


二、模块机制
1,CommonJS规范

CommonJS的模块规范
模块引用
var math = require('math')
模块定义
//math.js exports.add = function () { var sum = 0, i=0, args = arguments, l = args.length; while(i < 1) { sum += args[i++] } return sum; }
在另一个文件中,通过require()方法引入模块后,就能调用定义的属性或方法了
//program.js var math = require('math'); exports.increment = function (val) { return math.add(val,1); }
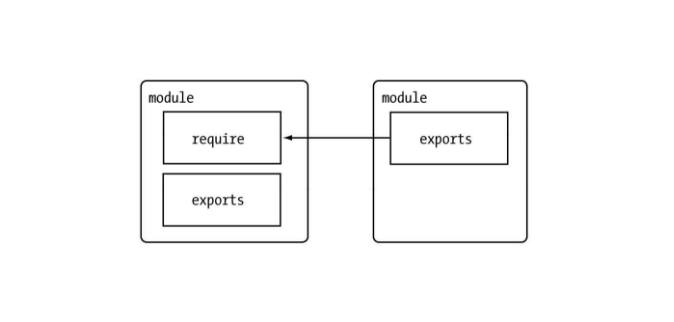
每个模块具有独立的空间,它们互不干扰,在引用时也显得干净利落
模块标识
传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以 . 、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js。
2,Node的模块实现
在Node中引入模块,需要经历如下三步:
- 路径分析
- 文件定位
- 编译执行
在Node中,模块分为核心模块(Node提供的模块)和文件模块(用户编写的模块)
核心模块是在源代码编译过程中编译进了二进制执行文件,在Node进程启动时,部分核心模块就被直接加载进内存,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略,并且在路径分析中优先判断,所以它的加载速度最快。
文件模块在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
模块加载过程:
2.1优先从缓存加载
Node对引入过的模块都会进行缓存,以减少二次引入的开销,Node缓存的是编译和执行之后的对象。
不论核心模块还是文件模块,require()对相同模块的二次加载一律采用缓存优先的方式,不同之处在于核心模块的缓存检查先于文件模块。
2.2路径分析和文件定位
因为标识符有几种形式,对于不同的标识符,模块查找和定位有不同程度的差异
2.2.1模块标识符分析
1,核心模块,如http、fs、path等。优先级仅次于缓存加载,它在Node的源代码编译过程中已经编译为二进制代码,其加载过程最快。
2,路径形式的文件模块。以 . 、.. 和 / 开始的标识符,都被当做文件模块来处理。在分析模块时,require()会将路径转为真实路径,并且以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。
3,自定义模块。非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式。这类模块查找最费时,也是最慢的一种。
模块路径是Node在定位文件模块的具体文件时指定的查找策略,具体表现为一个路径组成的数组。
(1)创建module_path.js,内容为console.log(moudule_path);。
(2)将其放到任意一个目录中,执行node module_path.js。
在window下,得到一个数组输出:
['c:\\nodejs\\node_modules','c:\\node_modules']
可以看出,模块路径的生成规则如下:
- 当前目录下的node_modules目录
- 父目录下的node_modules目录
- 父目录的父目录下的node_modules目录
- 沿路径向上逐级递归,直到根目录下的node_modules目录
2.2.2文件定位
从缓存加载的优化策略使得二次引入时不需要路径分析、文件定位和编译执行的过程,大大提高了再次加载模块的效率。
但在文件定位过程中,还有一些细节需要注意,包括文件扩展名的分析、目录和包的处理。
(1)文件扩展名分析
require()在分析标识符的过程中,会出现标识符中不包含文件扩展名的情况。Node会按.js、.json、.node的次序补足扩展名,依次尝试。
在尝试的过程中,需要调用fs模块同步阻塞式的判断文件是否存在。因为Node是单线程的,所以会引起性能问题。小诀窍是:①如果是.json或者.node文件,在传给require()的时候加上扩展名②同步配合缓存,可以大幅度缓解Node单线程中阻塞式调用的缺陷。
(2)目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,此时Node会将目录当做一个包来处理。
在这个过程中,Node对CommonJS包规范进行了一定程度的支持。首先,Node在当前目录下查找package.json,通过JSON.parse解析出包描述对象,从中取出main属性指定的文件名进行定位。如果缺少扩展名将会进入扩展名分析的步骤。
如果main指定的文件名错误,或者没有package.json文件,Node会将index当做默认文件名依次查找index.js、index.json、index.node
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数据都被遍历完毕依然没有找到目标文件,则会抛出查找失败的异常。
2.3模块编译
在Node中,每个文件模块都是一个对象,编译和执行是引入文件模块的最后一个阶段,定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同,具体如下:
(1).js文件:通过fs模块同步读取文件后编译执行
(2).node文件:用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
(3).json文件:通过fs模块同步读取文件后,用JSON.parse()解析返回结果
(4)其余扩展名文件:它们都被当做.js文件载入
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
