


JVM---对象内存布局(jol插件验证)
对象在内存中的布局
1.对象头
mark word
class pointer(有些地方写作klass word)
array length(如果常见的对象是数组则有这项,若不是,则不存在这一项)
2.实例数据
3.对齐填充
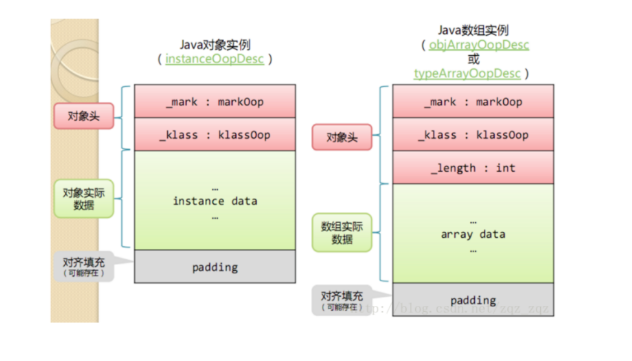
对象头
在32位系统中,mark word占4个字节,class pointer占4个字节,因此对象头共占8个字节
mark word
32位系统中
|-------------------------------------------------------|--------------------| | Mark Word (32 bits) | State |情况 |-------------------------------------------------------|--------------------| | identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | Normal | a.无锁不可偏向(有hash),b.无锁可偏向(无hash) |-------------------------------------------------------|--------------------| | thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | Biased | 偏向锁已偏向 |-------------------------------------------------------|--------------------| | ptr_to_lock_record:30 | lock:2 | Lightweight Locked | 轻量锁 |-------------------------------------------------------|--------------------| | ptr_to_heavyweight_monitor:30 | lock:2 | Heavyweight Locked | 重量锁 |-------------------------------------------------------|--------------------| | | lock:2 | Marked for GC | GC标识 |-------------------------------------------------------|--------------------|
上述其实表示在锁升级的时候,对象头中存储数据布局
| biased_lock | lock:2 | 状态 |
| 0 | 01 | 无锁 |
| 1 | 01 | 偏向锁 |
| 00 | 轻量级送 | |
| 10 | 重量级所 | |
| 11 | GC标识 |
注:不能单纯根据001和101来判断时候加了偏向锁,还应该看时候有偏向时的线程ID,101只是表示对象可偏向,可以参看例子
age GC年龄,对象在Survivor区赋值一次,年龄加1,当达到设定阈值或者。。。时,将会晋升到老年代(对象进入老年代,具体请参考),由于只占4 bits所以最大值位15
identity_hashcode 对象标识吗,调用System.identityHashCode()时,才会设置进入对象头,对象没有重写hashcode方法,则默认使用该值;若对象重写了hashcode方法,则对象头中不保存该数据
thread 持有偏向锁的线程ID
epoch 偏向时间戳
ptr_to_lock_record 指向栈中锁记录的指针
ptr_to_heavyweight_monitor 指向管程Monitor的指针
64位内存布局如下,标记为具体一次和32相同
|------------------------------------------------------------------------------|--------------------| | Mark Word (64 bits) | State | |------------------------------------------------------------------------------|--------------------| | unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | Normal | |------------------------------------------------------------------------------|--------------------| | thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | Biased | |------------------------------------------------------------------------------|--------------------| | ptr_to_lock_record:62 | lock:2 | Lightweight Locked | |------------------------------------------------------------------------------|--------------------| | ptr_to_heavyweight_monitor:62 | lock:2 | Heavyweight Locked | |------------------------------------------------------------------------------|--------------------| | | lock:2 | Marked for GC | |------------------------------------------------------------------------------|--------------------|
class pointer 指向对象类型数据(这部分数据存储在方法区中)的指针
在32位JVM中占32 bits,在64位JVM中占64 bits。在64位系统中会导致内存的浪费,JVM提供参数+UseCompressedClassPointers(我想看到这个名字,就应该会明白他的用法了吧)。当然,很多地方写到使用+UseCompressedOops进行控制,其实这个地方的oop是指ordinary object pointer(普通对象指针),因此+UseCompressedOops其实比+UseCompressedClassPointers所包含的范围广
设置+UseCompressedOops,哪些信息会被压缩?
