

高并发缓存中间件Redis
https://tech.meituan.com/2020/07/01/kv-squirrel-cellar.html
美团万亿级 KV 存储架构与实践
阿里云 redis文档
https://help.aliyun.com/product/26340.html为什么要学redis,架构图解
无redis架构
对于Web来说,用户量和访问量增一定程度上推动项目技术和架构的更迭和进步。
可能会有以下的一些状况:
页面并发量和访问量并不多,MySQL足以支撑自己逻辑业务的发展。
那么其实可以不加缓存。最多对静态页面进行缓存即可。
页面的并发量显著增多,数据库有些压力,并且有些数据更新频率较低反复被查询或者查询速度较慢。
那么就可以考虑使用缓存技术优化。
对高命中的对象存到key-value形式的Redis中,那么,如果数据被命中,那么可以不经过效率很低的db。
从高效的redis中查找到数据。
当然,可能还会遇到其他问题,你还通过静态页面缓存页面、cdn加速、甚至负载均衡这些方法提高系统并发量。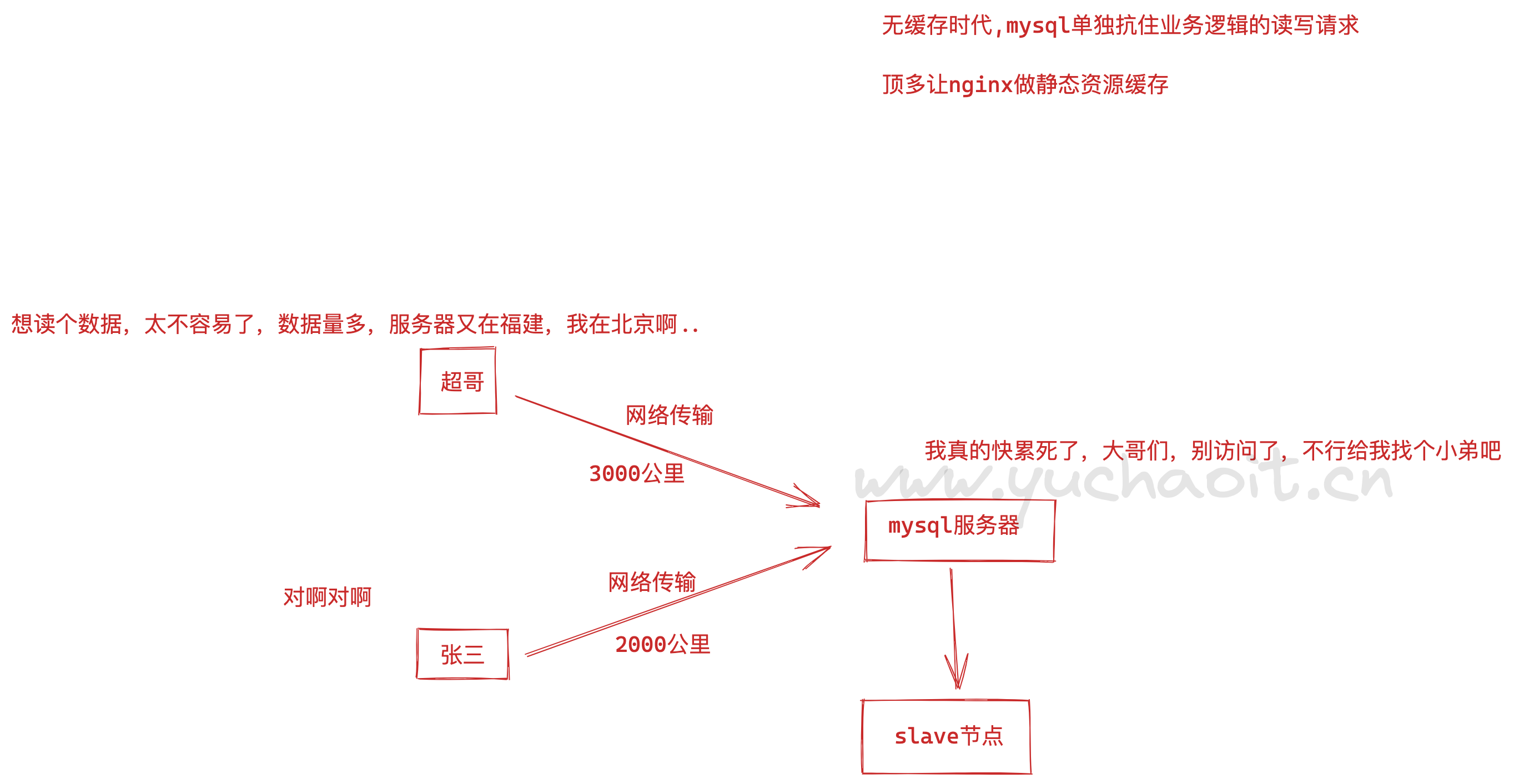
使用redis缓存架构
缓存适用于高并发的场景,提升服务容量。
主要是将从经常被访问的数据或者查询成本较高从慢的介质中存到比较快的介质中,比如从硬盘—>内存。
我们知道大多数关系数据库是基于硬盘读写的,其效率和资源有限,而redis是基于内存的,其读写速度差别差别很大。
当并发过高关系数据库性能达到瓶颈时候,就可以策略性将常访问数据放到Redis提高系统吞吐和并发量。
对于常用网站和场景,关系数据库主要可能慢在两个地方:
1.读写IO性能较差
2.一个数据可能通过较大量计算得到
所以使用缓存能够减少磁盘IO次数和关系数据库的计算次数。
读取上速度快也从两个方面体现:
1.基于内存,读写较快
2.使用哈希算法直接定位结果不需要计算,直接key-value获取结果
所以对于像样的,有点规模的网站,缓存是很必要的,而Redis无疑是最好的选择之一。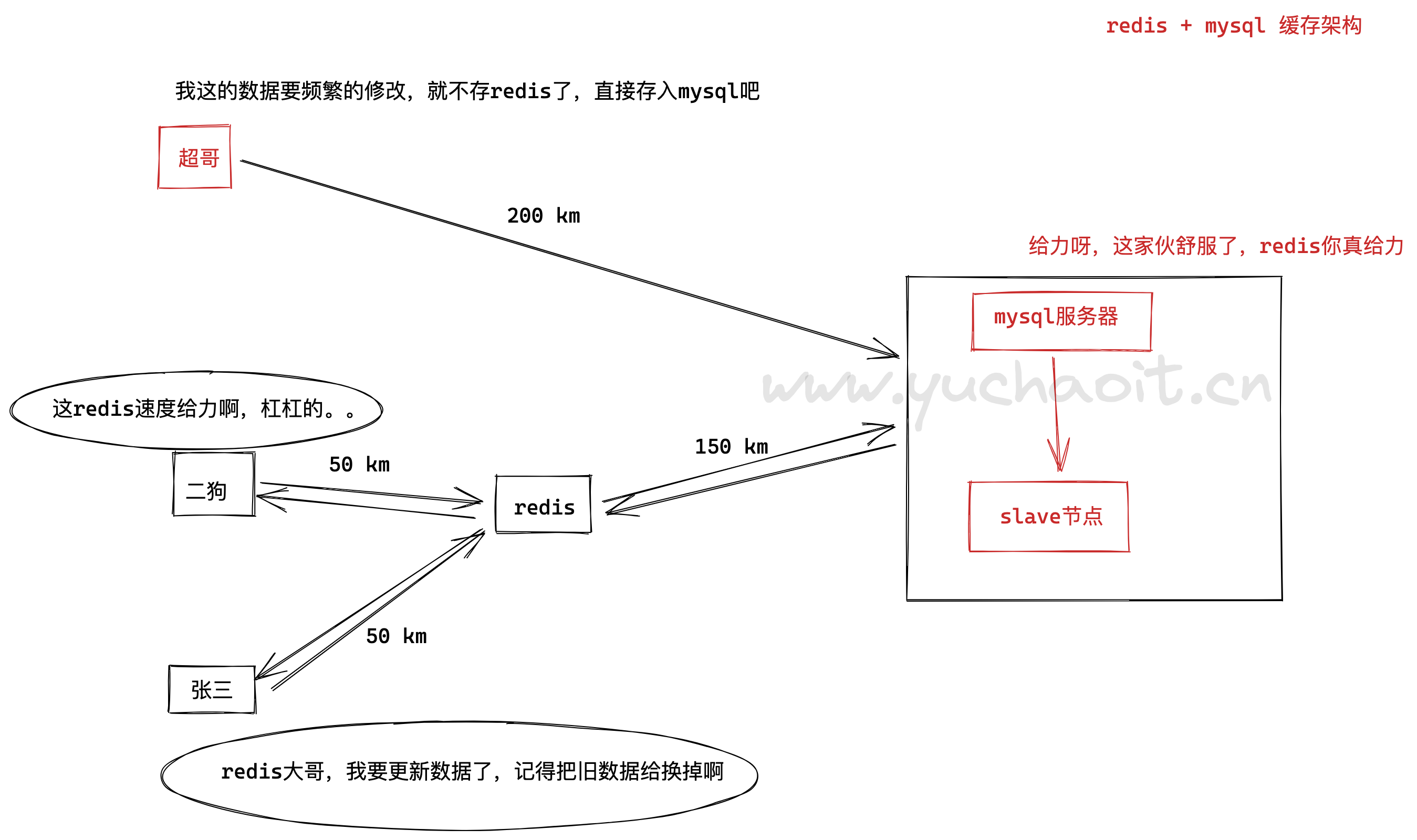
但是使用缓存,也要注意诸多问题,多引入了一个环节,必然会引发更多问题
1. 缓存不适用于,数据一致性特别高,以及频繁更新数据的场景
