


Google App Engine技术架构资料大盘点
从前,有一个“伤不起”的人(就是我啦)在园子里分享过Google的架构,老是老了点,但对不少新手还是有点帮助的。今天看到几篇有关Google App Engine的技术架构文章,觉得比那个“伤不起”孩子总结得要全得多,索性就全部弄过来,一起分享给大家,没看到过的同学赶紧惊喜一下吧,看到过了的同学也假装惊喜一下嘛,呵呵。
全部文章有点长,请耐心看下去,相信程序员都是有耐心的,除了我.......
另外文章的作者是吴朱华,要转载的同学别忘了署上他的大名。下面就开始了。
一、Google的核心技术
在切入Google App Engine之前,首先会对Google的核心技术和其整体架构进行分析,以帮助大家之后更好地理解Google App Engine的实现。
本篇将主要介绍Google的十个核心技术,而且可以分为四大类:
- 分布式基础设施:GFS、Chubby 和 Protocol Buffer。
- 分布式大规模数据处理:MapReduce 和 Sawzall。
- 分布式数据库技术:BigTable 和数据库 Sharding。
- 数据中心优化技术:数据中心高温化、12V电池和服务器整合。
分布式基础设施
GFS
由于搜索引擎需要处理海量的数据,所以Google的两位创始人Larry Page和Sergey Brin在创业初期设计一套名为"BigFiles"的文件系统,而GFS(全称为"Google File System")这套分布式文件系统则是"BigFiles"的延续。
首先,介绍它的架构,GFS主要分为两类节点:
- Master节点:主要存储与数据文件相关的元数据,而不是Chunk(数据块)。元数据包括一个能将64位标签映射到数据块的位置及其组成文件 的表格,数据块副本位置和哪个进程正在读写特定的数据块等。还有Master节点会周期性地接收从每个Chunk节点来的更新("Heart- beat")来让元数据保持最新状态。
- Chunk节点:顾名思义,肯定用来存储Chunk,数据文件通过被分割为每个默认大小为64MB的Chunk的方式存储,而且每个Chunk有唯一一个64位标签,并且每个Chunk都会在整个分布式系统被复制多次,默认为3次。
下图就是GFS的架构图:
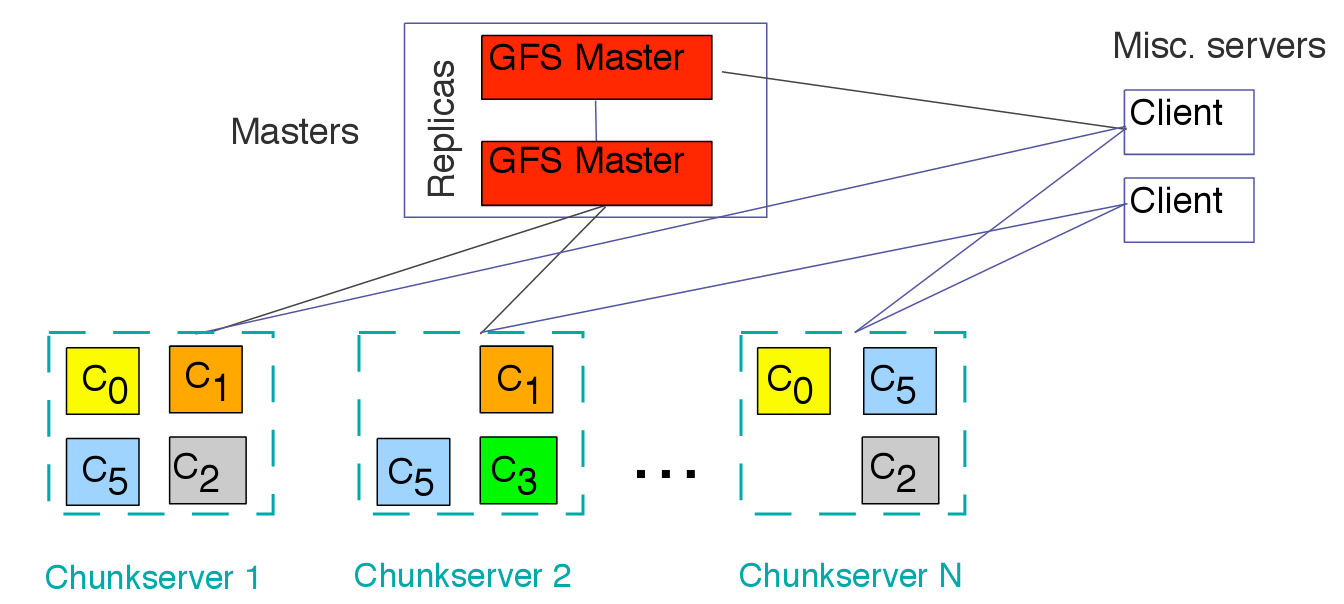
图1. GFS的架构图(参片[15])
接着,在设计上,GFS主要有八个特点:
- 大文件和大数据块:数据文件的大小普遍在GB级别,而且其每个数据块默认大小为64MB,这样做的好处是减少了元数据的大小,能使Master节点能够非常方便地将元数据放置在内存中以提升访问效率。
- 操作以添加为主:因为文件很少被删减或者覆盖,通常只是进行添加或者读取操作,这样能充分考虑到硬盘线性吞吐量大和随机读写慢的特点。
- 支持容错:首先,虽然当时为了设计方便,采用了单Master的方案,但是整个系统会保证每个Master都会有其相对应的复制品,以便于在 Master节点出现问题时进行切换。其次,在Chunk层,GFS已经在设计上将节点失败视为常态,所以能非常好地处理Chunk节点失效的问题。
- 高吞吐量:虽然其单个节点的性能无论是从吞吐量还是延迟都很普通,但因为其支持上千的节点,所以总的数据吞吐量是非常惊人的。
- 保护数据:首先,文件被分割成固定尺寸的数据块以便于保存,而且每个数据块都会被系统复制三份。
- 扩展能力强:因为元数据偏小,使得一个Master节点能控制上千个存数据的Chunk节点。
- 支持压缩:对于那些稍旧的文件,可以通过对它进行压缩,来节省硬盘空间,并且压缩率非常惊人,有时甚至接近90%。
- 用户空间:虽然在用户空间运行在运行效率方面稍差,但是更便于开发和测试,还有能更好利用Linux的自带的一些POSIX API。
现在Google内部至少运行着200多个GFS集群,最大的集群有几千台服务器,并且服务于多个Google服务,比如Google搜索。但由于 GFS主要为搜索而设计,所以不是很适合新的一些Google产品,比YouTube、Gmail和更强调大规模索引和实时性的Caffeine搜索引擎 等,所以Google已经在开发下一代GFS,代号为"Colossus",并且在设计方面有许多不同,比如:支持分布式Master节点来提升高可用性 并能支撑更多文件,Chunk节点能支持1MB大小的chunk以支撑低延迟应用的需要。
Chubby
简单的来说,Chubby 属于分布式锁服务,通过 Chubby,一个分布式系统中的上千个client都能够对于某项资源进行"加锁"或者"解锁",常用于BigTable的协作工作,在实现方面是通过 对文件的创建操作来实现"加锁",并基于著名科学家Leslie Lamport的Paxos算法。
Protocol Buffer
