的data.yml文件 with open(r'./data.yml', 'r', encoding='UTF-8') as f: data = yaml.load(f) print(data) if __name__ == '__main__': main()
如果yaml文件没有安装的话,先用pip安装一下:pip install pyyaml或者pip3 install pyyaml
运行这个文件可以验证刚才写的yml文件是否正确。
比如此时运行结果为:
{'name': 'sy', 'age': 18}
列表写法:
# 列表
- '1'
- '2'
- 'abc'
这里是一个中划线,一个空格,后面跟列表的值,注意这里不需要冒号。
还是用上面的py文件验证,运行结果为:
['1', '2', 'abc']
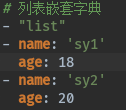
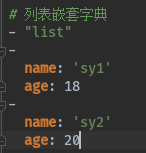
列表嵌套字典:
或者
运行结果:
['list', {'name': 'sy1', 'age': 18}, {'name': 'sy2', 'age': 20}]
嵌套的话,主要是看值到底是什么,比如上面这个结果,整体一个列表,第一个值是’list’,那就直接在- 后面跟上’list’,第2个值是一个字典,- 后面就跟一个一个的键值对就行。每写完一个键值对,记得回车,然后tab或者空格。
字典嵌套字典:
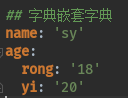
运行结果:{'name': 'sy', 'age': {'rong': '18', 'yi': '20'}}
字典嵌套列表:
# 字典嵌套列表
name: 'sy'
age:
- 'age1'
- 'age2'
这里一定要注意,’- age1’和’- age2’前面的空格数是一样的。
运行结果:
{'name': 'sy', 'age': ['age1', 'age2']}
列表嵌套列表

运行结果:['1', ['3', '4'], '5']
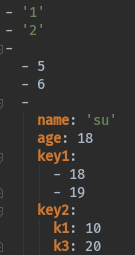
综合运用,写出如下列表的yml文件
['1', '2', [5, 6, {'name': 'su', 'age': 18, 'key1': [18, 19], 'key2': {'k1': 10, 'k3': 20}}]]
5.3 yaml纯量
字符串:用双引号或者单引号引起来,事实上也可以不引,yml会自动识别。
整数:没有双引号引起来的数字
浮点数:带有小数点的,并且小数点后面最多能有15位,多余的会四舍五入。
布尔型:True、False、TRUE、FALSE、true、false
空值:NULL、null、Null(python中None表示的是空,所以用python输出的是None)
日期:2019-01-03、2019-01-03 23:20:59.111(.111表示毫秒),python输出为:
datetime.datetime(2019, 1, 3, 23, 20, 59, 111000)
5.4 读写yaml
yaml.load()方法
上面已经用过yaml.load()方法,这个方法可以读取yml文件中的内容,具体用法:
import yaml def main(): # 读取刚写的data.yml文件 with open(r'./data.yml', 'r', encoding='UTF-8') as f: # data = yaml.load(f) # 上面那种用法,后来被人认为不安全,运行的时候会报warning,可以改为: data = yaml.load(f, Loader=yaml.FullLoader) print(data) if __name__ == '__main__': main()
yaml.dump(data, stream, **kwds)方法
这个方法可以用来写yml文件,常用的参数有:
data:写入的数据,数据格式应为字典
stream:写入的文件对象
encoding=’utf-8’:设置写入编码格式
allow_unicode=True :是否允许unicode编码
代码示例:
def main(): with open(r'./test.yml', 'w') as ff: aproject = {'name': 'SY', 'race': 'Human', 'traits': ['中国', '你好'] } yaml.dump(aproject, ff, encoding='utf-8', allow_unicode=True) ff.close()
这里一定要注意:encoding='utf-8', allow_unicode=True这两个参数可以保证写入的中文不会是Unicode编码格式,而是直接显示中文。
另外待写入的数据aproject必须是字典
5.5 锚点和引用
锚点这个内容不常用,简单了解
锚点:标注一个内容或者一段内容,类似定义变量
引用:使用被锚点标注的内容,使用方法:<<: *锚点名
例如:
data: &info
value: 123
value1: 456
name:
name1: ss
name2: yy
<<: *info
上面标红的地方是定义锚点,下面标黄色底色的是使用锚点,没有这两个的时候,这个yml内容是:
{'data': {'value': 123, 'value1': 456}, 'name': {'name1': 'ss', 'name2': 'yy'}}
加了锚点后:
{'data': {'value': 123, 'value1': 456}, 'name': {'value': 123, 'value1': 456, 'name1': 'ss', 'name2': 'yy'}}
上面的data的值放到了name中,而且只能全部放入,不能只放data的一部分。
另外还有一个需要注意的点:data的值本身也是一个字典,如果这个字典的键和name中的键有一样的,则data中相同键不会被复制到name中
5.6 yaml数据驱动应用
假如有个需求:进入设置页面,点击放大镜,输入内容,点击搜索。内容要求输入不同的值多次测试。
这时候首先想到的就是使用pytest中的参数化功能:
@pytest.mark.parametrize("content", ["hello", 123]) def test_search(self, content): # 点击放大镜 self.search_page.click_search() # 输入文字 self.search_page.input_content(content) # 点击返回 self.search_page.click_back()
参数化功能如果不熟悉可以参考链接:
https://www.cnblogs.com/sy_test/p/12546400.html
然后现在我们想要yaml文件存储这些数据,然后将yml文件解析为列表,放到@pytest.mark.parametrize中。
具体怎么做呢?
