Presto原理及安装
背景
MapReduce不能满足大数据快速实时adhoc查询计算的性能要求,Facebook2012年开发,2013年开源
是什么
基于内存的并行计算,Facebook推出的分布式SQL交互式查询引擎 多个节点管道式执行
支持任意数据源 数据规模GB~PB 是一种Massively parallel processing(mpp)(大规模并行处理)模型
数据规模PB 不是把PB数据放到内存,只是在计算中拿出一部分放在内存、计算、抛出、再拿
为什么要用&优点&特点
多数据源、支持SQL、扩展性(可以自己扩展新的connector)、混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)、高性能、流水线(pipeline)

与其他组件的关系及对比
hive
数据仓库 交互式略弱的查询引擎 只能访问HDFS文件 磁盘
但是presto是无法代替hive的
spark SQL
基于spark core mpp模式 详细课件spark sql一文
kylin
cube预计算
Druid
时序,数据放内存 索引 预计算
缺点
不适合多个大表的join操作,因为presto是基于内存的,太多数据内存放不下的
如果一个presto查询查过30分钟,那
就kill吧,说明不适合 也违背了presto的实时初衷
基本概念
catalog
相当于MySQL的一个实例,
schema
相当于MySQL的database
presto查询执行模型
- Statement语句 其实就是输入的SQL
- Query 根据SQL语句生成查询执行计划,进而生成可以执行的查询(Query),一个查询执行由Stage、Task、Driver、Split、Operator和DataSource组成
- Stage 执行查询阶段 Stage之间是树状的结构 ,RootStage 将结果返回给coordinator ,SourceStage接收coordinator数据 其他stage都有上下游 stage分为四种 single(root)、Fixed、source、coordinator_only(DML or DDL)
- Exchange 两个stage数据的交换通过Exchange 两种Exchange ;Output Buffer (生产数据的stage通过此传给下游stage)Exchange Client (下游消费);如果stage 是source 直接通过connector 读数据,则改stage通过Operator与connector交互
- stage 并不会被执行,只是对执行计划进行管理
- Task 实际运行在worker上的
- Driver 一个Driver处理一个split
- Operator 一个operator代表对一个split的一种操作 operator每次只会读取一个paged对象
- Split 分片一个分片就是一个大的数据集中的一个小的子集
- Page presto中处理的最小数据单元 一个page包含多个block对象,每个block对象是个字节数据
一个查询分解为多个stage 每个 stage拆分多个task,每个task处理一个or多个split ,一个task被分解为一个或多个Driver
硬件架构
大内存、万兆网络、高计算能力
软件架构
presto 查询引擎是一个Master-Slave的拓扑架构

coordinator
中心的查询角色 接收查询请求、解析SQL 生成执行计划 任务调度 worker管理
coordinator进行是presto集群的master进程
worker
执行任务的节点
connector
presto以插件形式对数据存储层进行了抽象,它叫做连接器,不仅包含Hadoop相关组件的连接器还包括RDBMS连接器
具体访问哪个数据源是通过catalog 中的XXXX.properties文件中connector.name决定的
提取数据 负责实际执行查询计划
discovery service
将coordinator和worker结合在一起服务;
worker节点启动后向discovery service服务注册
coordinator通过discovery service获取注册的worker节点
要想使用presto 还需要客户端 CLI客户端 or 应用客户端
工作原理
SQL运行过程
1、coordinator接到SQL后,通过SQL语法解析器把SQL语法解析变成一个抽象的语法树AST,只是进行语法解析如果有错误此环节暴露
2、语法符合SQL语法,会经过一个逻辑查询计划器组件,通过connector 查询metadata中schema 列名 列类型等,将之与抽象语法数对应起来,生成一个物理的语法树节点 如果有类型错误会在此步报错