Protocol Buffer,是Google内部使用一种语言中立、平台中立和可扩展的序列化结构化数据的方式,并提供 Java、C++ 和 Python 这三种语言的实现,每一种实现都包含了相应语言的编译器以及库文件,而且它是一种二进制的格式,所以其速度是使用 XML 进行数据交换的10倍左右。它主要用于两个方面:其一是RPC通信,它可用于分布式应用之间或者异构环境下的通信。其二是数据存储方面,因为它自描述,而 且压缩很方便,所以可用于对数据进行持久化,比如存储日志信息,并可被Map Reduce程序处理。与Protocol Buffer比较类似的产品还有Facebook的 Thrift ,而且 Facebook 号称Thrift在速度上还有一定的优势。
分布式大规模数据处理
MapReduce
首先,在Google数据中心会有大规模数据需要处理,比如被网络爬虫(Web Crawler)抓取的大量网页等。由于这些数据很多都是PB级别,导致处理工作不得不尽可能的并行化,而Google为了解决这个问题,引入了 MapReduce这个编程模型,MapReduce是源自函数式语言,主要通过"Map(映射)"和"Reduce(化简)"这两个步骤来并行处理大规 模的数据集。Map会先对由很多独立元素组成的逻辑列表中的每一个元素进行指定的操作,且原始列表不会被更改,会创建多个新的列表来保存Map的处理结 果。也就意味着,Map操作是高度并行的。当Map工作完成之后,系统会先对新生成的多个列表进行清理(Shuffle)和排序,之后会这些新创建的列表 进行Reduce操作,也就是对一个列表中的元素根据Key值进行适当的合并。
下图为MapReduce的运行机制:
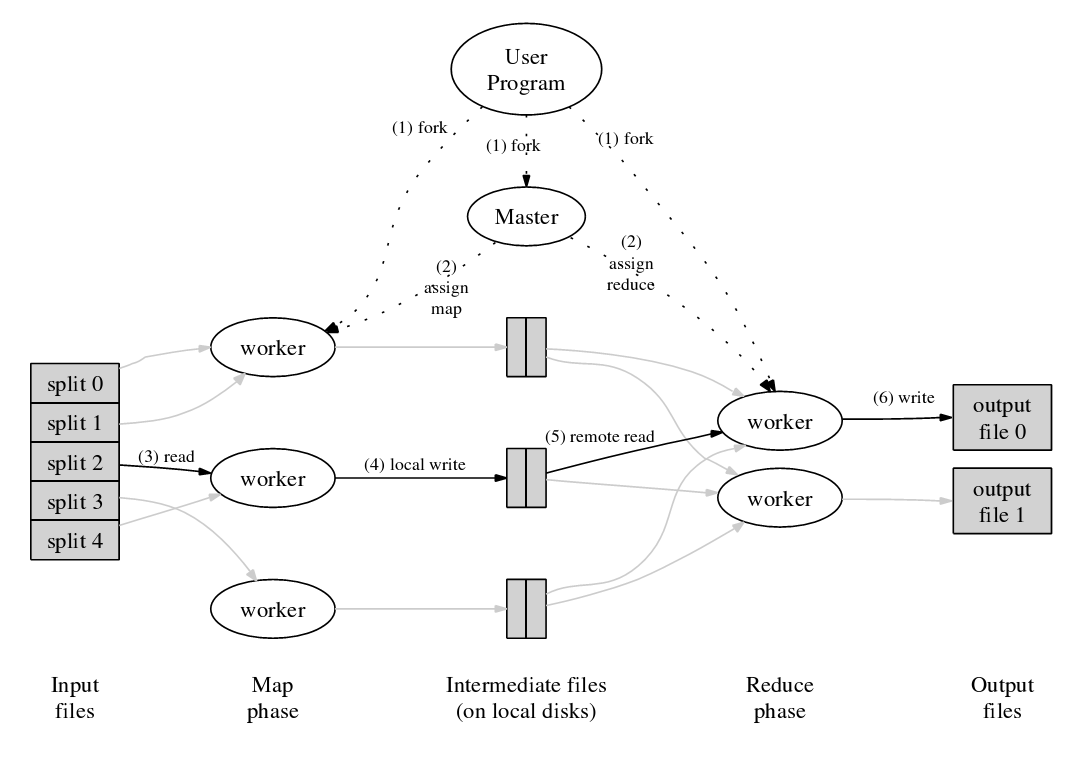
图2. MapReduce的运行机制(参[19])
接下来,将根据上图来举一个MapReduce的例子:比如,通过搜索Spider将海量的Web页面抓取到本地的GFS集群中,然后Index系 统将会对这个GFS集群中多个数据Chunk进行平行的Map处理,生成多个Key为URL,value为html页面的键值对(Key-Value Map),接着系统会对这些刚生成的键值对进行Shuffle(清理),之后系统会通过Reduce操作来根据相同的key值(也就是URL)合并这些键 值对。
最后,通过MapReduce这么简单的编程模型,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如自动并行化,负载均衡和机器宕 机处理等,这样将极大地简化程序员的开发工作。MapReduce可用于包括"分布grep,分布排序,web访问日志分析,反向索引构建,文档聚类,机 器学习,基于统计的机器翻译,生成Google的整个搜索的索引"等大规模数据处理工作。Yahoo也推出MapReduce的开源版本Hadoop,而 且Hadoop在业界也已经被大规模使用。
Sawzall
Sawzall可以被认为是构建在MapReduce之上的采用类似Java语法的DSL(Domain-Specific Language),也可以认为它是分布式的AWK。它主要用于对大规模分布式数据进行筛选和聚合等高级数据处理操作,在实现方面,是通过解释器将其转化 为相对应的MapReduce任务。除了Google的Sawzall之外,yahoo推出了相似的Pig语言,但其语法类似于SQL。
分布式数据库技术
BigTable
由于在Google的数据中心存储PB级以上的非关系型数据时候,比如网页和地理数据等,为了更好地存储和利用这些数据,Google开发了一套数 据库系统,名为"BigTable"。BigTable不是一个关系型的数据库,它也不支持关联(Join)等高级SQL操作,取而代之的是多级映射的数 据结构,并是一种面向大规模处理、容错性强的自我管理系统,拥有TB级的内存和PB级的存储能力,使用结构化的文件来存储数据,并每秒可以处理数百万的读 写操作。
什么是多级映射的数据结构呢?就是一个稀疏的,多维的,排序的Map,每个Cell由行关键字,列关键字和时间戳三维定位.Cell的内容是一个不 解释的字符串,比如下表存储每个网站的内容与被其他网站的反向连接的文本。 反向的URL com.cnn.www是这行的关键字;contents列存储网页内容,每个内容有一个时间戳,因为有两个反向连接,所以archor的Column Family有两列:anchor: cnnsi.com和anchhor:my.look.ca。Column Family这个概念,使得表可以轻松地横向扩展。下面是它具体的数据模型图:
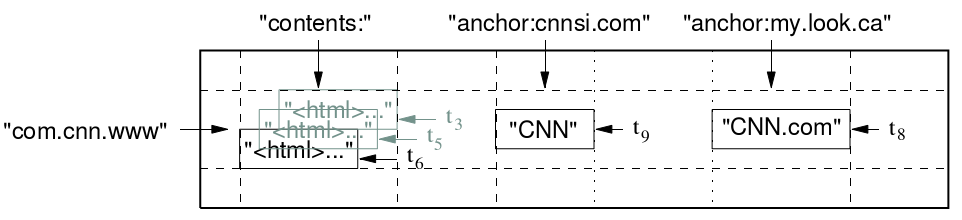
图3. BigTable数据模型图(参[4])
在结构上,首先,BigTable基于GFS分布式文件系统和Chubby分布式锁服务。其次BigTable也分为两部分:其一是Master节 点,用来处理元数据相关的操作并支持负载均衡。其二是tablet节点,主要用于存储数据库的分片tablet,并提供相应的数据访问,同时Tablet 是基于名为SSTable的格式,对压缩有很好的支持。
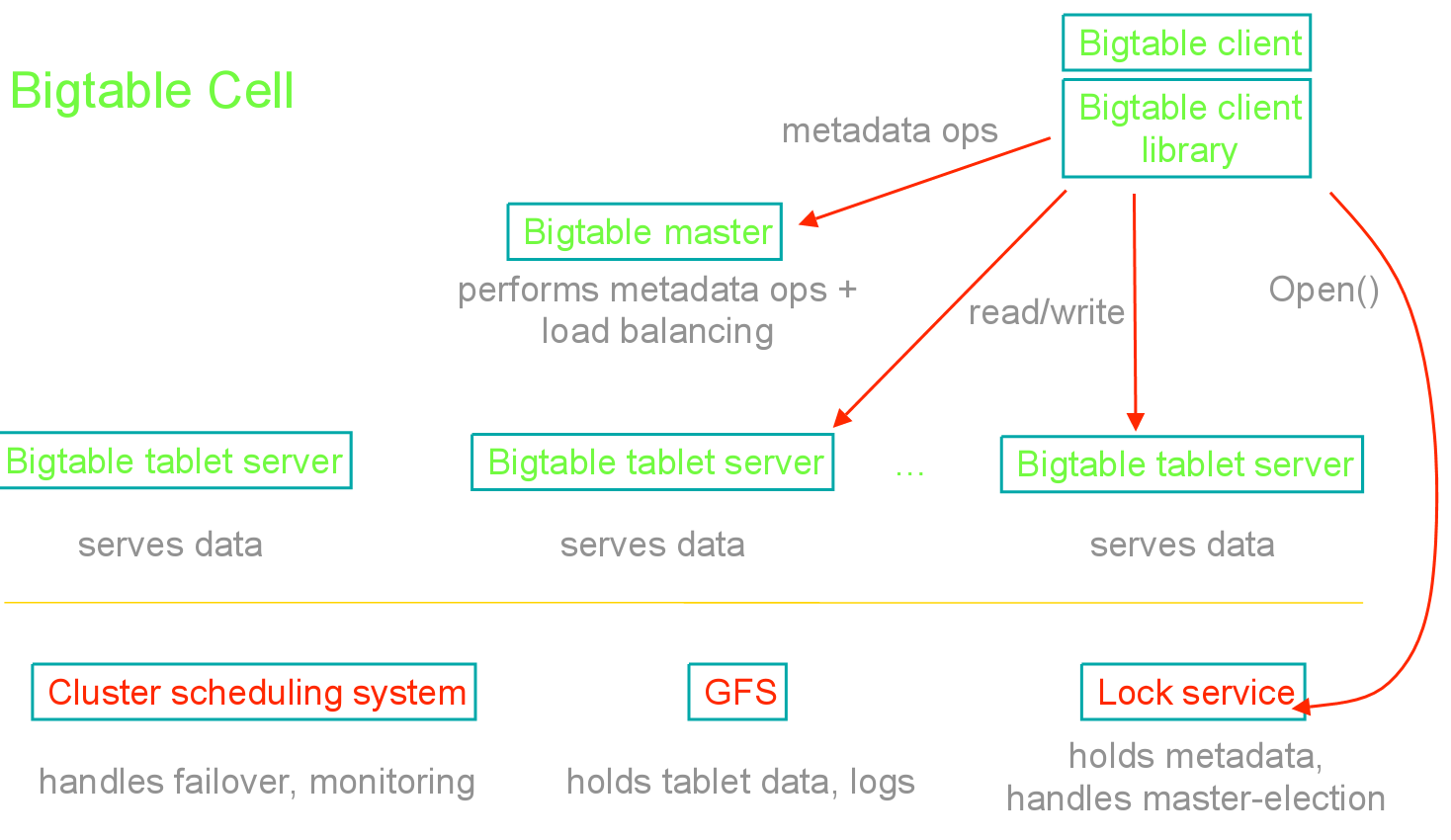
图4. BigTable架构图(参[15])
BigTable正在为Google六十多种产品和项目提供存储和获取结构化数据的支撑平台,其中包括有Google Print、 Orkut、Google Maps、Google Earth和Blogger等,而且Google至少运行着500个BigTable集群。