2. 缓存也不适用于并发量并不多的,加入缓存,不但架构更难维护,浪费资源,且让项目更臃肿,可能redis也会出问题
3. 引入缓存,就要考虑对k-v的数据如何设计1.关系型、非关系数据库
关系型数据库、mysql、oracle、postgreSQL
非关系 redis mongoDB ES
nosql、not only sql、不仅仅是sql,是不同于传统关系型数据库的统称。
特点是 key-value 这种键值对存储数据的形式,而不是mysql这样库、表结构存储形式。
noSQL用于处理高速读写的数据存储场景
如用户访问行为,用户地理定位数据、电商秒杀类的订单数据(超高的瞬时并发请求)
视频网的弹幕信息、直播间的刷礼物、点赞等功能
LOL、王者的玩家巅峰排行榜的数据
微博的最新评论、最新点赞
这类要求高并发,高读写的业务场景,数据都是存储在redis里,提高APP响应速度,让用户更好的体验2.redis特性
Redis是一种支持key-value等多种数据结构的存储系统。
可用于缓存,事件发布或订阅,高速队列等场景。
支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
1.软件源码高质量,运行速度快、C语言开发、单线程架构
2.支持丰富数据类型,面对各种业务场景
字符串、哈希、列表、集合、有序集合
3.功能丰富,可以实现如
计数器--------点赞、评论数
key过期功能-------购物车订单
消息队列
发布订阅---聊天室
4.支持多种语言客户端
php,java,golang,python
5.支持数据持久化
运行时的数据都在内存,可以基于RDB,AOF持久化到磁盘里,或混合持久化
6.内置高可用架构
主从复制
哨兵
集群3.redis面试重点-应用场景
redis用的如何?你们应用在哪些场景?
1.缓存
key过期特性
- 用户登录网站的session信息写入redis、过期后自动删除
- 商城的优惠券过期
- 短信验证码的过期
2.排行榜
数据类型的列表、有序集合
- 抖音点赞点击量
- 直播间打赏老板排行榜
3.计数器
- 博客阅读量
- 视频播放次数
- 在线观看人数
- 评论最新数量
- 点赞、点踩
4. 社交网络
