

(十)selenium实现微博高级搜索信息爬取
1.selenium模拟登陆
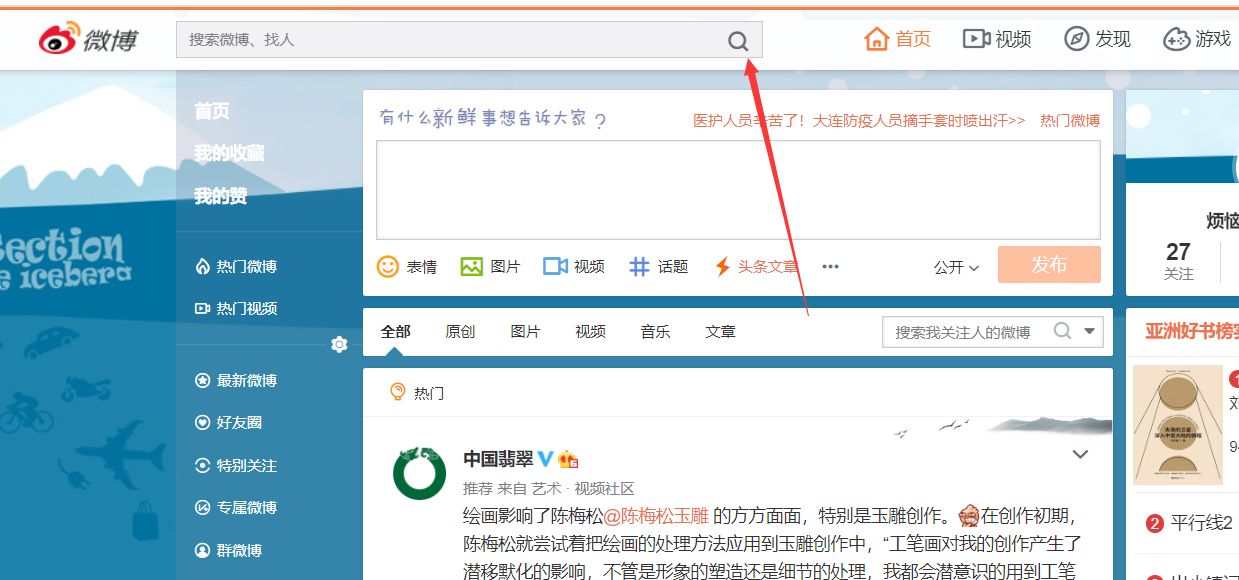
2.定位进入高级搜索页面
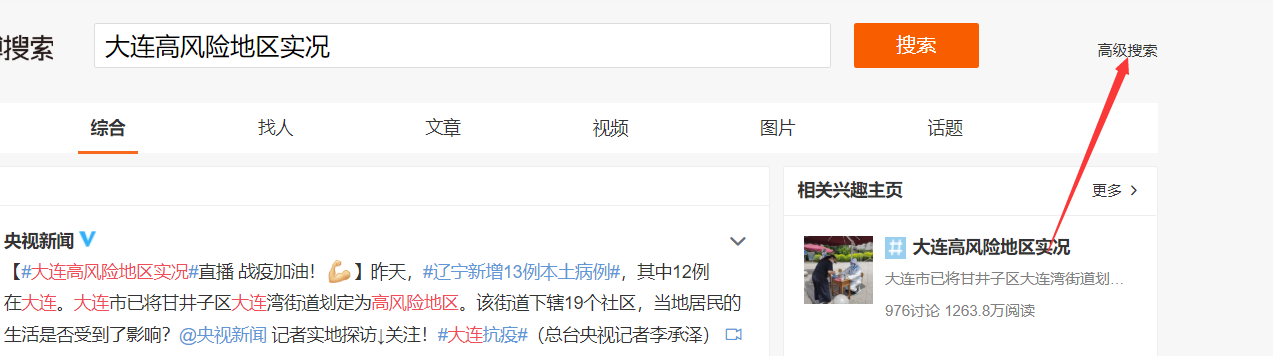
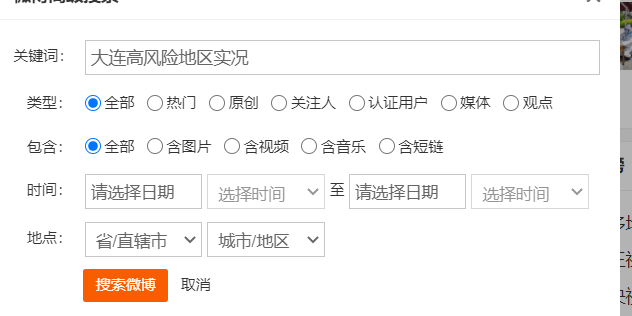
3.对高级搜索进行定位,设置。
4.代码实现
import time from selenium import webdriver from lxml import etree from selenium.webdriver import ChromeOptions import requests from PIL import Image from hashlib import md5 from selenium.webdriver.support.select import Select headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36', } # 超级鹰 class Chaojiying_Client(object): """超级鹰源代码""" def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() # 输入用户名 密码 option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) url = 'https://www.weibo.com/' bro = webdriver.Chrome(executable_path='./chromedriver.exe',options=option) bro.maximize_window() bro.get(url=url) time.sleep(10) # 视网速而定 bro.find_element_by_id('loginname').send_keys('你的账号') time.sleep(2) bro.find_element_by_css_selector(".info_list.password input[node-type='password']").send_keys( "你的密码") time.sleep(1) #识别验证码 def recognize(bro): bro.save_screenshot('weibo.png') pic = bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/a/img') location = pic.location size = pic.size rangle = (location['x'] * 1.25, location['y'] * 1.25, (location['x'] + size['width']) * 1.25, (location['y'] + size['height']) * 1.25) i = Image.open('./weibo.png') code_img_name = 'code.png' # 裁剪文件的文件名称 frame = i.crop(rangle) # 根据指定区域进行裁剪 frame.save(code_img_name) chaojiying = Chaojiying_Client('超级鹰账号', '密码', ' 905993') im = open('./code.png', 'rb').read() result = chaojiying.PostPic(im, 3005)['pic_str'] return result # 输入验证码 # 微博第一次点击登陆可能不成功 确保成功登陆 for i in range(5): try: bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/div/input').send_keys(recognize(bro)) bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[6]/a').click() except Exception: continue time.sleep(5) # 进入高级搜索页面 bro.find_element_by_xpath('//div[@class="gn_header clearfix"]/div[2]/a').click() bro.find_element_by_xpath('//div[@class="m-search"]/div[3]/a').click() # 填入关键词 key_word = bro.find_element_by_xpath('//div[@class="m-layer"]/div[2]/div/div[1]/dl//input') key_word.clear() key_word.send_keys('雾霾') # 填入地点 province = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[1]') city = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[2]') Select(province).select_by_visible_text('陕西') Select(city).select_by_visible_text('西安') # 