随着Google内部服务对需求的不断提高和技术的不断地发展,导致原先的BigTable已经无法满足用户的需求,而Google也正在开发下一代BigTable,名为"Spanner(扳手)",它主要有下面这些BigTable所无法支持的特性:
- 支持多种数据结构,比如table,familie,group和coprocessor等。
- 基于分层目录和行的细粒度的复制和权限管理。
- 支持跨数据中心的强一致性和弱一致性控制。
- 基于Paxos算法的强一致性副本同步,并支持分布式事务。
- 提供许多自动化操作。
- 强大的扩展能力,能支持百万台服务器级别的集群。
- 用户可以自定义诸如延迟和复制次数等重要参数以适应不同的需求。
数据库Sharding
Sharding就是分片的意思,虽然非关系型数据库比如BigTable在Google的世界中占有非常重要的地位,但是面对传统OLTP应用, 比如广告系统,Google还是采用传统的关系型数据库技术,也就是MySQL,同时由于Google所需要面对流量非常巨大,所以Google在数据库 层采用了分片(Sharding)的水平扩展(Scale Out)解决方案,分片是在传统垂直扩展(Scale Up)的分区模式上的一种提升,主要通过时间,范围和面向服务等方式来将一个大型的数据库分成多片,并且这些数据片可以跨越多个数据库和服务器来实现水平 扩展。
Google整套数据库分片技术主要有下面这些优点:
- 扩展性强:在Google生产环境中,已经有支持上千台服务器的MySQL分片集群。
- 吞吐量惊人:通过巨大的MySQL分片集群能满足巨量的查询请求。
- 全球备份:不仅在一个数据中心还是在全球的范围,Google都会对MySQL的分片数据进行备份,这样不仅能保护数据,而且方便扩展。
在实现方面,主要可分为两块:其一是在MySQL InnoDB基础上添加了数据库分片的技术。其二是在ORM层的Hibernate的基础上也添加了相关的分片技术,并支持虚拟分片(Virtual Shard)来便于开发和管理。同时Google也已经将这两方面的代码提交给相关组织。
数据中心优化技术
数据中心高温化
大中型数据中心的PUE(Power Usage Effectiveness)普遍在2左右,也就是在服务器等计算设备上耗1度电,在空调等辅助设备上也要消耗一度电。对一些非常出色的数据中心,最多也 就能达到1.7,但是Google通过一些有效的设计使部分数据中心到达了业界领先的1.2,在这些设计当中,其中最有特色的莫过于数据中心高温化,也就 是让数据中心内的计算设备运行在偏高的温度下,Google的能源方面的总监Erik Teetzel在谈到这点的时候说:"普通的数据中心在70华氏度(21摄氏度)下面工作,而我们则推荐80华氏度(27摄氏度)"。但是在提高数据中心 的温度方面会有两个常见的限制条件:其一是服务器设备的崩溃点,其二是精确的温度控制。如果做好这两点,数据中心就能够在高温下工作,因为假设数据中心的 管理员能对数据中心的温度进行正负1/2度的调节,这将使服务器设备能在崩溃点5度之内工作,而不是常见的20度之内,这样既经济,又安全。还有,业界传 言Intel为Google提供抗高温设计的定制芯片,但云计算界的顶级专家James Hamilton认为不太可能,因为虽然处理器也非常惧怕热量,但是与内存和硬盘相比还是强很多,所以处理器在抗高温设计中并不是一个核心因素。同时他也 非常支持使数据中心高温化这个想法,而且期望将来数据中心甚至能运行在40摄氏度下,这样不仅能节省空调方面的成本,而且对环境也很有利。
12V电池
由于传统的UPS在资源方面比较浪费,所以Google在这方面另辟蹊径,采用了给每台服务器配一个专用的12V电池的做法来替换了常用的UPS, 如果主电源系统出现故障,将由该电池负责对服务器供电。虽然大型UPS可以达到92%到95%的效率,但是比起内置电池的99.99%而言是非常捉襟见肘 的,而且由于能量守恒的原因,导致那么未被UPS充分利用的电力会被转化成热能,这将导致用于空调的能耗相应地攀升,从而走入一个恶性循环。同时在电源方 面也有类似的"神来之笔",普通的服务器电源会同时提供5V和12V的直流电。但是Google设计的服务器电源只输出12V直流电,必要的转换在主板上 进行,虽然这种设计会使主板的成本增加1美元到2美元,但是它不仅能使电源能在接近其峰值容量的情况下运行,而且在铜线上传输电流时效率更高。
服务器整合
谈到虚拟化的杀手锏时,第一个让人想到肯定是服务器整合,而且普遍能实现1:8的整合率来降低各方面的成本。有趣的是,Google在硬件方面也引 入类似服务器整合的想法,它的做法是在一个机箱大小的空间内放置两台服务器,这些做的好处有很多,首先,减小了占地面积。其次,通过让两台服务器共享诸如 电源等设备,来降低设备和能源等方面的投入。
二、Google App Engine简介
由于发布S3和EC2这两个优秀的云服务,使得Amazon已经率先在云计算市场站稳了脚跟,而身为云计算这个浪潮的发起者之一的Google肯定 不甘示弱,并在2008年四月份推出了Google App Engine这项PaaS服务,虽然现在无法称其为一个革命性的产品,但肯定是现在市面上最成熟,并且功能最全面的PaaS平台。
