

解释器模式
在软件开发中,会遇到有些问题多次重复出现,而且有一定的相似性和规律性。如果将它们归纳成一种简单的语言,那么这些问题实例将是该语言的一些句子,这样就可以用“编译原理”中的解释器模式来实现了。
虽然使用解释器模式的实例不是很多,但对于满足以上特点,且对运行效率要求不是很高的应用实例,如果用解释器模式来实现,其效果是非常好的,本文将介绍其工作原理与使用方法。
模式的定义与特点
解释器(Interpreter)模式的定义:给分析对象定义一个语言,并定义该语言的文法表示,再设计一个解析器来解释语言中的句子。也就是说,用编译语言的方式来分析应用中的实例。这种模式实现了文法表达式处理的接口,该接口解释一个特定的上下文。
这里提到的文法和句子的概念同编译原理中的描述相同,“文法”指语言的语法规则,而“句子”是语言集中的元素。例如,汉语中的句子有很多,“我是中国人”是其中的一个句子,可以用一棵语法树来直观地描述语言中的句子。
解释器模式是一种类行为型模式,其主要优点如下。
- 扩展性好。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 容易实现。在语法树中的每个表达式节点类都是相似的,所以实现其文法较为容易。
解释器模式的主要缺点如下。
- 执行效率较低。解释器模式中通常使用大量的循环和递归调用,当要解释的句子较复杂时,其运行速度很慢,且代码的调试过程也比较麻烦。
- 会引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的个数将急剧增加,导致系统难以管理与维护。
- 可应用的场景比较少。在软件开发中,需要定义语言文法的应用实例非常少,所以这种模式很少被使用到。
模式的结构与实现
解释器模式常用于对简单语言的编译或分析实例中,为了掌握好它的结构与实现,必须先了解编译原理中的“文法、句子、语法树”等相关概念。
1) 文法
文法是用于描述语言的语法结构的形式规则。没有规矩不成方圆,例如,有些人认为完美爱情的准则是“相互吸引、感情专一、任何一方都没有恋爱经历”,虽然最后一条准则较苛刻,但任何事情都要有规则,语言也一样,不管它是机器语言还是自然语言,都有它自己的文法规则。例如,中文中的“句子”的文法如下。
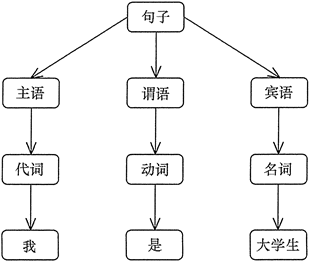
〈句子〉::=〈主语〉〈谓语〉〈宾语〉 〈主语〉::=〈代词〉|〈名词〉 〈谓语〉::=〈动词〉 〈宾语〉::=〈代词〉|〈名词〉 〈代词〉你|我|他 〈名词〉7大学生I筱霞I英语 〈动词〉::=是|学习
注:这里的符号“::=”表示“定义为”的意思,用“〈”和“〉”括住的是非终结符,没有括住的是终结符。
2) 句子
句子是语言的基本单位,是语言集中的一个元素,它由终结符构成,能由“文法”推导出。例如,上述文法可以推出“我是大学生”,所以它是句子。
3) 语法树
语法树是句子结构的一种树型表示,它代表了句子的推导结果,它有利于理解句子语法结构的层次。图 1 所示是“我是大学生”的语法树。
有了以上基础知识,现在来介绍解释器模式的结构就简单了。解释器模式的结构与组合模式相似,不过其包含的组成元素比组合模式多,而且组合模式是对象结构型模式,而解释器模式是类行为型模式。
1. 模式的结构
解释器模式包含以下主要角色。
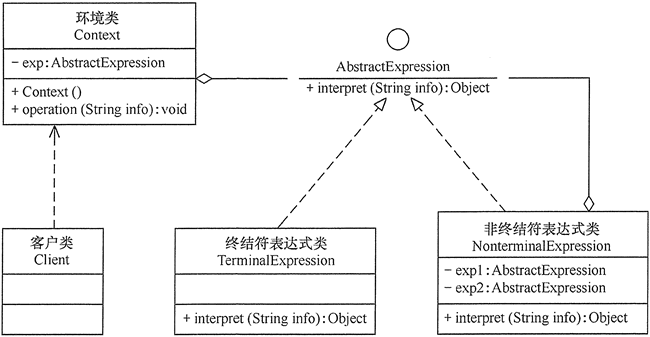
- 抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
- 非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
- 环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
解释器模式的结构图如图 2 所示。
2. 模式的实现
解释器模式实现的关键是定义文法规则、设计终结符类与非终结符类、画出结构图,必要时构建语法树,其代码结构如下:

package net.biancheng.c.interpreter; //抽象表达式类 interface AbstractExpression { public void interpret(String info); //解释方法 } //终结符表达式类 class TerminalExpression implements AbstractExpression { public void interpret(String info) { //对终结符表达式的处理 } } //非终结符表达式类 class NonterminalExpression implements AbstractExpression { private AbstractExpression exp1; private AbstractExpression exp2; public void interpret(String info) { //非对终结符表达式的处理 } } //环境类 class Context { private AbstractExpression exp; public Context() { //数据初始化 } public void operation(String info) { //调用相关表达式类的解释方法 } }
模式的应用实例
【例1】用解释器模式设计一个“韶粵通”公交车卡的读卡器程序。
说明:假如“韶粵通”公交车读卡器可以判断乘客的身份,如果是“韶关”或者“广州”的“老人” “妇女”“儿童”就可以免费乘车,其他人员乘车一次扣 2 元。
分析:本实例用“解释器模式”设计比较适合,首先设计其文法规则如下。
<expression> ::= <city>的<person> <city> ::= 韶关|广州 <person> ::= 老人|妇女|儿童
然后,根据文法规则按以下步骤设计公交车卡的读卡器程序的类图。
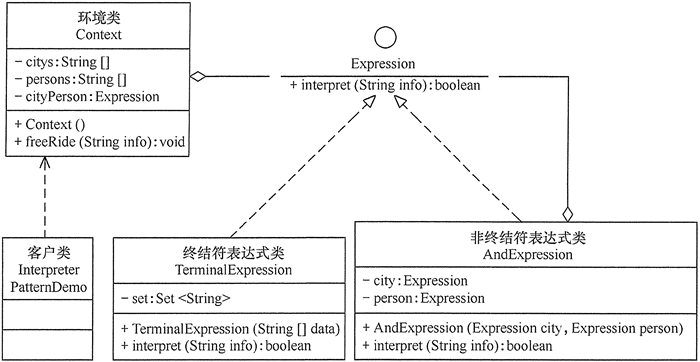
- 定义一个抽象表达式(Expression)接口,它包含了解释方法 interpret(String info)。
- 定义一个终结符表达式(Terminal Expression)类,它用集合(Set)类来保存满足条件的城市或人,并实现抽象表达式接口中的解释方法 interpret(Stringinfo),用来判断被分析的字符串是否是集合中的终结符。
- 定义一个非终结符表达式(AndExpressicm)类,它也是抽象表达式的子类,它包含满足条件的城市的终结符表达式对象和满足条件的人员的终结符表达式对象,并实现 interpret(String info) 方法,用来判断被分析的字符串是否是满足条件的城市中的满足条件的人员。