3、如果通过,会得到一个逻辑的查询计划,将其分发到分布式的逻辑计划器里,进行分布式解析,最后转化为一个个task
4、在每个task里面,会将位置信息解析出来,交给执行的plan,由plan将task分给worker执
低延迟原理
-
基于内存的并行计算
-
流水式计算作业
-
本地化计算
Presto在选择Source任务计算节点的时候,对于每一个Split,按下面的策略选择一些minCandidates
优先选择与Split同一个Host的Worker节点
如果节点不够优先选择与Split同一个Rack的Worker节点
如果节点还不够随机选择其他Rack的节点 -
动态编译执行计划
-
GC控制
《------------------下面直接上货-----------------》
(1) 安装Presto服务节点概览
192.168.10.10 master(ambari01):Coordinator&worker服务
192.168.10.12 node1(ambari02):worker服务
192.168.10.13 node2(ambari03):worker服务
所需软件:
jdk-8u212-linux-x64.rpm
presto-server-0.242.tar.gz
presto-cli-0.242-executable.jar
(2) 环境配置
全部节点配置
a.修改selinux状态
#vim /etc/selinux/config
将selinux=enforcing改为disabled
b.关闭htp
#vim /etc/rc.local
在文档中增加如下内容:
If
test –f /sys/kernel/mm/transparent_hugepage/defrag;
then
echo never> /sys/kernel/mm/redhat_transparent_hugepage/defrag
fi
if
test –f /sys/kernel/mm/transparent_hugepage/ enabled;
then
echo never> /sys/kernel/mm/redhat_transparent_hugepage/enabled
fi
保存退出
修改权限
#chmod +x /etc/rc.d/rc.local
c.关闭防火墙
#systemctl stop firewalld
#systemctl disable firewalld
d.启动ntpd
#systemctl start ntpd
#systemctl enable ntpd
e.关闭chronyd
#systemctl stop chronyd
#systemctl disable chronyd
f.配置dns
#vim /etc/hostname
输入主机名
保存退出
#vim /etc/hosts
输入集群所有节点IP和主机名
更新主机名
#hostname –F /etc/hostname
g.配置SSH免登录
#ssh-keygen –t rsa
生成authorized_keys文件
#cd /root/.ssh
#cat id_rsa.pub >> authorized_keys
复制文件
#ssh-copy-id –i /root/.ssh/id_rsa.pub root@192.168.10.10
每台机器都要发送到其他所有机器
权限设置
#chmod 700 /root/.ssh/
#chmod 600 /root/.ssh/authorized_keys
免密验证:
#ssh ambari02(登录ambari02,[root@ambari01]更改为[root@ambari02]即为成功)
每台机器都要验证
h.安装JDK
安装高版本的Jdk8
rpm -ivh jdk-8u212-linux-x64.rpm
修改jdk的环境变量
Vi /ect/profile 添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_212-amd64
使环境变量生效
source /etc/profile
验证:
#java –version

(3) 安装配置Presto
安装presto
tar -zxvf presto-server-0.242.tar.gz -C /app
配置文件路径
cd /app/presto-server-0.242/bin
mkdir /app/presto-server-0.242/bin/etc
vim config.properties
conf.properties文件
coordinator + worker配置(主节点配置)
|