1.对象的全局静态变量(即类属性)
2.对象头信息:64位平台下,原生对象头大小为16字节,压缩后为12字节
3.对象的引用类型:64位平台下,引用类型本身大小为8字节,压缩后为4字节
4.对象数组类型:64位平台下,数组类型本身大小为24字节,压缩后16字节
哪些信息不会被压缩?
1.指向非Heap的对象指针
2.局部变量、传参、返回值、NULL指针
关闭普通对象指针压缩,即-UseCompressedOops,则类型指针自动设置为-UseCompressedClassPointers,即使开启类型指针,即设置+UseCompressedClassPointers,该参数也无效
开启普通对象指针压缩,即+UseCompressedOops,则类型指针自动设置为+UseCompressedClassPointers。此时可以设置-UseCompressedClassPointers,该参数设置有效
array length 对于数组对象,另外存了下数据的长度,32为JVM上,为32 bits,在64为JVM上,为64bits,开启普通对象指针压缩,即+UseCompressedOops,则占32 bits
实例数据
无论是自己定义的,还是从父类继承的,都需要记录下来。
对齐填充
并不是必须存在的,Hot Spot虚拟机自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。
例子验证(说明,例子是我在64位JVM上运行的结果)
导入JAR文件
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
public class JavaObjectLayoutTest { public static void main(String[] args) { Object o = new Child(); System.out.println(ClassLayout.parseInstance(o).toPrintable()); o.hashCode(); System.out.println(o.hashCode()); System.out.println("对应十六进制表示:"+Integer.toHexString(o.hashCode())); System.out.println(ClassLayout.parseInstance(o).toPrintable()); } } class Parent { Long a =1l; long b =1; } class Child extends Parent{ }
在vm中设置参数-XX:+PrintCommandLineFlags
运行结果:
-XX:InitialHeapSize=265816960 -XX:MaxHeapSize=4253071360 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC Child object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 09 00 00 00 (00001001 00000000 00000000 00000000) (9) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 82 c1 00 f8 (10000010 11000001 00000000 11111000) (-134168190) 12 4 java.lang.Long Parent.a 1 16 8 long Parent.b 1 Instance size: 24 bytes Space losses: 0 bytes internal + 0 bytes external = 0 bytes total 648129364 对应十六进制表示:26a1ab54 Child object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 09 54 ab a1 (00001001 01010100 10101011 10100001) (-1582607351) 4 4 (object header) 26 00 00 00 (00100110 00000000 00000000 00000000) (38) 8 4 (object header) 82 c1 00 f8 (10000010 11000001 00000000 11111000) (-134168190) 12 4 java.lang.Long Parent.a 1 16 8 long Parent.b 1 Instance size: 24 bytes Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
查看打印结果,程序运行时默认开启了对象指针压缩和类型指针压缩-XX:+UseCompressedOops -XX:+UseCompressedClassPointers
新建child对象时,从父类继承的实例对象也会占对象空间,其中根据是否为基本数据类型,基本类型占用字节请参考https://www.cnblogs.com/sxrtb/p/12294979.html,引用类型在开启指针压缩(-XX:+UseCompressedOops)时,占用4个字节(关闭时占8个字节)
在未使用hashcode方法时,对象的内存布局为

此处mark word为 00000000_00000000_00000000_00100110_10100001_10101011_01010100_00001001,这个图里看到的真好相反,这个涉及到“大端存储和小端存储”这个知识。我们这看到的倒着存,是应为(计算机这里)用的小端存储
此时对象为新建状态,代表锁状态的数据占3 bits,为mark word中最后3 bits,为001,
依次,0001表示GC年龄,这个地方我刚刚新建,怎么就有GC呢,这个运行结果说明我这边的进行过GC操作(自己做测试,可能不是0001,这个是否进行过GC,可以通过-verbose:gc或者加上-XX:+PrintGCDetails就可以观察到,后续JVM中我也会写道具体GC参数说明)
