管理敏感词+图片识别文字审核敏感词
1.DFA实现原理
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。
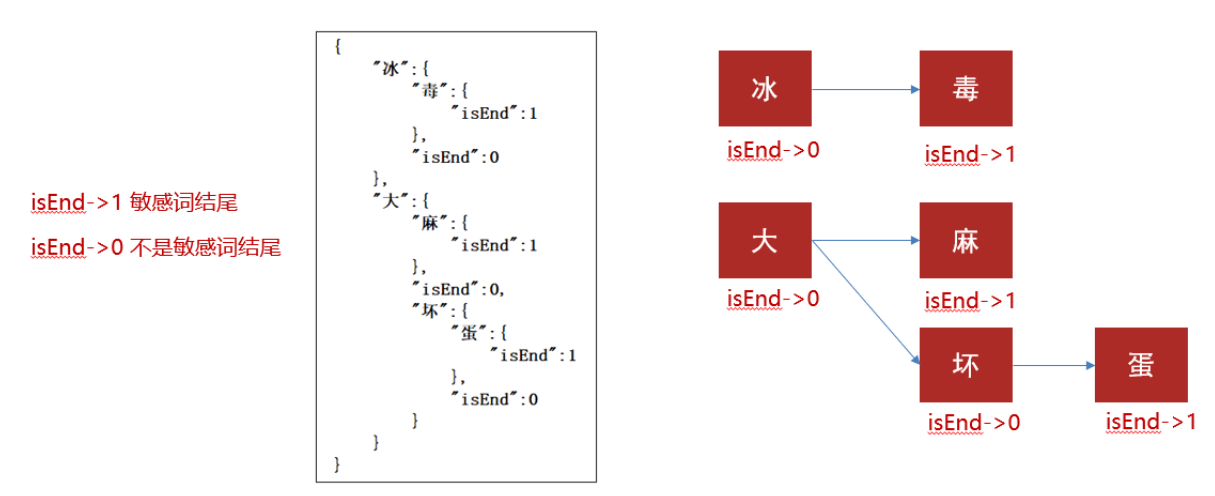
存储:一次性的把所有的敏感词存储到了多个map中,就是下图表示这种结构
敏感词:冰毒、大麻、大坏蛋
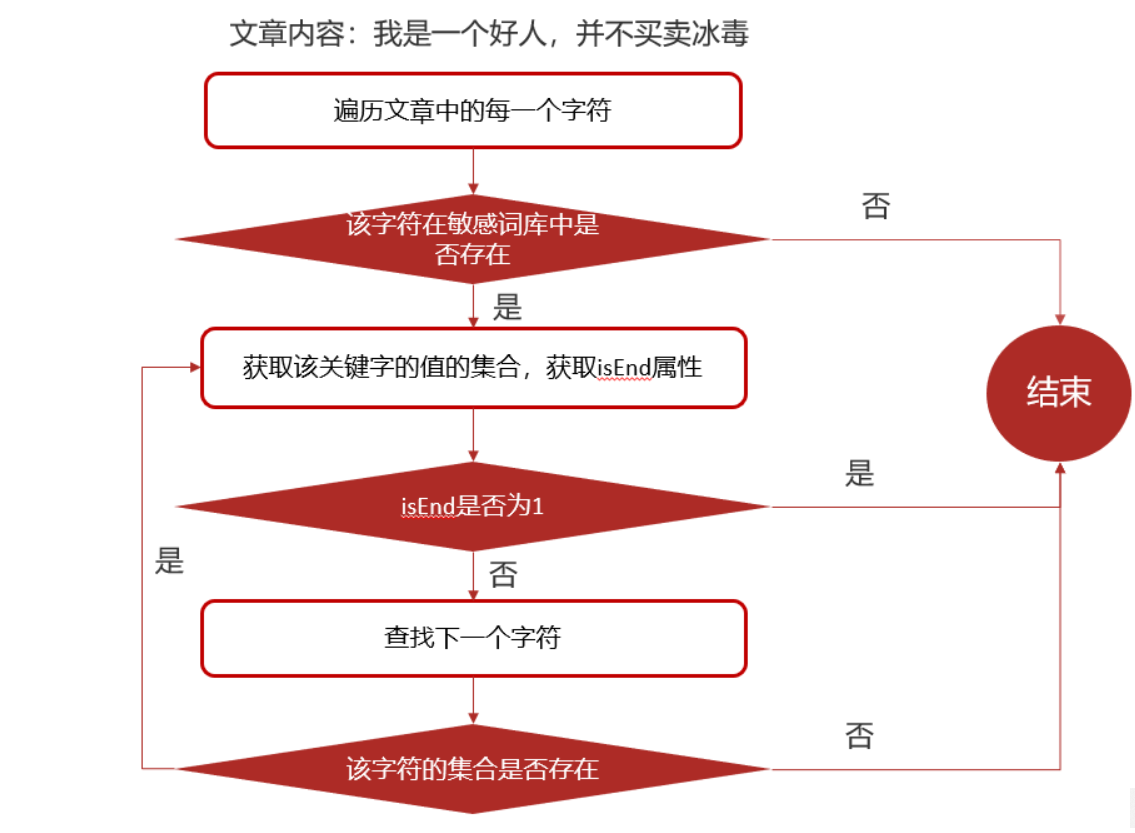
检索的过程
2.实现步骤
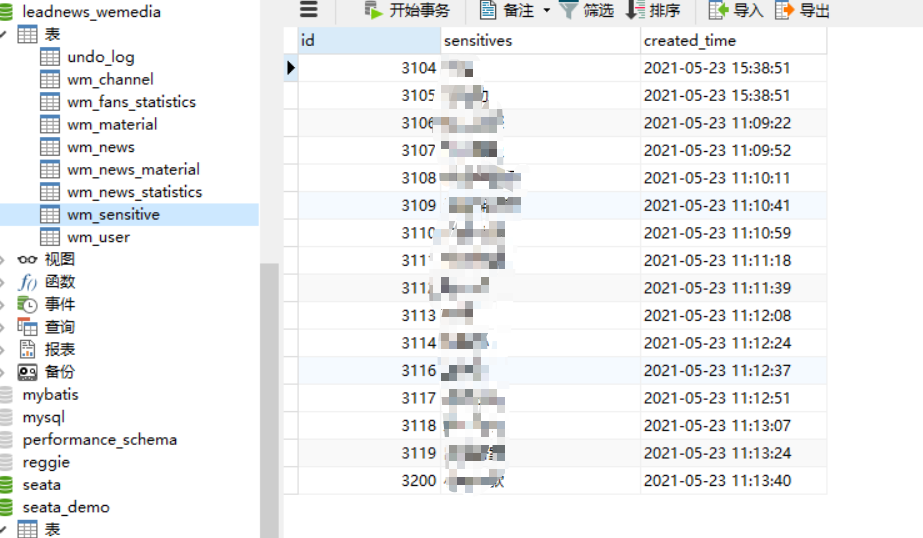
2.1 创建敏感词数据库表
1).
2).创建实体类
package com.heima.model.wemedia.pojos;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* <p>
* 敏感词信息表
* </p>
*
* @author itheima
*/
@Data
@TableName("wm_sensitive")
public class WmSensitive implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 敏感词
*/
@TableField("sensitives")
private String sensitives;
/**
* 创建时间
*/
@TableField("created_time")
private Date createdTime;
}
3.创建Mapper,查询敏感词库存入集合
package com.heima.wemedia.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.model.wemedia.pojos.WmSensitive;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface WmSensitiveMapper extends BaseMapper<WmSensitive> {
}
这里用到了工具类中的两个方法,第一个
initMap是给每一个字存入Map集合,加个0或1的标记,用来区分是否是结尾的字,第二个matchWords是查找对应的词是否在敏感词库,如果在里面就返回Map对象,实例:贷款=1意思是该词出现了多少次。
//初始化敏感词库
SensitiveWordUtil.initMap(sensitiveList);
//查看文章中是否包含敏感词
Map<String, Integer> map = SensitiveWordUtil.matchWords(content);
工具类
package com.heima.utils.common;
import java.util.*;
public class SensitiveWordUtil {
public static Map<String, Object> dictionaryMap = new HashMap<>();
/**
* 生成关键词字典库
* @param words
* @return
*/
public static void initMap(Collection<String> words) {
if (words == null) {
System.out.println("敏感词列表不能为空");
return ;
}
// map初始长度words.size(),整个字典库的入口字数(小于words.size(),因为不同的词可能会有相同的首字)