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=9001 query.max-memory=18GB query.max-memory-per-node=6GB discovery-server.enabled=true discovery.uri=http://ambari01:9001 |
workers配置(从节点配日志)
|
coordinator=false http-server.http.port=9001 query.max-memory=18GB query.max-memory-per-node=6GB http-server.log.path=/var/log/presto/http-request.log discovery.uri=http://ambari01:9001 |
vim node.properties
node.properties文件(所有节点除node.id不同,其他保持一致)
|
node.environment=myprestos node.id=cdabea32-a164-4a1c-b77c-f26970845c8c node.data-dir=/app/presto-server-0.242/data catalog.config-dir=/app/presto-server-0.242/bin/etc/catalog plugin.dir=/app/presto-server-0.242/plugin node.server-log-file=/var/log/presto/server.log node.launcher-log-file=/var/log/presto/launcher.log |
vim jvm.config
jvm.config文件(所有节点一致)
|
-server -Xmx16G -XX:-UseBiasedLocking -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+ExplicitGCInvokesConcurrent -XX:+ExitOnOutOfMemoryError -XX:+UseGCOverheadLimit -XX:+HeapDumpOnOutOfMemoryError -XX:ReservedCodeCacheSize=512M -Djdk.attach.allowAttachSelf=true -Djdk.nio.maxCachedBufferSize=2000000 |
vim log.properties
log.properties文件(所有节点一致)
|
com.facebook.presto=INFO |
Catalog Properties目录(所有节点一致)
新建catalog目录存放 每个connector配置来完成catalogs的注册。
mkdir /app/presto-server-0.242/bin/etc/catalog
创建hive.properties
|
connector.name=hive-hadoop2 hive.metastore.uri=thrift://ambari02.slave.com:9083 hive.config.resources=/usr/lib/presto/etc/core-site.xml,/usr/lib/presto/etc/hdfs-site.xml hive.allow-drop-table=true |
创建mysql.properties
|
connector.name=mysql connection-url=jdbc:mysql://192.168.30.167:3306 connection-user=root connection-password=123456 |
创建kafka.properties
|
connector.name=kafka kafka.table-names=staCdr kafka.nodes=ambari01.master.com:6667,ambari02.slave.com:6667,ambari03.slave.com:6667 kafka.hide-internal-columns=true |
创建phoenix.properties
|
connector.name=phoenix phoenix.connection-url=jdbc:phoenix:192.168.10.101,192.168.10.102,192.168.10.103:2181:/hbase phoenix.config.resources=/usr/lib/presto/etc/hbase-site.xml case-insensitive-name-matching=true |
创建redis.properties
|