使用过hashcode(System.identityHashCode())后,打印hashcode和其对应的十六进制整数,对象的内存布局为

在64为JVM中,hashcode占31 bits,顺着上面的凡是,则0100110 10100001 10101011 01010100表示hashcode,通过图示,也可以看到这数据用十六进制表示,也刚好是26a1ab54
同理,若位数组对象
public class JavaObjectLayoutTest { public static void main(String[] args) { System.out.println(ClassLayout.parseInstance(new B[3]).toPrintable()); } } class B{ }
-XX:InitialHeapSize=265816960 -XX:MaxHeapSize=4253071360 -XX:+PrintCommandLineFlags -XX:+UseBiasedLocking -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC [LB; object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 09 00 00 00 (00001001 00000000 00000000 00000000) (9) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 81 c1 00 f8 (10000001 11000001 00000000 11111000) (-134168191) 12 4 (object header) 03 00 00 00 (00000011 00000000 00000000 00000000) (3) 16 12 B [LB;.<elements> N/A 28 4 (loss due to the next object alignment) Instance size: 32 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
对照着上面的分析,我就不过多说明了。
一般看别人的例子,都会给对象加锁,如synchronized(o),此时对象都的信息也会改变
public class JavaObjectLayoutTest { public static void main(String[] args) { Object o = new Object(); System.out.println(ClassLayout.parseInstance(o).toPrintable()); synchronized (o){ System.out.println(ClassLayout.parseInstance(o).toPrintable()); } } }
-XX:InitialHeapSize=265816960 -XX:MaxHeapSize=4253071360 -XX:+PrintCommandLineFlags -XX:+UseBiasedLocking -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC java.lang.Object object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 09 00 00 00 (00001001 00000000 00000000 00000000) (9) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total java.lang.Object object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) b8 f5 1d 03 (10111000 11110101 00011101 00000011) (52295096) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
从运行结果上来看,这个地方直接加了一个轻量级锁。
提问:
1.如果我们这个时候使用hashcode()方法,这个肯定可以打印出来,但是根据对象头信息布局,此时hashcode的位置已经被占用了,那这个答应出来的hashcode时从哪里来的呢?
2.为什么直接加的是轻量级锁,而不是偏向锁
我这个地方主要写的时对象的内存布局,关于锁的知识我后续会详细写,答案引用别人的博客
可以参考https://blog.csdn.net/P19777/article/details/103125545
这个例子也说明了001和101不能直接判断是否加了偏向锁
public class A { }
public class JavaObjectLayoutTest { public static void main(String[] args) throws Exception { // 需要sleep一段时间,因为java对于偏向锁的启动是在启动几秒之后才激活。 // 因为jvm启动的过程中会有大量的同步块,且这些同步块都有竞争,如果一启动就启动 // 偏向锁,会出现很多没有必要的锁撤销 Thread.sleep(5000); A a = new A(); // 未出现任何获取锁的时候 System.out.println(ClassLayout.parseInstance(a).toPrintable()); synchronized (a){ // 获取一次锁之后 System.out.println(ClassLayout.parseInstance(a).toPrintable()); } // 输出hashcode System.out.println(a.hashCode()); // 计算了hashcode之后 System.out.println(ClassLayout.parseInstance(a).toPrintable()); synchronized (a){ // 再次获取锁 System.out.println(ClassLayout.parseInstance(a).toPrintable()); } } }