redis的集合数据类型
- 粉丝
- 共同好友 / 可能认识的人
- 兴趣爱好 / 同兴趣的人
- 用户注册、账号是否已存在
5.消息队列
redis的列表类型
- ELK日志的缓存
- 聊天记录
6. 发布订阅
- 粉丝关注通知
- 粉丝群消息发布
因此,你猜猜全中国哪家公司是redis大户?没错,这不明显是微博么,是世界级,数一数二的redis大户。4.redis安装部署
官网
https://redis.io/
版本选择
2.x 老掉牙
3.x 还有很多公司用,开始支持redis-cluster
4.x 混合持久化玩法
5.x 快手等互联网公司更新到这了
6.x 最新版安装部署redis5
1. 目录规划
mkdir -p /data/soft/
mkdir -p /opt/redis_6379/{conf,logs,pid}
mkdir -p /data/redis_6379/
# 2.下载redis5
[root@db-51 ~]#cd /data/soft/
[root@db-51 /data/soft]#wget http://download.redis.io/releases/redis-5.0.7.tar.gz
# 踩坑记录安装依赖
[root@db-51 /opt/redis]#yum install gcc make -y
# 3.解压部署
[root@db-51 /data/soft]#tar -zxf redis-5.0.7.tar.gz -C /opt/
[root@db-51 /data/soft]#
[root@db-51 /data/soft]#ln -s /opt/redis-5.0.7/ /opt/redis
[root@db-51 /data/soft]#
[root@db-51 /data/soft]#cd /opt/redis
[root@db-51 /opt/redis]#make MALLOC=libc && make install
# 4.若要进行编译测试,这是一个对编译环境检查,编译结果的好习惯
yum install tcl tcl-devel -y
make test
看到这个结果就很nice
\o/ All tests passed without errors!