Google App Engine 提供一整套开发组件来让用户轻松地在本地构建和调试网络应用,之后能让用户在Google强大的基础设施上部署和运行网络应用程序,并自动根据应用所承受 的负载来对应用进行扩展,并免去用户对应用和服务器等的维护工作。同时提供大量的免费额度和灵活的资费标准。在开发语言方面,现支持Java和 Python这两种语言,并为这两种语言提供基本相同的功能和API。
功能
在功能上,主要有六个方面:
- 动态网络服务,并提供对常用网络技术的支持,比如SSL等 。
- 持久存储空间,并支持简单的查询和本地事务。
- 能对应用进行自动扩展和负载平衡。
- 一套功能完整的本地开发环境,可以让用户在本机上对App Engine进行开发和调试。
- 支持包括Email和用户认证等多种服务。
- 提供能在指定时间和定期触发事件的计划任务和能实现后台处理的任务队列。
使用流程
整个使用流程主要包括五个步骤:
- 下载SDK和IDE,并在本地搭建开发环境。
- 在本地对应用进行开发和调试。
- 使用GAE自带上传工具来将应用部署到平台上。
- 在管理界面中启动这个应用。
- 利用管理界面来监控整个应用的运行状态和资费。
由于本系列是专注于GAE的实现和设计两方面,所以不会对GAE的使用有非常深入地介绍,如果希望大家对GAE的使用方面有更深的理解,具体可以参看一下GAE的官方文档。
Google App Engine的主要组成部分
主要可分为五部分:
- 应用服务器:主要是用于接收来自于外部的Web请求。
- Datastore:主要用于对信息进行持久化,并基于Google著名的BigTable技术。
- 服务:除了必备的应用服务器和Datastore之外,GAE还自带很多服务来帮助开发者,比如:Memcache,邮件,网页抓取,任务队列,XMPP等。
- 管理界面:主要用于管理应用并监控应用的运行状态,比如,消耗了多少资源,发送了多少邮件和应用运行的日志等。
- 本地开发环境:主要是帮助用户在本地开发和调试基于GAE的应用,包括用于安全调试的沙盒,SDK和IDE插件等工具。
应用服务器
应用服务器依据其支持语言的不同而有不同的实现。
Python的实现
Python版应用服务器的基础就是普通的Python 2.5.2版的Runtime,并考虑在在未来版本中添加对Python 3的支持,但是因为Python 3对Python而言,就好比Java2之于Java1,跨度非常大,所以引入Python3的难度很大。在Web技术方面,支持诸如 Django,CherryPy,Pylons和Web2py等Python Web框架,并自带名为"WSGI"的CGI框架。虽然Python版应用服务器是基于标准的Python Runtime,但是为了安全并更好地适应App Engine的整体架构,对运行在应用服务器内的代码设置了很多方面的限制,比如不能加载用C编写Python模块和无法创建Socket等。
Java的实现
在实现方面,Java版应用服务器和Python版基本一致,也是基于标准的Java Web容器,而且选用了轻量级的Jetty技术,并跑在Java 6上。通过这个Web容器不仅能运行常见的Java Web 技术,包括Servlet,JSP,JSTL和GWT等,而且还能跑大多数常用的Java API(App Engine有一个The JRE Class White List来 定义那些Java API能在App Engine的环境中被使用)和一些基于JVM的脚本语言,例如JavaScript,Ruby或Scala等,但同样无法创建Socket和 Thread,或者对文件进行读写,也不支持一些比较高阶的API和框架,包括JDBC,JSF,Struts 2,RMI,JAX-RPC和Hibernate等。
Datastore
Datastore提供了一整套强大的分布式数据存储和查询服务,并能通过水平扩展来支撑海量的数据。但Datastore并不是传统的关系型数据 库,它主要以"Entity"的形式存储数据,一个Entity包括一个Kind(在概念上和数据库的Table比较类似)和一系列属性。
Datastore提供强一致性和乐观(optimistic)同步控制,而在事务方面,则支持本地事务,也就是在只能同一个Entity Group内执行事务。
在接口方面,Python版提供了非常丰富的接口,而且还包括名为GQL的查询语言,而Java版则提供了标准的JDO和JPA这两套API。
而且Google已经在今年的Google I/O大会上宣布将在未来的App Engine for Business套件中包含标准的SQL数据库服务,但现在还不确定这个SQL数据库的实现方式,是基于开源的MySQL技术,还是基于其私有的实现,这是一个问题。
服务
Memcache
Memcache是大中型网站所备的服务,主要用来在内存中存储常用的数据,而App Engine也包含了这个服务。有趣的是App Engine的Memcache也是由Brad Fitzpatrick开发。
URL抓取(Fetch)