Map<String, Object> map = new HashMap<>(words.size());
// 遍历过程中当前层次的数据
Map<String, Object> curMap = null;
Iterator<String> iterator = words.iterator();
while (iterator.hasNext()) {
String word = iterator.next();
curMap = map;
int len = word.length();
for (int i =0; i < len; i++) {
// 遍历每个词的字
String key = String.valueOf(word.charAt(i));
// 当前字在当前层是否存在, 不存在则新建, 当前层数据指向下一个节点, 继续判断是否存在数据
Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key);
if (wordMap == null) {
// 每个节点存在两个数据: 下一个节点和isEnd(是否结束标志)
wordMap = new HashMap<>(2);
wordMap.put("isEnd", "0");
curMap.put(key, wordMap);
}
curMap = wordMap;
// 如果当前字是词的最后一个字,则将isEnd标志置1
if (i == len -1) {
curMap.put("isEnd", "1");
}
}
}
dictionaryMap = map;
}
/**
* 搜索文本中某个文字是否匹配关键词
* @param text
* @param beginIndex
* @return
*/
private static int checkWord(String text, int beginIndex) {
if (dictionaryMap == null) {
throw new RuntimeException("字典不能为空");
}
boolean isEnd = false;
int wordLength = 0;
Map<String, Object> curMap = dictionaryMap;
int len = text.length();
// 从文本的第beginIndex开始匹配
for (int i = beginIndex; i < len; i++) {
String key = String.valueOf(text.charAt(i));
// 获取当前key的下一个节点
curMap = (Map<String, Object>) curMap.get(key);
if (curMap == null) {
break;
} else {
wordLength ++;
if ("1".equals(curMap.get("isEnd"))) {
isEnd = true;
}
}
}
if (!isEnd) {
wordLength = 0;
}
return wordLength;
}
/**
* 获取匹配的关键词和命中次数
* @param text
* @return
*/
public static Map<String, Integer> matchWords(String text) {
Map<String, Integer> wordMap = new HashMap<>();
int len = text.length();
for (int i = 0; i < len; i++) {
