
推荐模型NeuralCF:原理介绍与TensorFlow2.0实现
1. 简介
NCF是协同过滤在神经网络上的实现——神经网络协同过滤。由新加坡国立大学与2017年提出。
我们知道,在协同过滤的基础上发展来的矩阵分解取得了巨大的成就,但是矩阵分解得到低维隐向量求内积是线性的,而神经网络模型能带来非线性的效果,非线性可以更好地捕捉用户和物品空间的交互特征。因此可以极大地提高协同过滤的效果。
另外,NCF处理的是隐式反馈数据,而不是显式反馈,这具有更大的意义,在实际生产环境中隐式反馈数据更容易得到。
本篇论文展示了NCF的架构原理,以及实验过程和效果。
2. 网络架构和原理
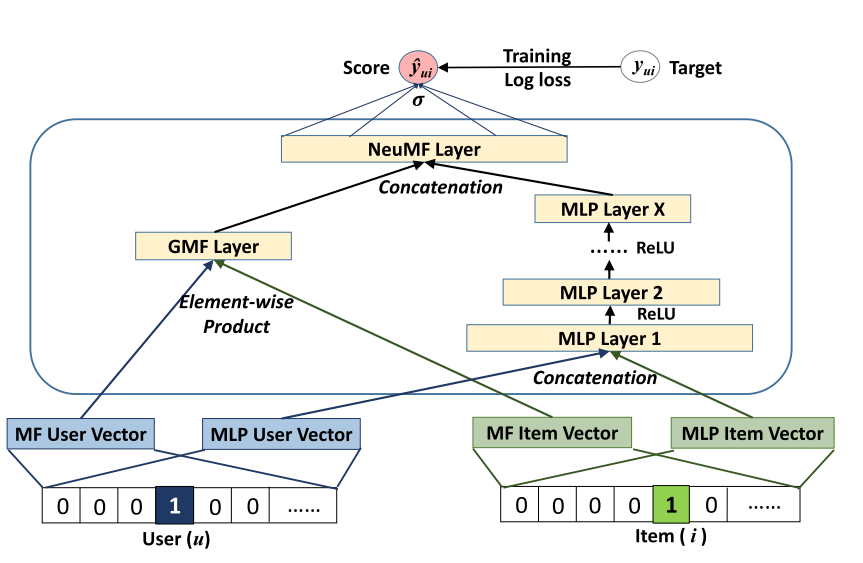
2.1 输入
由于这篇文章的主要目的是协同过滤,因此输入为user和item的id,把他们进行onehot编码,然后使用单层神经网络进行降维即Embedding化。作为通用框架,其输入应该不限制与id类信息,可以是上下文环境,可以是基于内容的特征,基于邻居的特征等辅助信息。
为啥图中使用两组user和item的向量?一组走向GMF一组走向MLP?——后续分析
2.2 MLP部分
可以发现MLP部分为多层感知机的堆叠,每一层的输出就作为下一层的输入,文中描述最后一层Layer X表示模型的容量能力,所以越大容量就越大。
这部分可以捕获用户-物品的交互非线性关系,增强模型的表达能力。
每层的非线性通过ReLu(符合生物学特征;能带来稀疏性;符合稀疏数据,比tanh效果好一点)来激活,可以防止sigmoid带来的梯度消失问题
2.3 GMF部分
NCF其实是MF的一个通用化框架,去掉MLP部分,如果添加一层element-product(上图左侧),就是用户-物品隐向量的内积。同时NeuMF Layer仅仅使用线性激活函数,则最终的结果 就是MF的一个输出。如果激活函数是一般的函数,那么MF可以被称为GMF,Generalized Matrix Factorization广义矩阵分解。
2.4目标函数
如果是矩阵分解模型,常处理显式反馈数据,这样可以将目标函数定义为平方误差损失(MSE),然后进行回归预测:
隐式反馈数据,MSE不好用,因此隐式反馈数据的标记不是分值而是用户是否观测过物品,即1 or 0.其中,1不代表喜欢,0也不代表不喜欢,仅仅是否有交互行为。
因此,预测分数就可以表示为用户和物品是否相关,表征相关的数学定义为概率,因此要限制网络输出为[0,1],则使用概率函数如,sigmoid函数。目的是求得最后一层输出的概率最大,即使用似然估计的方式来进行推导:
连乘无法光滑求导,且容易导致数值下溢,因此两边取对数,得到对数损失取负数可以最小化 损失函数,
2.5 GMF和MLP的结合
GMF,它应用了一个线性内核来模拟潜在的特征交互;MLP,使用非线性内核从数据中学习交互函数。接下来的问题是:我们如何能够在NCF框架下融合GMF和MLP,使他们能够相互强化,以更好地对复杂的用户-项目交互建模?一个直接的解决方法是让GMF和MLP共享相同的嵌入层(Embedding Layer),然后再结合它们分别对相互作用的函数输出。这种方式和著名的神经网络张量(NTN,Neural Tensor Network)有点相似。然而,共享GMF和MLP的嵌入层可能会限制融合模型的性能。例如,它意味着,GMF和MLP必须使用的大小相同的嵌入;对于数据集,两个模型的最佳嵌入尺寸差异很大,使得这种解决方案可能无法获得最佳的组合。为了使得融合模型具有更大的灵活性,我们允许GMF和MLP学习独立的嵌入,并结合两种模型通过连接他们最后的隐层输出。
黑体字部分解释了输入部分使用两组Embedding的作用。
3. 代码实现
使用TensorFlow2.0和Keras API 构造各个模块层,通过继承Layer和Model的方式来实现。
1. 输入数据
为了简化模型输入过程中的参数,使用一个namedtuple定义稀疏向量的关系,如下
from collections import namedtuple
# 使用具名元组定义特征标记:由名字 和 域组成,类似字典但是不可更改,轻量便捷
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
2. 定义Embedding层
与上篇Deep Crossing使用ReLu激活函数自定义单层神经网络作为Embedding不同的是,使用TF自带的Embedding模块。
好处是:自定义的Embedding需要自己对类别变量进行onehot后才能输入,而自带Embedding只需要定义好输入输入的格式,就能自动实现降维效果,简单方便。
class SingleEmb(keras.layers.Layer):
def __init__(self, emb_type, sparse_feature_column):
