(八)分布式爬取58同城二手房信息
- 实现流程
- 创建一个工程
- 创建一个基于CrawlSpider的爬虫文件
- 修改当前的爬虫文件:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 将start_urls和allowed_domains进行注释
- 添加一个新属性:redis_key = 'sun' 可以被共享的调度器队列的名称
- 编写数据解析相关的操作
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 修改配置文件settings
- 指定使用可以被共享的管道:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 指定调度器:
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器:
REDIS_HOST = 'ip'
REDIS_PORT = 'port'
- redis相关操作配置:
- 配置redis的配置文件:
- linux或者mac:redis.conf
- windows:redis.windows.conf
- 代开配置文件修改:
- 将bind 127.0.0.1进行删除
- 关闭保护模式:protected-mode yes改为no
- 结合着配置文件开启redis服务
- redis-server 配置文件
- 启动客户端:
- redis-cli
- 执行工程:
- scrapy runspider xxx.py
- 向调度器的队列中放入一个起始的url:
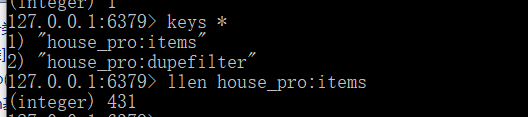
- 调度器的队列在redis的客户端中
- lpush xxx(redis_key即共享的调度器) www.xxx.com
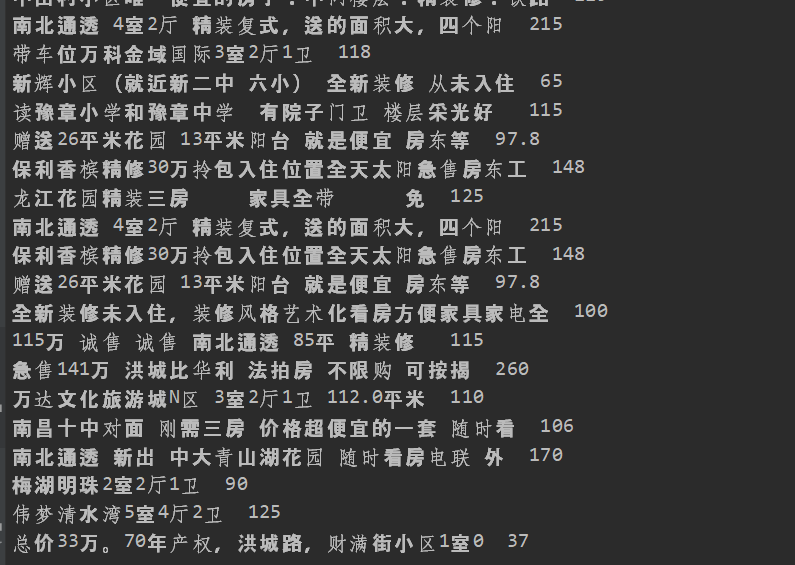
- 爬取到的数据存储在了redis的proName:items这个数据结构中
将同一份代码多台电脑同时执行,任意一个客户端将人物放入调度器的队列后,机群共同爬取。
代码实现
爬虫文件:house_pro.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider,Rule from scrapy_redis.spiders import RedisCrawlSpider from house_58.items import House58Item class HouseProSpider(RedisCrawlSpider): name = 'house_pro' # allowed_domains = ['www.xxx.com'] # start_urls = ['www.xxx.com'] redis_key = 'house' rules = ( Rule(LinkExtractor(allow=r'/ershoufang/pn2/\?utm_source=market&spm=u-2d2yxv86y3v43nkddh1\.BDPCPZ_BT'), callback='parse_item', follow=True), ) def parse_item(self, response): print('working.....') li_list = response.xpath('/html/body/div[5]/div[5]/div[1]/ul/li') for li in li_list: item = House58Item() title = li.xpath('./div[2]/h2/a/text()').extract_first() price = li.xpath('./div[3]/p//text()').extract_first() item['title'] = title item['price'] = price print(title,price) yield item
settings.py
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400 } # 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据 SCHEDULER_PERSIST = True REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379
Redis
服务端
客户端
运行代码