填入时间 # 起始 bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[1]').click() # 点击input输入框 sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]') Select(sec_1).select_by_visible_text('一月') sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]') Select(sec_2).select_by_visible_text('2019') bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[3]').click() # 起始日期 # 终止 bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[2]').click() # 点击input输入框 sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]') Select(sec_1).select_by_visible_text('一月') #月份 sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]') Select(sec_2).select_by_visible_text('2019') # 年份 bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[6]').click() # 日期 sec_3 = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//select[2]') # 点击input输入框 Select(sec_3).select_by_visible_text('8时') # 小时 bro.find_element_by_xpath('//div[@class="btn-box"]/a[1]').click() # 爬取用户ID 发帖内容 时间 客户端 评论数 转发量 点赞数 并持久化存储 page_num = 1 with open('2019.txt','a',encoding='utf-8') as f: while page_num<=50: page_text = bro.page_source tree = etree.HTML(page_text) div_list = tree.xpath('//div[@id="pl_feedlist_index"]/div[2]/div') for div in div_list: try: user_id = div.xpath('./div/div[1]/div[2]/div[1]/div[2]/a[1]/text()')[0] # 用户id flag = div.xpath('./div/div[1]/div[2]/p[3]') if not flag: content = div.xpath('./div/div[1]/div[2]/p[1]')[0].xpath('string(.)') # 内容 time = div.xpath('./div/div[1]/div[2]/p[2]/a/text()')[0] # 发布时间 client = div.xpath('./div/div[1]/div[2]/p[2]/a[2]/text()')[0] else: content = div.xpath('./div/div[1]/div[2]/p[2]')[0].xpath('string(.)') # 内容 time = div.xpath('./div/div[1]/div[2]/p[3]/a/text()')[0] # 发布时间 client = div.xpath('./div/div[1]/div[2]/p[3]/a[2]/text()')[0] #客户端 up=div.xpath('./div/div[2]/ul/li[4]/a')[0].xpath('string(.)') #点赞数 transfer = div.xpath('./div/div[2]/ul/li[2]/a/text()')[0] # 转发量 comment = div.xpath('./div/div[2]/ul/li[3]/a/text()')[0] # 评论数 f.write('\n'+user_id+'\n'+content+'\n'+time+client+' '+transfer+' '+comment+' '+'赞'+up+'\n'+'\n') except IndexError: continue if page_num ==1: # 第一页 元素位置不同 进行判断 bro.find_element_by_xpath('//div[@class="m-page"]/div/a').click() else: bro.find_element_by_xpath('//div[@class="m-page"]/div/a[@class="next"]').click() page_num+=1