首先看目录结构:
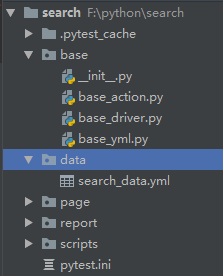
跟之前的PO模式比,多了一个data文件夹,base文件夹中多了一个解析yml的py文件。
ps:PO模式在另外一个链接:https://www.cnblogs.com/sy_test/p/12565864.html
search_data中放的内容:
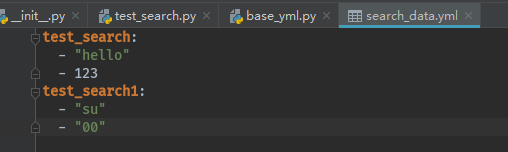
这个文件放的是test_search和test_search1这两个用例的参数,如果有多个用例,可以继续往下加。
base_yml.py的内容:
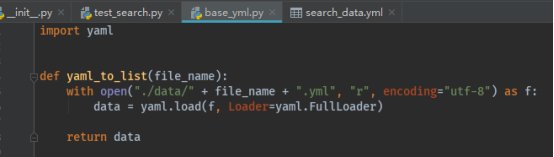
file_name参数:待解析的yml文件,里面的内容应该知道了,就是返回yml的内容,上面讲过。注意这里返回去的是一个字典。
search_page.py和之前PO模式讲过的一样,这里贴一下:
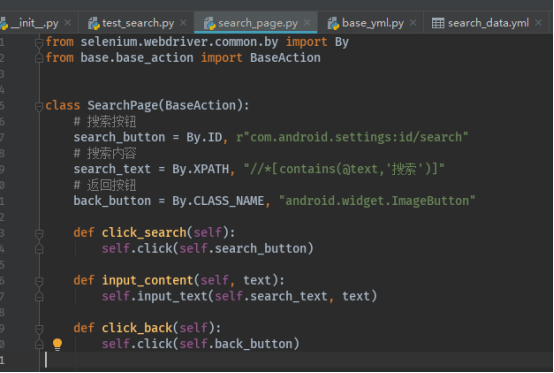
然后就是test_search了:

def param(test_name):
return yaml_to_list("search_data")[test_name]
yaml_to_list这个方法返回的是一个字典,通过[test_name]取得字典中test_name这个键对应的值,而这个值就是一个列表,这个函数,意义在于将这个列表返回去。
5.7 xpath特殊处理
5.7.1 xpath用法
//*[contains(@xxx, ‘’)]这个上面讲过,比如:
driver.find_element_by_xpath("//*[contains(@text, '更多')]").click() # 点击更多
这个意思是说text属性的内容包含更多两个字就可以。
那么如果想要精确查找,怎么写?
("//*[contains(@text= '更多')]")
text属性等于‘更多’才会被找到。
如果 一个条件找不到,需要多个条件:
("//*[contains(@text= '更多' and @name = '更多' )]")
这个是说text属性等于更多,并且name属性也等于更多,才会被找到。
当然也可以用contains方法和and共同使用。
5.7.2 单条件拼接
# //*[contains(@text, '更多')]
# //*[@name='设置']
# 我希望我使用这个方法的时候,不用很复杂,只要传一个参数"@text,更多"就能使用
def make_xpath_unit_feature(loc): """ 拼接xpath中间的部分 """ args = loc.split(",") if len(args) == 2: feature_middle = "contains(" + args[0] + ",'" + args[1] + "')" elif len(args) == 3: if args[2] == "1": feature_middle = args[0] + "='" + args[1] + "'" elif args[2] == "0": feature_middle = "contains(" + args[0] + ",'" + args[1] + "')" return feature_middle def make_xpath_feature(loc): """ loc的值为'@text,更多',表示要使用contains方法的xpath, '@text,更多,1':表示使用精确查找 '@text,更多,0',表示要使用contains方法的xpath, """ feature_start = "//*[" feature_end = "]" feature = "" feature = make_xpath_unit_feature(loc) result = feature_start + feature + feature_end print(result) # 调用方法,查看结果 make_xpath_feature("@text,更多") make_xpath_feature("@name,设置,1")
5.7.3 多条件拼接
# 假如有多个条件 例如://*[contains(@text, '更多') and @name='设置']
# 那么中间的部分就是多次调用make_xpath_unit_feature这个方法,用and拼接起来
def make_xpath_unit_feature(loc): """ 拼接xpath中间的部分 """ args = loc.split(",") # xpath查找的属性名 key_index = 0 # 属性值 value_index = 1 # 是按照什么方式查找,0表示使用contains方法,1表示使用精确查找 option_index = 2 if len(args) == 2: feature_middle = "contains(" + args[key_index] + ",'" + args[value_index] + "')" + " and " elif len(args) == 3: if args[option_index] == "1": feature_middle = args[key_index] + "='" + args[value_index] + "'" + " and " elif args[option_index] == "0": feature_middle = "contains(" + args[key_index] + ",'" + args[value_index] + "')" + " and " return feature_middle def make_xpath_feature(loc): """ loc的值为'@text,更多',表示要使用contains方法的xpath, '@text,更多,1':表示使用精确查找 '@text,更多,0',表示要使用contains方法的xpath, """ feature_start = "//*[" feature_end = "]" feature = "" if isinstance(loc, str): feature = make_xpath_unit_feature(loc) else: for i in loc: feature += make_xpath_unit_feature(i) feature = feature.rstrip(" and ") result = feature_start + feature + feature_end print(result) make_xpath_feature("@text,更多") make_xpath_feature("@name,设置,1") make_xpath_feature(["@name,设置,1", "@text,更多"])
这个xpath相关方法就完成了,可以放到action里面作为一个工具类来使用了。
完整的代码请参考:https://github.com/suyang2020/PoDemo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号