Cleanup: may take some time... OK
make[1]: Leaving directory `/opt/redis-5.0.7/src'redis配置文件
mkdir -p /opt/redis_6379/{conf,logs,pid}
mkdir -p /data/redis_6379
cat > /opt/redis_6379/conf/redis_6379.conf <<'EOF'
daemonize yes
bind 127.0.0.1 10.0.0.51
port 6379
pidfile /opt/redis_6379/pid/redis_6379.pid
logfile /opt/redis_6379/logs/redis_6379.log
EOF启动redis
检查可执行命令
[root@db-51 /opt/redis]#ls -l /usr/local/bin/redis-*
-rwxr-xr-x 1 root root 353808 Aug 5 18:42 /usr/local/bin/redis-benchmark
-rwxr-xr-x 1 root root 4058352 Aug 5 18:42 /usr/local/bin/redis-check-aof
-rwxr-xr-x 1 root root 4058352 Aug 5 18:42 /usr/local/bin/redis-check-rdb
-rwxr-xr-x 1 root root 799288 Aug 5 18:42 /usr/local/bin/redis-cli
lrwxrwxrwx 1 root root 12 Aug 5 18:42 /usr/local/bin/redis-sentinel -> redis-server
-rwxr-xr-x 1 root root 4058352 Aug 5 18:42 /usr/local/bin/redis-server
启动服务端
[root@db-51 /opt/redis]#redis-server /opt/redis_6379/conf/redis_6379.conf
检查
[root@db-51 /opt/redis]#netstat -tunlp|grep redis
tcp 0 0 10.0.0.51:6379 0.0.0.0:* LISTEN 8744/redis-server 1
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 8744/redis-server 1
[root@db-51 /opt/redis]#ps -ef|grep redi[s]
root 8744 1 0 18:56 ? 00:00:00 redis-server 127.0.0.1:6379登录redis
[root@db-51 /opt/redis]#redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
127.0.0.1:6379> set name wwww.yuchaoit.cn
OK
127.0.0.1:6379> get name
"wwww.yuchaoit.cn"
127.0.0.1:6379>关闭redis
建议方式
127.0.0.1:6379> SHUTDOWN
not connected>
方式二
[root@db-51 /opt/redis]#redis-server /opt/redis_6379/conf/redis_6379.conf
[root@db-51 /opt/redis]#
[root@db-51 /opt/redis]#redis-cli shutdown
[root@db-51 /opt/redis]#!ps
ps -ef|grep redi[s]
不推荐方式
kill
pkill
killall配置systemctl管理脚本
停止redis
[root@db-51 /opt/redis]#redis-cli shutdown
授权配置
groupadd redis -g 1025
useradd redis -u 1025 -g 1025 -M -s /sbin/nologin
chown -R redis.redis /opt/redis*
chown -R redis.redis /data/redis*
# redis.service脚本
cat > /usr/lib/systemd/system/redis.service <<'EOF'
[Unit]
Description=redis service by www.yuchaoit.cn
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/local/bin/redis-server /opt/redis_6379/conf/redis_6379.conf --supervised systemd
ExecStop=/usr/local/bin/redis-cli shutdown
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
# 重载systemd服务,启动
systemctl daemon-reload
systemctl restart redis
[root@db-51 /opt/redis]#systemctl status redis
● redis.service - redis service by www.yuchaoit.cn
Loaded: loaded (/usr/lib/systemd/system/redis.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2022-08-05 19:13:02 CST; 9s ago
Main PID: 8933 (redis-server)
CGroup: /system.slice/redis.service
└─8933 /usr/local/bin/redis-server 127.0.0.1:6379
Aug 05 19:13:02 db-51 systemd[1]: Starting redis service by www.yuchaoit.cn...