super().__init__()
# 取出sparse columns
self.sparse_feature_column = sparse_feature_column
self.embedding_layer = keras.layers.Embedding(sparse_feature_column.vocabulary_size,
sparse_feature_column.embedding_dim,
name=emb_type + "_" + sparse_feature_column.name)
def call(self, inputs):
return self.embedding_layer(inputs)
3. 定义NCF整个网络
class NearalCF(keras.models.Model):
def __init__(self, sparse_feature_dict, MLP_layers_units):
super().__init__()
self.sparse_feature_dict = sparse_feature_dict
self.MLP_layers_units = MLP_layers_units
self.GML_emb_user = SingleEmb('GML', sparse_feature_dict['user_id'])
self.GML_emb_item = SingleEmb('GML', sparse_feature_dict['item_id'])
self.MLP_emb_user = SingleEmb('MLP', sparse_feature_dict['user_id'])
self.MLP_emb_item = SingleEmb('MLP', sparse_feature_dict['item_id'])
self.MLP_layers = []
for units in MLP_layers_units:
self.MLP_layers.append(keras.layers.Dense(units, activation='relu')) # input_shape=自己猜
self.NeuMF_layer = keras.layers.Dense(1, activation='sigmoid')
def call(self, X):
#输入X为n行两列的数据,第一列为user,第二列为item
GML_user = keras.layers.Flatten()(self.GML_emb_user(X[:,0]))
GML_item = keras.layers.Flatten()( self.GML_emb_item(X[:,1]))
GML_out = tf.multiply(GML_user, GML_item)
MLP_user = keras.layers.Flatten()(self.MLP_emb_user(X[:,0]))
MLP_item = keras.layers.Flatten()(self.MLP_emb_item(X[:,1]))
MLP_out = tf.concat([MLP_user, MLP_item],axis=1)
for layer in self.MLP_layers:
MLP_out = layer(MLP_out)
# emb的类型为int64,而dnn之后的类型为float32,否则报错
GML_out = tf.cast(GML_out, tf.float32)
MLP_out = tf.cast(MLP_out, tf.float32)
concat_out = tf.concat([GML_out, MLP_out], axis=1)
return self.NeuMF_layer(concat_out)
3. 模型验证
-
数据处理
按照论文正负样本标记为1一个观测样本,4个未观测样本,所以需要训练测试集的处理
# 数据处理
# train是字典形式,不然不太容易判断是否包含u,i对
def get_data_instances(train, num_negatives, num_items):
user_input, item_input, labels = [],[],[]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(num_items)
while train.__contains__((u, j)): # python3没有has_key方法
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