int wordLength = checkWord(text, i);
if (wordLength > 0) {
String word = text.substring(i, i + wordLength);
// 添加关键词匹配次数
if (wordMap.containsKey(word)) {
wordMap.put(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
i += wordLength - 1;
}
}
return wordMap;
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("**");
list.add("**");
initMap(list);
String content="我是一个好人,并不会卖**,也不操练***,我真的不卖**";
Map<String, Integer> map = matchWords(content);
System.out.println(map);
}
}
3.图片文字识别
什么是OCR?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
| 方案 | 说明 |
|---|---|
| 百度OCR | 收费 |
| Tesseract-OCR | Google维护的开源OCR引擎,支持Java,Python等语言调用 |
| Tess4J | 封装了Tesseract-OCR ,支持Java调用 |
3.1Tess4j案例
3.1.1.创建项目导入tess4j对应的依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.1.1</version>
</dependency>
3.1.2.导入中文字体库, 把资料中的tessdata文件夹拷贝到自己的工作空间下(这里我放到MinIo了)
3.1.3.编写测试类进行测试
package com.heima.tess4j;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import java.io.File;
public class Application {
public static void main(String[] args) {
try {
//获取本地图片
File file = new File("D:\\26.png");
//创建Tesseract对象
ITesseract tesseract = new Tesseract();
//设置字体库路径
tesseract.setDatapath("D:\\workspace\\tessdata");
//中文识别
tesseract.setLanguage("chi_sim");
//执行ocr识别
String result = tesseract.doOCR(file);
//替换回车和tal键 使结果为一行
result = result.replaceAll("\\r|\\n","-").replaceAll(" ","");
System.out.println("识别的结果为:"+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
注:记得下载MinIo里的图片的时候别忘了调用它自己下载的方法,先下下来审核,如果是本地的话当我没说

 浙公网安备 33010602011771号
浙公网安备 33010602011771号