App Engine的应用可以通过URL抓取这个服务抓取网上的资源,并可以这个服务来与其他主机进行通信。这样避免了应用在Python和Java环境中无法使用Socket的尴尬。
App Engine应用使用这个服务来利用Gmail的基础设施来发送电子邮件。
计划任务(Cron)
计划服务允许应用在指定时间或按指定间隔执行其设定的任务。这些任务通常称为Cron job。
图形
App Engine 提供了使用专用图像服务来操作图像数据的功能。图像服务可以调整图像大小,旋转、翻转和裁剪图像。它还能够使用预先定义的算法提升图片的质量。
用户认证
App Engine的应用可以依赖Google帐户系统来验证用户。App Engine还将支持OAuth。
XMPP
在App Engine上运行的程序能利用XMPP服务和其他兼容XMPP的IM服务(比如Google Talk)进行通信。
任务队列(Task Queue)
App Engine应用能通过在一个队列插入任务(以Web Hook的形式)来实现后台处理,而且App Engine会根据调度方面的设置来安排这个队列里面的任务执行。
Blobstore
因为Datastore最多支持存储1MB大小的数据对象,所以App Engine推出了Blobstore服务来存储和调用那些大于1MB但小于2G的二进制数据对象。
Mapper
Mapper可以认为就是"Map Reduce"中的Map,也就是能通过Mapper API对大规模的数据进行平行的处理,这些数据可以存储在Datastore或者Blobstore,但这个功能还处于内部开发阶段。
Channel
其实Channel就是我们常说的"Comet",通过Channel API能让应用将内容直接推至用户的浏览器,而不需常见的轮询。
除了Java版的Memcache,Email和URL抓取都是采用标准的API之外,其他服务无论是Java版还是Python版,其API都是私有的,但是提供了丰富和细致的文档来帮助用户使用。
管理界面
用了让用户更好地管理应用,Google提供了一整套完善的管理界面,地址是http://appengine.google.com/ ,而且只需用户的Google帐户就能登录和使用。下图为其截屏:
 图1. 管理界面(点击看大图)
图1. 管理界面(点击看大图)
使用这个管理界面可执行许多操作,包括创建新的应用程序,为这个应用设置域名,查看与访问数据和错误相关的日志,观察主要资源的使用状况。
本地开发环境
为了安全起见,本地开发环境采用了沙箱(Sandbox)模式,基本上和上面提到的应用服务器的限制差不多,比如无法创建Socket和 Thread,也无法对文件进行读写。Python版App Engine SDK是以普通的应用程序的形式发布,本地需要安装相应的Python Runtime,通过命令行方式启动Python版的Sandbox,同时也可以在安装有PyDev插件的Eclipse上启动。Java版App Engine SDK是以Eclispe Plugin形式发布,只要用户在他的Eclipse上安装这个Plugin,用户就能启动本地Java沙箱来开发和调试应用。
编程模型
因为App Engine主要为了支撑Web应用而存在,所以Web层编程模型对于App Engine也是最关键的。App Engine主要使用的Web模型是CGI,CGI全称为"Common Gateway Interface",它的意思非常简单,就是收到一个请求,起一个进程或者线程来处理这个请求,当处理结束后这个进程或者线程自动关闭,之后是不断地重 复这个流程。由于CGI这种方式每次处理的时候,都要重新起一个新的进程或者线程,可以说在资源消耗方面还是很厉害的,虽然有线程池(Thread Pool)这样的优化技术。但是由于CGI在架构上的简单性使其成为GAE首选的编程模型,同时由于CGI支持无状态模式,所以也在伸缩性方面非常有优 势。而且App Engine的两个语言版本都自带一个CGI框架:在Python平台为WSGI。在Java平台则为经典的Servlet。最近,由于App Engine引入了计划任务和任务队列这两个特性,所以App Engine已经支持计划任务和后台进程这两种编程模型。
限制和资费
首先,谈一下App Engine的使用限制,具体请看下表:
| 类别 | 限制 |
| 每个开发者所拥有的项目 | 10个 |
| 每个项目的文件数 | 1000个 |
| 每个项目代码的大小 | 150MB |
| 每个请求最多执行时间 | 30秒 |
| Blobstore(二进制存储)的大小 | 1GB |
| HTTP Response的大小 | 10MB |
| Datastore中每个对象的大小 | 1MB |
表1. App Engine的使用限制
虽然这些限制对开发者是一种障碍,但对App Engine这样的多租户环境而且却是非常重要的,因为如果一个租户的应用消耗过多的资源的话,将会影响到在临近应用的正常使用,而App Engine上面这些限制就是为了是运行在其平台上面应用能安全地运行着想,避免了一个吞噬资源或恶性的应用影响到临近应用的情况。除了安全的方面考虑之 后,还有伸缩的原因,也就是说,当一个应用的所占空间(footprint)处于比较低的状态,比如少于1000个文件和大小低于150MB等,那么能够 非常方便地通过复制应用来实现伸缩。