- 最后,定义一个环境(Context)类,它包含解释器需要的数据,完成对终结符表达式的初始化,并定义一个方法 freeRide(String info) 调用表达式对象的解释方法来对被分析的字符串进行解释。其结构图如图 3 所示。
package net.biancheng.c.interpreter; import java.util.*; /*文法规则 <expression> ::= <city>的<person> <city> ::= 韶关|广州 <person> ::= 老人|妇女|儿童 */ public class InterpreterPatternDemo { public static void main(String[] args) { Context bus = new Context(); bus.freeRide("韶关的老人"); bus.freeRide("韶关的年轻人"); bus.freeRide("广州的妇女"); bus.freeRide("广州的儿童"); bus.freeRide("山东的儿童"); } } //抽象表达式类 interface Expression { public boolean interpret(String info); } //终结符表达式类 class TerminalExpression implements Expression { private Set<String> set = new HashSet<String>(); public TerminalExpression(String[] data) { for (int i = 0; i < data.length; i++) set.add(data[i]); } public boolean interpret(String info) { if (set.contains(info)) { return true; } return false; } } //非终结符表达式类 class AndExpression implements Expression { private Expression city = null; private Expression person = null; public AndExpression(Expression city, Expression person) { this.city = city; this.person = person; } public boolean interpret(String info) { String s[] = info.split("的"); return city.interpret(s[0]) && person.interpret(s[1]); } } //环境类 class Context { private String[] citys = {"韶关", "广州"}; private String[] persons = {"老人", "妇女", "儿童"}; private Expression cityPerson; public Context() { Expression city = new TerminalExpression(citys); Expression person = new TerminalExpression(persons); cityPerson = new AndExpression(city, person); } public void freeRide(String info) { boolean ok = cityPerson.interpret(info); if (ok) System.out.println("您是" + info + ",您本次乘车免费!"); else System.out.println(info + ",您不是免费人员,本次乘车扣费2元!"); } }
模式的应用场景
前面介绍了解释器模式的结构与特点,下面分析它的应用场景。
- 当语言的文法较为简单,且执行效率不是关键问题时。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候,如 XML 文档解释。
注意:解释器模式在实际的软件开发中使用比较少,因为它会引起效率、性能以及维护等问题。如果碰到对表达式的解释,在 Java 中可以用 Expression4J 或 Jep 等来设计。
模式的扩展
在项目开发中,如果要对数据表达式进行分析与计算,无须再用解释器模式进行设计了,Java 提供了以下强大的数学公式解析器:Expression4J、MESP(Math Expression String Parser) 和 Jep 等,它们可以解释一些复杂的文法,功能强大,使用简单。
现在以 Jep 为例来介绍该工具包的使用方法。Jep 是 Java expression parser 的简称,即 Java 表达式分析器,它是一个用来转换和计算数学表达式的 Java 库。通过这个程序库,用户可以以字符串的形式输入一个任意的公式,然后快速地计算出其结果。而且 Jep 支持用户自定义变量、常量和函数,它包括许多常用的数学函数和常量。
使用前先下载 Jep 压缩包,解压后,将 jep-x.x.x.jar 文件移到选择的目录中,在 Eclipse 的“Java 构建路径”对话框的“库”选项卡中选择“添加外部 JAR(X)...”,将该 Jep 包添加项目中后即可使用其中的类库。
下面以计算存款利息为例来介绍。存款利息的计算公式是:本金x利率x时间=利息,其相关代码如下:
package net.biancheng.c.interpreter; import com.singularsys.jep.*; public class JepDemo { public static void main(String[] args) throws JepException { Jep jep = new Jep(); //定义要计算的数据表达式 String 存款利息 = "本金*利率*时间"; //给相关变量赋值 jep.addVariable("本金", 10000); jep.addVariable("利率", 0.038); jep.addVariable("时间", 2); jep.parse(存款利息); //解析表达式 Object accrual = jep.evaluate(); //计算 System.out.println("存款利息:" + accrual); } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构