Aug 05 19:13:02 db-51 systemd[1]: Started redis service by www.yuchaoit.cn.redis日志警告处理
在redis日志里,可以看到启动后的一些问题
优化1
30 8933:C 05 Aug 2022 19:13:02.761 * supervised by systemd, will signal readiness
31 8933:M 05 Aug 2022 19:13:02.762 # You requested maxclients of 10000 requiring at least 10032 max file descriptors.
32 8933:M 05 Aug 2022 19:13:02.762 # Server can't set maximum open files to 10032 because of OS error: Operation not perm itted.
33 8933:M 05 Aug 2022 19:13:02.762 # Current maximum open files is 4096. maxclients has been reduced to 4064 to compensat e for low ulimit. If you need higher maxclients increase 'ulimit -n'.修改方法
1. 给systemd服务添加参数,修改redis可打开的文件数
[root@db-51 /opt/redis]#cat /usr/lib/systemd/system/redis.service
[Unit]
Description=redis service by www.yuchaoit.cn
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
LimitNOFILE=65536
Type=notify
ExecStart=/usr/local/bin/redis-server /opt/redis_6379/conf/redis_6379.conf --supervised systemd
ExecStop=/usr/local/bin/redis-cli shutdown
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
[root@db-51 /opt/redis]#
2.重启
[root@db-51 /opt/redis]#systemctl daemon-reload
[root@db-51 /opt/redis]#systemctl restart redisulimit系统优化参数
ulimit主要是用来限制进程对资源的使用情况的,它支持各种类型的限制,常用的有:
内核文件的大小限制
进程数据块的大小限制
Shell进程创建文件大小限制
可加锁内存大小限制
常驻内存集的大小限制
打开文件句柄数限制
分配堆栈的最大大小限制
CPU占用时间限制用户最大可用的进程数限制
Shell进程所能使用的最大虚拟内存限制
[root@db-51 /opt/redis]#ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14996
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 14996
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited优化2
虚拟内存相关警告
37 8933:M 05 Aug 2022 19:13:02.763 # WARNING overcommit_memory is set to 0! Background save may fail under low memory con dition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysct l vm.overcommit_memory=1' for this to take effect.解决
修改系统内核参数
# 写入内核参数配置文件
sysctl -w vm.overcommit_memory=1
sysctl -p优化3
关闭THP大内存页
38 8933:M 05 Aug 2022 19:13:02.763 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.解决
echo never > /sys/kernel/mm/transparent_hugepage/enabled
优化4
9099:M 05 Aug 2022 19:23:46.721 * Running mode=standalone, port=6379.
9099:M 05 Aug 2022 19:23:46.721 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
9099:M 05 Aug 2022 19:23:46.721 # Server initialized
根据日志提示,修改即可
[root@db-51 ~]#echo "511" > /proc/sys/net/core/somaxconn
[root@db-51 ~]#sysctl -w net.core.somaxconn=4096
net.core.somaxconn = 4096最后重启redis即可
配置文件解释
daemonize no #默认redis前台运行,修改yes放入后台守护进程运行,pid写入redis.pid
pidfile /var/run/redis_6379.pid # 运行多redis实例的话,需要区分pid、配置文件
port 6379 # 默认redis链接端口
tcp-backlog 511 # 在高并发系统中,你需要设置一个较高的tcp-backlog来避免客户端连接速度慢的问题(三次握手的速度)。
bind 127.0.0.1 0.0.0.0 # 设置redis运行地址,走内网,还是允许公网访问
timeout 0 # 客户端连接的超时时间 ,0 是关闭功能详解配置
# Redis 配置文件.
# 请注意,为了读取配置文件,必须以文件路径作为第一个参数启动Redis:
# ./redis-server /path/to/redis.conf
# 内存大小单位
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# 单位不区分大小写,因此 1GB 1Gb 1gB 是一样的.