接着,谈一下资费情况,App Engine的资费情况主要有两个特点:其一是免费额度高,现有免费的额度能支撑一个中型网站的运行,且不需付任何费用。其二是资费项目非常细粒度,普通 IaaS服务资费,主要就是CPU,内存,硬盘和网络带宽这四项,而App Engine则除了常见的CPU和网络带宽这两项之外,还包括很多应用级别的项目,比如:Datastore API和邮件API的调用次数等。具体资费的机制是这样的:如果用户的应用每天消费的各种资源都低于这个额度,那们用户无需支付任何费用,但是当免费额度 被超过的时候,用户就需要为超过的部分付费。因为App Engine整套资费标准比较复杂,所以在这里就主要介绍一下它的免费额度,具体请看下表:
| 类型 | 数量(每天) |
| 邮件API调用 | 7000次 |
| 传出(outbound)带宽 | 10G |
| 传入(inbound)带宽 | 10G |
| CPU时间 | 46个小时 |
| HTTP请求 | 130万次 |
| Datastore API | 1000万次 |
| 存储的数据 | 1G |
| URL抓取的API | 657千次 |
表2. App Engine的免费额度表
从上面免费额度来看,除了存储数据的容量外,其它都是非常强大的。
三、Google App Engine架构
设计理念
App Engine在设计理念方面,主要可以总结为下面这五条:
- 重用现有的Google技术:大家都知道,重用是软件工程的核心理念之一,因为通过重用不仅能减低开发成本,而且能简化架构。在App Engine开发的过程中,重用的思想也得到了非常好的体现,比如Datastore是基于Google的bigtable技术,Images服务是基于 Picasa的,用户认证服务是利用Google Account的,Email服务是基于Gmail的等。
- 无状态:为了让更好地支持扩展,Google没有在应用服务器层存储任何重要的状态,而主要在datastore这层对数据进行持久化,这样当应用流量突然爆发时,可以通过为应用添加新的服务器来实现扩展。
- 硬限制:App Engine对运行在其之上的应用代码设置了很多硬性限制,比如无法创建Socket和Thread等有限的系统资源,这样能保证不让一些恶性的应用影响到与其临近应用的正常运行,同时也能保证在应用之间能做到一定的隔离。
- 利用Protocol Buffers技术来解决服务方面的异构性:应用服务器和很多服务相连,有可能会出现异构性的问题,比如应用服务器是用Java写的,而部分服务是用 C++写的等。Google在这方面的解决方法是基于语言中立,平台中立和可扩展的Protocol Buffer,并且在App Engine平台上所有API的调用都需要在进行RPC(Remote Procedure Call,远程方面调用)之前被编译成Protocol Buffer的二进制格式。
- 分布式数据库:因为App Engine将支撑海量的网络应用,所以独立数据库的设计肯定是不可取的,而且很有可能将面对起伏不定的流量,所以需要一个分布式的数据库来支撑海量的数据和海量的查询。
组成部分
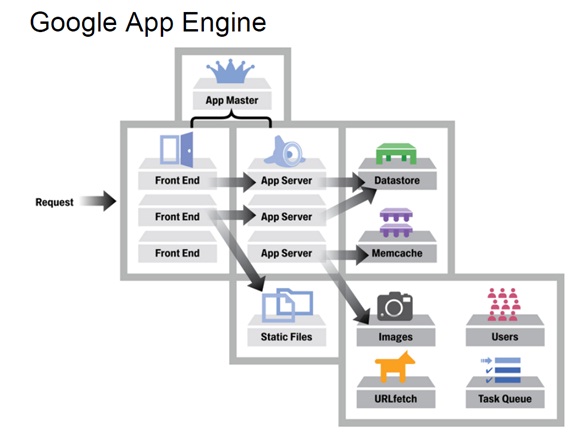
图1. GAE的架构图(图源自参[6])
简单而言,其架构可以分为三个部分:前端,Datastore和服务群:
前端
共包括四个模块:
- Front End:既可以认为它是Load Balancer,也可以认为它是Proxy,它主要负责负载均衡和将请求转发给App Server(应用服务器)或者Static Files等工作。
- Static Files:在概念上,比较类似于CDN(Content Delivery Network,内容分发网络),用于存储和传送那些应用附带的静态文件,比如图片,CSS和JS脚本等。
- App Server:用于处理用户发来的请求,并根据请求的内容来调用后面的Datastore和服务群。
- App Master:是在应用服务器间调度应用,并将调度之后的情况通知Front End。
Datastore
它是基于BigTable技术的分布式数据库,虽然其也可以被理解成为一个服务,但是由于其是整个App Engine唯一存储持久化数据的地方,所以其是App Engine中一个非常核心的模块。其具体细节将在下篇和大家讨论。
服务群
整个服务群包括很多服务供App Server调用,比如Memcache,图形,用户,URL抓取和任务队列等。
Python版和Java版App Engine在实现方面的区别
因为大多数服务都可以被这两个版本共享,所以两者之间的区别主要集中在App Server端,Python版App Server应该是经过Google修改的Python Runtime,版本号应该是2.5.2,而Java版App Server是基于Jetty 6的,因为它的体积和最常用的Tomcat相比更娇小,这样能使得一台服务器支持更多的应用,而且其应该经过Google的一定的修改。
流程
在这里举一个普通的HTTP请求的处理流程为例:
- 用户发送一个HTTP请求。