-XX:InitialHeapSize=265816960 -XX:MaxHeapSize=4253071360 -XX:+PrintCommandLineFlags -XX:+UseBiasedLocking -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC A object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 0d 00 00 00 (00001101 00000000 00000000 00000000) (13) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total A object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 0d 28 1b 03 (00001101 00101000 00011011 00000011) (52111373) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total 565760380 A object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 09 7c d1 b8 (00001001 01111100 11010001 10111000) (-1194230775) 4 4 (object header) 21 00 00 00 (00100001 00000000 00000000 00000000) (33) 8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total A object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) a0 f3 07 03 (10100000 11110011 00000111 00000011) (50852768) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
运行结果为什么会这样,可以参考下面(只是参考)
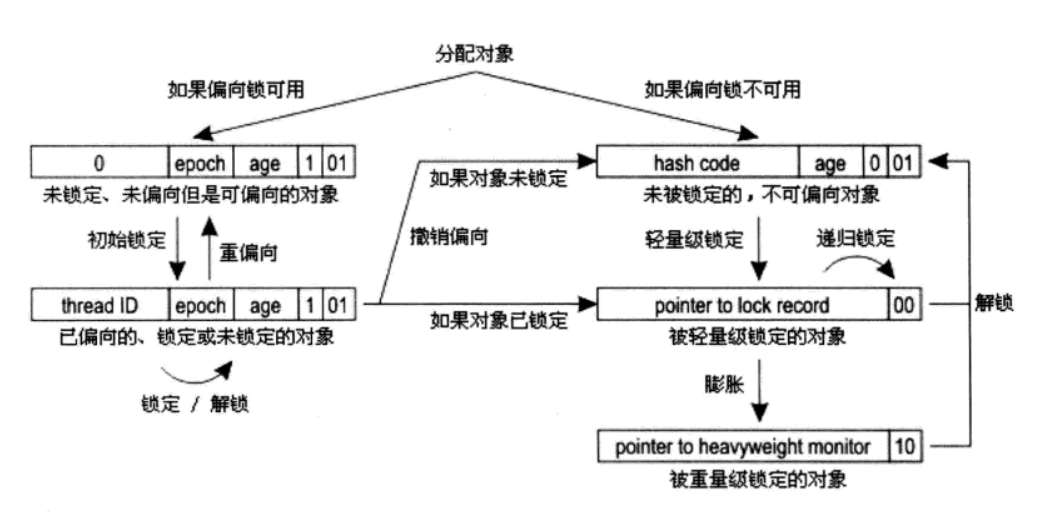
另外补充,对对象加锁(在开启偏向锁的时候,默认开启,关闭-XX:-UseBiasedLocking),对象没使用hashcode,则锁解除后锁标志位为101;若重写hashcode()方法,且调用hashcode(),则锁解除后锁标志位为101;若没有重写hashcode()方法,且调用hashcode(),则锁解除后锁标志位为001;
注意:若使用-XX:+UseBiasedLocking,刚开始启动JVM时,实际上-XX:+UseBiasedLocking暂时还没有生效,这个时候创建得对象锁标记位为001,这个时不可偏向的,升级时只能升级为轻量锁;再使用轻量级锁的时候,当前栈帧中建立一个名为Lock Record的控件,用户存储锁对象的Mark Word的拷贝,使用CAS操作尝试将Mark Word更新为Lock Record的指针,若成功,则标识这个对象拥有了该对象的锁(此次出hashcode,若Lock Record中有hashcode,则轻量级锁不变;若无,变成重量级锁);
若-XX:+UseBiasedLocking彻底生效后,创建的对象的锁标记位置为101,若有一个线程需要加锁时,这个锁为偏向锁(若此时使用hashcode,此时Mark Word中不可能有hashcode,则锁直接升级为重量级锁。若是再使用偏向锁之前,使用hascode,则锁标记为001,标识不可偏向,则后续直接添加轻量级锁)
使用hashcode的时,若数据未加锁,则此时锁标记位置未001,标识不可偏向。若对象再锁的时候使用hashcode,而hashcode由不从得知,则需要进行锁升级。
锁标记位置未10,也不代表一定添加的重量级锁。
引用怎样访问(找到)对象的
句柄
直接指针(Hot Spot使用这种方式)

优点:reference存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要改变。
缺点:增加了一次指针定位的时间开销。
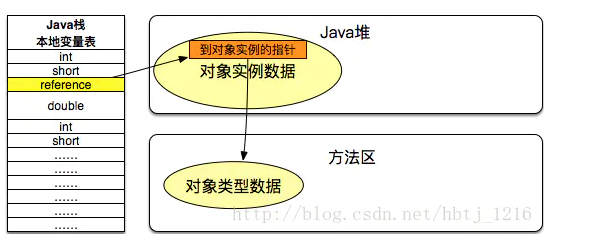
优点:节省了一次指针定位的开销。
缺点:在对象被移动时reference本身需要被修改。
写到这里就结束了,这里主要写的时对象的内存布局,如果要了解锁升级的过程,可以参考https://www.cnblogs.com/ZoHy/p/11313155.html
例题,分析写new A()和new B()所占用的空间
static class A{ String s = new String(); int i = 0; } static class B{ String s; int i; }
常见对象占用空间(在64为中开启指针压缩)

参考:https://www.jianshu.com/p/3d38cba67f8b
https://github.com/dmlloyd/openjdk/blob/jdk/jdk/src/hotspot/share/oops/markOop.hpp
https://www.jianshu.com/p/8580ab50e261
https://blog.csdn.net/P19777/article/details/103125545
https://www.cnblogs.com/ZoHy/p/11313155.html
markOop.hpp
https://github.com/dmlloyd/openjdk/blob/jdk/jdk/src/hotspot/share/oops/markOop.hpp
posted on 2020-04-19 09:04 xingshouzhan 阅读(1221) 评论(0) 编辑 收藏 举报