################################## INCLUDES ###################################
# 在此处包含一个或多个其他配置文件。如果您有一个标准模板可用于所有Redis服务器,但还需要自定义一些服务器设置。
#
# “include”不会被来自admin或Redis Sentinel的命令“CONFIG REWRITE”重写。
# 由于Redis始终使用最后处理的行为作为配置指令的值,因此最好将include放在此文件的开头,以避免在运行时覆盖配置更改。
#
# 如果你要使用includes来覆盖配置选项,最好将include作为最后一行。
#
# include /path/to/local.conf
# include /path/to/other.conf
################################## MODULES #####################################
# 启动时加载指定模块,如果服务器无法加载模块,它将中止。 这里可以使用多个loadmodule指令。
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
################################## NETWORK #####################################
# 默认情况下,如果未指定“bind”配置指令,则Redis将监听来自服务器上可用的所有端口的连接。
# 可以使用“bind”配置指令仅监听一个或多个指定的IP地址。
#
# Examples:
#
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1 ::1
#
# ~~~ WARNING ~~~ 如果运行Redis的计算机直接暴露于Internet,则绑定到所有接口是危险的,并且会将实例暴露给Internet上的每个人。
# 因此,默认情况下,我们不会注释以下绑定指令,这意味着Redis只能接受来自指定ip的客户端的连接
#
# IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
# JUST COMMENT THE FOLLOWING LINE.
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
bind 127.0.0.1
# 保护模式是一层安全保护,以避免在Internet上打开的Redis实例被访问和利用。
#
# 当保护模式打开的情况下,如果:
#
# 1) 服务器未使用“bind”指令显式绑定到一组地址。
# 2) 没有配置密码。
#
# 服务器仅接受来自IPv4和IPv6环回地址127.0.0.1和:: 1以及Unix域套接字的客户端的连接。
#
# 默认情况下保护模式是开启的。 只有在希望其他主机的客户端即使未配置任何身份验证,仍要连接到Redis时,应该禁用此选项并且不使用“bind”指令明确列出一组特定的接口。
protected-mode yes
# 接受指定端口上的连接,默认为6379
# 如果指定了端口0,则Redis不会侦听TCP套接字。
port 6379
# TCP连接最大积压数
#
# 在大量客户端连接的情况下,应该提高该值,以免客户端连接慢。
# 但该值受系统内核参数的限制,包括 somaxconn 和 tcp_max_syn_backlog。
tcp-backlog 511
# Unix socket.
#
# 指定将用于监听传入连接的Unix套接字的路径。 没有默认值,因此Redis在未指定时不会侦听unix套接字。
#
# unixsocket /tmp/redis.sock
# unixsocketperm 700
# 当连接的客户端连续空闲指定时间后,就断开该连接。指定值为0时禁用超时机制。
timeout 0
# TCP keepalive.
# 周期性检测客户端是否可用
# 如果非零,则在没有通信的情况下使用SO_KEEPALIVE向客户端发送TCP ACK。
# 此选项的合理值为300秒
tcp-keepalive 300
################################# GENERAL #####################################
# 设定是否以守护进程启动服务(默认是no),守护进程会生成 PID 文件 /var/run/redis_6379.pid。
daemonize no
# If you run Redis from upstart or systemd, Redis can interact with your
# supervision tree. Options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting Redis into SIGSTOP mode
# supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET
# supervised auto - detect upstart or systemd method based on
# UPSTART_JOB or NOTIFY_SOCKET environment variables
# Note: these supervision methods only signal "process is ready."
# They do not enable continuous liveness pings back to your supervisor.
supervised no
# 启用守护进程模式时,会生成该文件。
pidfile /var/run/redis_6379.pid
# 指定日志级别
# 日志级别有以下选项:
# debug (适用于开发/测试)
# verbose (很少但很有用的信息)
# notice (信息适中,推荐选项)
# warning (只记录非常重要/关键的消息)
loglevel notice
# 指定保存日志的文件。请注意,如果您使用标准输出进行日志记录,守护进程情况下,日志将发送到/dev/null
logfile ""