- Front End接受这个请求,并将这个请求转发给一个空闲的App Server。
- App Server会处理这个请求。
- 检查用于处理这个请求的Handler是不是已经被初始化了,如果没有的话,需要对这个Handler进行初始化。
- 调用服务群的用户认证服务来对用户进行认证,如果失败的话,需要终止整个请求的处理工作,并返回用户无法被认证的信息。
- 查看这个请求所需的数据是否已经缓存在Memcahe中,如果没有的话,将对Datastore发出查询请求来得到数据。
- 通过整合上步得到数据来生成相关的HTML,并返回给用户。
- 由于HTML里面会包含对一些静态文件的引用,比如图片和CSS等,所以当用户收到HTML之后,还会通过Front End对Static Files里面存储的静态文件进行读取。
四、Database设计
使用方面
首先,在编程方面,Datastore是基于"Entity(实体)"这个概念,而且Entity和"对象"这个概念比较类似,同时Entity可 以包括多个Property(属性),Property的类别有整数,浮点和字符串等,比如,可以设计一个名为"Person"的Entity,它包含名 为"Name"的字符串Property和名为"Age"的整数Property。由于Datastore是"Schema-less"的,所以数据的 Schema都由应用维护,而且能非常方便地对一个Entity所包含的属性进行增删和修改。在存储方面,一个Entity的实例可以被认为是一个普通 的"Row(行)",而包含所有这种Entity的实例的Table被称为Kind,比如,所有通过"Person"这个Entity生成实例,比如小 吴,小朱和小华等,它们都会存放在同一个名为"Person"的Kind中。在结构方面,虽然也能通过特定的方式在Datastore中实现关系型结构, 但是Datastore在设计上是为层次(Hierarchical)性结构"度身定做"的,有Root Entity和Child Entity之分,比如,可以把"Person"作为Root Entity(父实体),"Address"作为"Person"的Child Entity,两者合在一起可以称为一个"Entity Group"。这样做的好处是能将这两个实体集中一个BigTable本地分区中,而且能对这两个实体进行本地事务。
接下来,将谈一下Datastore支持那些高级功能:其一是提供名为GQL(Google Query Language)的查询语言,GQL是SQL的一个非常小的子集,包括对">","<"和"="等操作符。其二是App Engine会根据代码中查询语句来自动生成相应Index,但不支持对Composite Index生成。其三是虽然由于Datastore分布式的设计,所以在速度方面和传统的关系型数据库相比一定的差距,但是Google的架构师保证大部 分对Datastore的操作能在200ms之内完成,同时也得益于它的分布式设计,使得它在扩展性方面特别出色。其四是Datastore也支持在实体 之间创建关系,比如在Python版App Engine中可以使用ReferenceProperty在实体间构建一对多和多对多的关系。
下表为Datastore和传统的关系型数据库之间的比较:
| Datastore | 关系型数据库 | |
| SQL支持 | 只支持一些基本的查询 | 全部支持 |
| 主要结构 | 层次(Hierarchical) | 关系 |
| Index | 部分可自动创建 | 手动创建 |
| 事务 | 只支持在一个Entity Group内执行 | 支持 |
| 平均执行速度(ms) | 低于200 | 低于100 |
| 扩展型 | 非常好 | 很困难,而且需要进行大量的修改 |
表1. Datastore和关系型数据库之间的比较
最后,在接口方面,Python版提供一套私有的API和框架,在基本功能方面,比较容易学习,但在部分高级功能方面,比如关系和事务等方面,学习 难度很高;Java版的API是基于JDO和JPA这两套官方的ORM标准,但是和现在事实的标准Hibernate有一定的差异。
实现方面
在实现方面,Datastore是在BigTable的基础上构建的,所以本段会首先重新介绍一下BigTable,之后会介绍Datastore的两个组成部分:Entities Table和Index,最后会讲一下它在事务和备份这两方面所采用的机制。
BigTable
在本系列的第一篇已经按照Google的Paper对BigTable技术做了一定的介绍,但其实BigTable本身其实没有之前介绍的那样复 杂,其实就是一个非常巨大的Table,这也是是它之所以名为"BigTable"的原因,而且结构就像图1那样非常简单,就是一个个ROW,每个ROW 都有一个Name和一组Cloumn,但是为了支持海量的数据,它将这个大的Table进行分片(Sharding)处理,每台服务器存储一个海量的 Table的一小部分,并且为了查询效率,会对这个Table进行排序。就像App Engine的创始人之一Ryan Barrett所说的那样"BigTable is a sharded, sorted array "。