# 这个字典,当数据量较大时,可以使用scipy.sparse 的dok_matrix:sparse.dok_matrix
def get_data_dict(data, lst=['userId', 'movieId']):
d = dict()
for idx, row in data[lst].iterrows():
d[(row[0], row[1])] = 1
return d
得到数据(可使用movielen数据)
train, test = train_test_split(data, test_size=0.1,random_state=13)
train_dict, test_dict = get_data_dict(train), get_data_dict(test)
train_set, test_set = get_data_instances(train_dict, 4, train['movieId'].max()), get_data_instances(test_dict, 4, test['movieId'].max())
- 模型验证
# 这里没特意设置验证集,因此直接使用array来喂给模型
BATCH = 128
X = np.array([train_set[0], train_set[1]]).T # 根据模型的输入为两列,因此转置
# 模型验证
feature_columns_dict = {'user_id': SparseFeat('user_id', data.userId.nunique(), 8),
'item_id': SparseFeat('item_id', data.movieId.nunique(), 8)}
# 模型
model = NearalCF(feature_columns_dict, [16, 8, 4])
model.compile(loss=keras.losses.binary_crossentropy,
optimizer=keras.optimizers.Adam(0.001),
metrics=['acc'])
model.fit(X,
np.array(train_set[2]),
batch_size=BATCH,
epochs=5, verbose=2, validation_split=0.1)
out:
Train on 408384 samples, validate on 45376 samples
Epoch 5/5
408384/408384 - 10s - loss: 1708.5975 - acc: 0.8515 - val_loss: 277.9610 - val_acc: 0.8635
X_test = np.array([test_set[0], test_set[1]]).T
loss, acc = model.evaluate(X_test, np.array(test_set[2]),batch_size=BATCH, verbose=0)
print(loss, acc) # 276.6405882021682 0.86309004
4. 说明
-
tf.data.Dataset的数据处理方式已经在前面文章提到了,这里换种思路和方式,在划分数据集的时候不划分验证集,而是使用array的形式输入后,在fit阶段划分。如果是Dataset的格式则不能进行fit阶段划分,详情见官网fit的函数说明。 -
文章中所计算的评估指标是HR@10和NDCG@10,并对BPR,ALS等经典的传统方法进行了比较发现最终的NCF的效果是最好的;
-
文章中高斯分布初始化参数,推荐使用的是pre-training的GMF和MLP模型,预训练过程优化方法为Adam方法,在合并为NCF过程后,由于未保存参数之外的动量信息,所以使用SGD方法优化;
-
在合并为NCF时,还有一个可调节超参数是GML_out和MLP_out的系数\(\alpha\),pre-training时为0.5,本篇博客直接使用了0.5且没有使用预训练方式,仅仅展示了使用tf构造NCF模型的过程。
-
MLP的Layer X越大模型的容量越大,越容易导致过拟合,至于使用多少 视实验情况而定。文章中使用了
[8, 16, 32, 64]来测试。 -
与DeepCrossing和AutoRec的深层一样,越深效果越好。
4. 小结
本篇文章介绍了神经协同过滤的网络架构和代码实践,并对文章实验中的细节部分加以说明。
NCF模型混合了MLP和GML二者的特性,具有更强的特征组合以及非线性表达的能力。
要注意的是模型结构不是越复杂越好,要防止过拟合,这部分并没有使用Dropout和参数初始化的正则化,因为模型相对简单。
NCF模型的局限性在于协同过滤思想中只用用户-物品的id信息,尽管可以添加辅助信息,这些需要后续的研究人员进行扩展,同时文章中说损失是基于pointwise的损失 可能也可以尝试pairwise的损失。