# 要启用日志记录到系统记录器,只需将“syslog-enabled”设置为yes,并可选择更新其他syslog参数以满足您的需要。
# syslog-enabled no
# 指定syslog标识。
# syslog-ident redis
# 指定syslog工具。 必须是USER或LOCAL0-LOCAL7之间。
# syslog-facility local0
# 设置数据库数量,默认为16. 默认数据库是 DB 0, 你可以使用 SELECT <dbid> 选择使用的数据库。
# 数据库编号在 0 到 'databases'-1
databases 16
# 启动日志中是否显示redis logo,默认是开启的
always-show-logo yes
################################ SNAPSHOTTING ################################
#
# 数据持久化:
#
# save <seconds> <changes>
#
# 指定时间间隔后,如果数据变化达到指定次数,则导出生成快照文件
#
# 示例如下:
#
# 900 秒(15 分钟)内至少有1个key被修改
# 300 秒(5分钟)内至少有10个key被修改
# 60 秒(1分钟)内至少有10000个key被修改
#
#
# 如果指定 save "",则相当于清除前面指定的所有 save 设置
#
# save ""
save 900 1
save 300 10
save 60 10000
# 在启用快照的情况下(指定了有效的 save),如果遇到某次快照生成失败(比如目录无权限),
# 之后的数据修改就会被禁止。这有利于用户及早发现快照保存失败,以免更多的数据不能持久化而丢失的风险。
# 当快照恢复正常后,数据的修改会自动开启。
# 如果你有其他的持久化监控,你可以关闭本机制。
stop-writes-on-bgsave-error yes
# 快照中字符串值是否压缩
rdbcompression yes
# 如果开启,校验和会被放在文件尾部。这将使快照数据更可靠,但会在快照生成与加载时降低大约 10% 的性能,追求高性能时可关闭该功能。
rdbchecksum yes
# 指定保存快照文件的名称
dbfilename dump.rdb
# 指定保存快照文件的目录,AOF(Append Only File) 文件也会生成到该目录
dir ./
################################# REPLICATION #################################
# 主从复制。 使用 replicaof 使Redis实例成为另一台Redis服务器的副本。
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis复制是异步的,但是如果master与一定数量的副本无法连接,则可以将主服务器配置为停止接受写入。
# 2) 如果再较短时间内与副本失去了连接,当Redis副本与master重新连接时可以执行部分重新同步。因此就要求配置一个合理的 backlog 值。
# 3) 当副本节点重新连接到master时,重新同步复制时自动的,不需要用户干预。
#
# replicaof <masterip> <masterport>
# 如果主服务器受密码保护(使用下面的“requirepass”配置指令),则可以在启动复制同步过程之前告知副本服务器进行身份验证,否则主服务器将拒绝副本服务器请求。
#
# masterauth <master-password>
# 当从库与主库连接中断,或者主从同步正在进行时,如果有客户端向从库读取数据:
# - yes: 从库答复现有数据,可能是旧数据(初始从未修改的值则为空值)
# - no: 从库报错“正在从主库同步”
replica-serve-stale-data yes
# 从库只允许读取
replica-read-only yes
# 无盘同步
#
# -------------------------------------------------------
# WARNING: DISKLESS REPLICATION IS EXPERIMENTAL CURRENTLY
# -------------------------------------------------------
# 新连接(包括连接中断后重连)的从库不可采用增量同步,只能采用全量同步(RDB文件由主库传给从库),有两种传递方式:
# - 磁盘形式:主库创建子进程,子进程写入磁盘 RDB 文件,再由父进程立即传给从库;
# - 无磁盘形式:主库创建子进程,子进程把 RDB 文件直接写入从库的 SOCKET 连接。
repl-diskless-sync no
# 无盘同步传输间隔(秒)
repl-diskless-sync-delay 5
# 从库向主库PING的间隔(秒)
#
# repl-ping-replica-period 10
# 以下选项设置复制超时:
#
# 1) 从副本的角度来看,在SYNC期间批量传输I / O.
# 2) 从副本(data,ping)的角度来看master超时。
# 3) 从主服务器的角度来看副本超时(REPLCONF ACK ping)。
#
# 确保此值大于为repl-ping-replica-period指定的值非常重要,否则每次主服务器和副本服务器之间的流量较低时都会检测到超时。
#
# repl-timeout 60
# 在SYNC之后禁用副本套接字上的TCP_NODELAY?
#
# 如果选择“yes”,Redis将使用较少数量的TCP数据包和较少的带宽将数据发送到副本。 但这可能会增加数据在副本端出现的延迟,使用默认配置的Linux内核最多可达40毫秒。
#
# 如果选择“no”,则副本上显示的数据延迟将减少,但将使用更多带宽进行复制。
#
# 默认情况下,我们针对低延迟进行优化,但是在非常高的流量条件下,或者当主节点和副本很多时,将其设置为 yes 或许是较好的选择
repl-disable-tcp-nodelay no
# 设置复制积压大小(backlog)。 积压是一个缓冲区,当副本断开连接一段时间后会累积副本数据,因此当副本想要再次重新连接时,通常不需要完全重新同步,只需要部分重新同步就足够了