图1. BigTable简化版模型
在功能方面,首先,BigTable支持基本的CRUD操作,也就是增加(Create),查询(Read),更新(Update)和删除(Delete)。其次支持对Single-Row的事务与基于前缀和范围的扫描。
Entities Table
它是Datastore最核心的Table,是以BigTable的形式存在的,主要用于存储所有的Entity,而且是格式非常简单,每行都会有 一个Row Name,也称为Entity Key(可认为它是一个Entity的Primary Key),而且只有唯一一个Column,主要用于存放被序列化的Entity。每个Entity的Key的生成是基于它的父Entity(如果有的话) 和其父至上的Entity,直到其Root Entity。以下图为例,timmy的父Entity是jane,jane的父Entity兼Root Entity是Ethel,所以最后timmy的Entity Key是"/Grandparent:Ethel/Parent:Jane/Child:Timmy"。

图2. Entity Key的例子
Index
Index主要是为方便和加速查询而生的,所以在切入Index之前,先介绍一下Datastore主要支持那些查询,主要有三类:其一是基于Kind的,其二是基于Property值的,其三是基于多个Property值的。
Index表也是以BigTable的形式存在,但是和上面的Entities Table是分离的,主要用来单独存放那些需要被Index的数据,而且由于怕Index表体积太大,所以不会有时将其放置在内存中以提升查询速度。
主要有下面这几种Index表:
- Kind Index:用于加速那些用于获取所有属于某个Kind的Entity的查询,比如把所有属于Person这个Kind的Entity,包括小吴,小朱和 小华等提取出来,Kind Index表每行有Kind和Entity Key这两个列,此Index会有系统自动生成。
- Single-property Index:用于加速那些基于单一属性值的查询,比如要找出所有Age在20之下的Person,Age就是所谓的那个单一属性值,Single- property Index表每行除了Kind和Entity Key之外,还有属性名和属性值这两个列,此Index也会有系统自动生成,还会根据升降序的不同,生成两个表。
- Composite Index:用于加速那些基于对多个属性值的查询,Composite Index表基本和上面的Single-property Index表非常类似,但是每行包括多个属性名和属性值,而且由于此Index消耗资源非常多,所有由开发人自己确定是不是需要这个Index,系统不自 动生成。
事务
原则上所有对单一Entity的Write操作都是事务的,并基于上面提到的BigTable的Single-Row事务和Optimistic Concurrency Control这两个技术,下面是流程:首先,系统会读这个Entity的Committed Timestamp(提交时间戳),Write会以串行(Serialized)的形式写入到BigTable的日志中,之后,系统会将日志更新到 BigTable的表中,如果成功的话,系统会更新这个Entity的Committed Timestamp,但如果系统发现在更新之前,Committed Timestamp发生了变化,也就是说另一个事务在这个事务执行过程中已经对这个Entity进行了操作,在这个时候,系统会重新执行这个事务。由于在 整个事务过程采用Optimistic Concurrency Control,而不是Locking,所以在吞吐量方面表现不错。
如果要对多个Entity执行事务,那就需要将这几个Entity设为一个Entity Group,也就意味着将这几个Entity放在同一台物理机上。在执行的时候,会将以Root Entity的Committed Timestamp为准来对所有参与事务的Entity进行和上面差不多的事务操作。
备份
与BigTable基于Row级别的备份不同的是,Datastore是基于Enity Group级别,而且采用Paxos算法,所以Datastore的备份方法比BigTable的更安全。
总体而言,Datastore在设计理念上和传统的关系型数据库有很大的不同,所以其在反应速度和写数据方面不是最优的,但是现在Web应用以读为 主,而且需要能通过简单的扩展就能支持其海量的数据,而这两点却是Datastore所擅长,所以Datastore非常适合支撑Web应用。
对于Googe App Engine架构的介绍就到这里了,另外其实还有很多网站的架构也是比较经典的,像我以前介绍过的Facebook架构、MySpace架构、优酷架构、Twitter架构、Flickr架构等等,有兴趣的朋友可以关注一下这方面的技术资料,因为“云”上来了,这些都是我们学习的基础。
最后感谢吴朱华,膜拜一下....
好了,也不早了,洗洗睡了,各位晚安喽。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?