connector.name=redis redis.table-names=default.test redis.nodes=192.168.10.101 |
创建elasticsearch.properties
|
connector.name=elasticsearch elasticsearch.host=192.168.10.101 elasticsearch.port=9200 #elasticsearch-clustername=gjes elasticsearch.scroll-size=1000 elasticsearch.scroll-timeout=2s elasticsearch.request-timeout=2s |
创建oracle.properties
|
connector.name=oracle connection-url=jdbc:oracle:thin:@192.168.10.101:port/database connection-user=test connection-password=test123 |
Phoenix的连接器需要使用自定义的修改的jar包来适应低版本的hbase
(4) 运行Presto
在安装presto服务的节点执行以下启动命令:
作为后台进程启动
|
/app/presto-server-0.242/bin/launcher start |
在前台运行
|
/app/presto-server-0.242/bin/launcher run |
停止服务进程
|
/app/presto-server-0.242/bin/launcher stop |
查看进程: ps -aux | grep PrestoServer 或 jps
查看页面 http://ambari01:9001
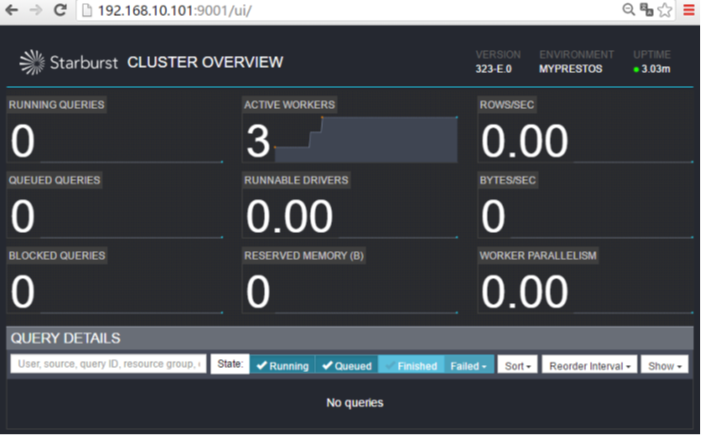
(5) 客户端连接Presto
连接presto的客户端jar包
presto-cli-0.242-executable.jar 上传到当前目录下
重命名jar包名字
mv presto-cli-0.242-executable.jar presto
将presto添加执行权限
chmod +x presto
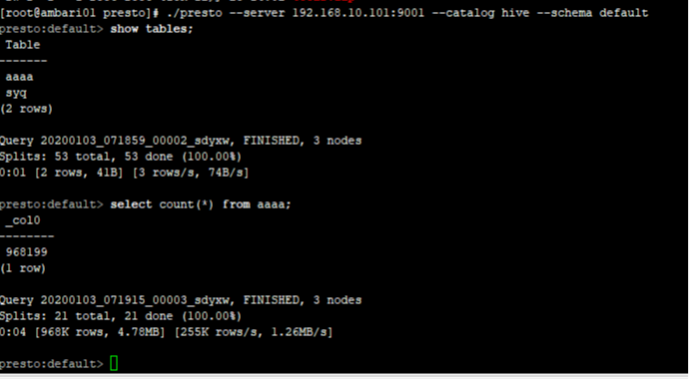
连接hive
./presto --server ambari01:9001 --catalog hive --schema default
连接mysql
./presto --server ambari01:9001 --catalog mysql --schema test
进入客户端如下图所示:
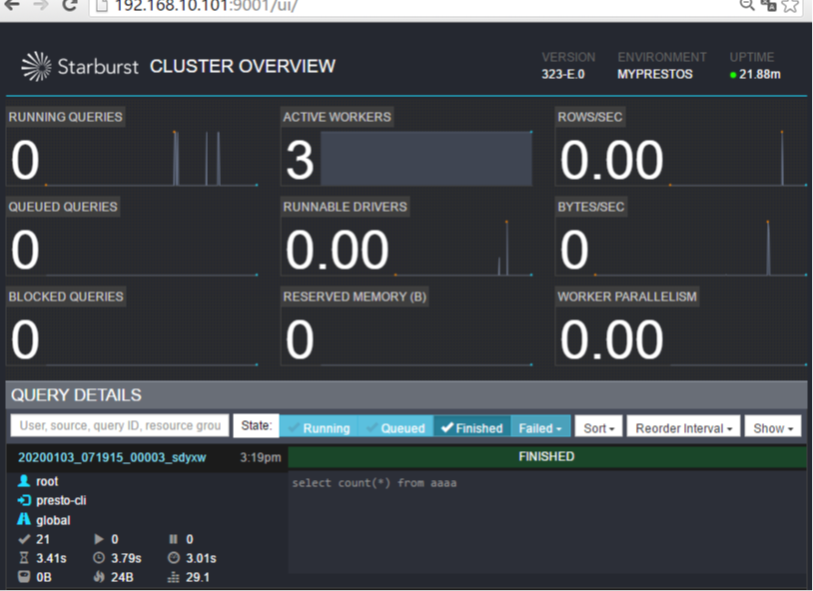
执行sql语句之后可以在presto监控页面上看到所提交的任务状态:
(6) Presto验证
进入presto
#cd /usr/lib/presto/bin
#./presto --server ambari:9001
查看catalog
presto> show catalogs;
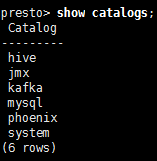
#./presto --server ambari:9001 --catalog mysql
查看 schema
presto> show schemas;
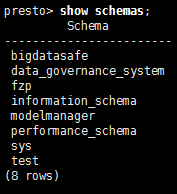
#./presto --server ambari:9001 --catalog mysql –schema test
查看表列表
presto> show tables;
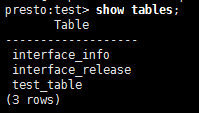
查看表数据
presto:test> select * from test_table;
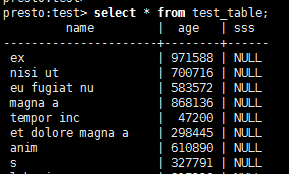
其他库也是这样操作
(7) Presto跨库查询
#./presto --server ambari:9001
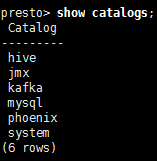
查看catalog
presto> show catalogs;
presto> select h.c_id,m.age from hive.test.t_ceshi as h left join mysql.test.test_table as m on h.c_id=m.age ;

(8) 异常解决

原因:
config.properties文件设置:
query.max-memory=18GB
query.max-memory-per-node=6GB
这两个参数过大导致,可适当减小。


