前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步。BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进率5.6%)等。BERT模型是以Transformer编码器来表示,本文在详细介绍BERT模型,Transformer编码器的原理可以参考(https://www.cnblogs.com/sxron/p/10035802.html)。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
摘要
本文介绍了一种新的语言表征模型 BERT,它用Transformer的双向编码器表示。与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
模型架构
论文使用了两种模型:
-
BERTBASE: L=12, H=768, A=12, 总参数=110M
-
BERTLARGE: L=24, H=1024, A=16, 总参数=340M
其中层数(即 Transformer 块个数)表示为 L,将隐藏尺寸表示为 H、自注意力头数表示为 A。在所有实验中,将前馈/滤波器尺寸设置为 4H,即 H=768 时为 3072,H=1024 时为 4096。
为了进行比较,论文中选择,BERTBASE 的模型尺寸与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能关注到其左侧的上下文。注意需要的是,在文献中,双向 Transformer 在文献中通常称为「Transformer 编码器」,而只关注左侧语境的版本则因能用于文本生成而被称为「Transformer 解码器」。BERT,OpenAI GPT和ELMo之间的比较如下图一所示。
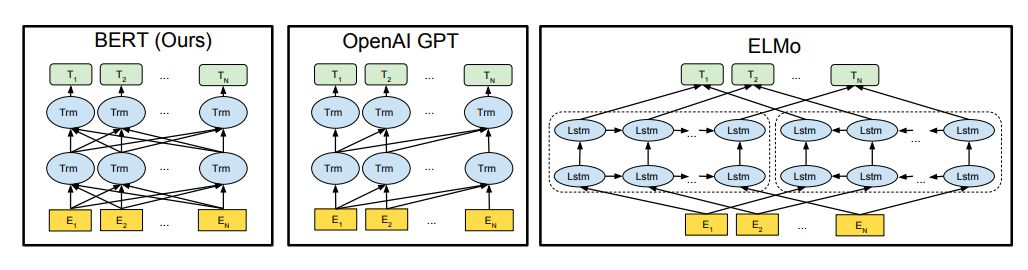
图1:预训练模型架构的差异。BERT使用双向Transformer。OpenAI GPT使用从左到右的Transformer。ELMo使用经过独立训练的从左到右
和从右到左LSTM的串联来生成下游任务的特征。三个模型中,只有BERT表示在所有层中共同依赖于左右上下文。
输入的表示
针对不同的任务,模型能够在一个token序列中明确地表示单个文本句子或一对文本句子(比如[问题,答案])。对于每一个token, 其输入表示通过其对应的token embedding, 段表征(segment embedding)和位置表征(position embedding)相加产生。图2是输入表示的直观表示:
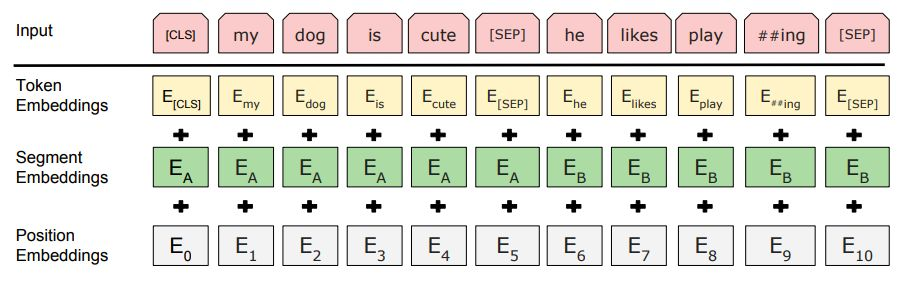 图2:BERT输入表示。输入嵌入是token embeddings, segmentation embeddings 和position embeddings 之和。
图2:BERT输入表示。输入嵌入是token embeddings, segmentation embeddings 和position embeddings 之和。
具体实现细节如下:
-
- 论文使用了WordPiece embeddings含有30000个token,并且使用“##”来拆分词片段
- 使用了positional embeddings, 长达512位,即句子的最大长度
- 每句话的第一个token总是[CLS]。对应它的最终的hidden state(即Transformer的输出)用来表征整个句子,可以用于下游的分类任务。
- 模型能够处理句子对。为区别两个句子,用一个特殊token [SEP]隔开它们,另外针对不同的句子,把学习到的Segment embeddings 加到每个token的embedding上(如图)
- 对于单个句子仅使用一个Segment embedding
预训练任务
与Peters et al. (2018) 和 Radford et al. (2018)不同,论文不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,使用两个新的无监督预测任务对BERT进行预训练。
任务 #1:Masked LM
从直觉上看,研究团队有理由相信,深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。遗憾的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。 为了训练深度双向表征,我们采取了一个直接的方法,随机遮蔽输入 token 的某些部分,然后预测被遮住的 token。我们将这一步骤称为「masked LM」(MLM),不过它在文献中通常被称为 Cloze 任务 (Taylor, 1953)。在这种情况下,对应遮蔽 token 的最终隐藏向量会输入到 softmax 函数中,并如标准 LM 中那样预测所有词汇的概率。在所做的所有实验中,我们随机遮住了每个序列中 15% 的 WordPiece token。与去噪自编码器 (Vincent et al., 2008) 相反,我们仅预测遮蔽单词而非重建整个输入。
虽然这确实能让研究团队获得双向预训练模型,但这种方法有两个缺点。第一个是,如果常常把一些词mask起来,未来的fine tuning过程中模型有可能没见过这些词,这个量积累下来还是很大的。因为作者在他的实现中随机选择了句子中15%的WordPiece tokens作为要mask的词。为了解决这个问题,作者在设计mask的时候,使用如下的方法。
- 80%的概率真的用[MASK]取代被选中的词。比如 my dog is hairy -> my dog is [MASK]
- 10%的概率用一个随机词取代它:my dog is hairy -> my dog is apple
- 10%的概率保持不变: my dog is hairy -> my dog is hairy
为什么要以一定的概率保持不变呢? 如果100%的概率都用[MASK]来取代被选中的词,那么在fine tuning的时候模型可能会有一些没见过的词。那么为什么要以一定的概率使用随机词呢?这是因为Transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中说了,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。
使用MLM的第二个缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
任务 #2:下一句预测
很多重要的下游任务(如问答(QA)和自然语言推断(NLI))基于对两个文本句子之间关系的理解,这种关系并非通过语言建模直接获得。为了训练一个理解句子关系的模型,我们预训练了一个二值化下一句预测任务,该任务可以从任意单语语料库中轻松生成。具体来说,选择句子 A 和 B 作为预训练样本:B 有 50% 的可能是 A 的下一句,也有 50% 的可能是来自语料库的随机句子。
实验结果
如前文所述,BERT在11项NLP任务中刷新了性能表现记录, BERT模型通过上面介绍的预训练后,在11个NLP任务上的微调结果。
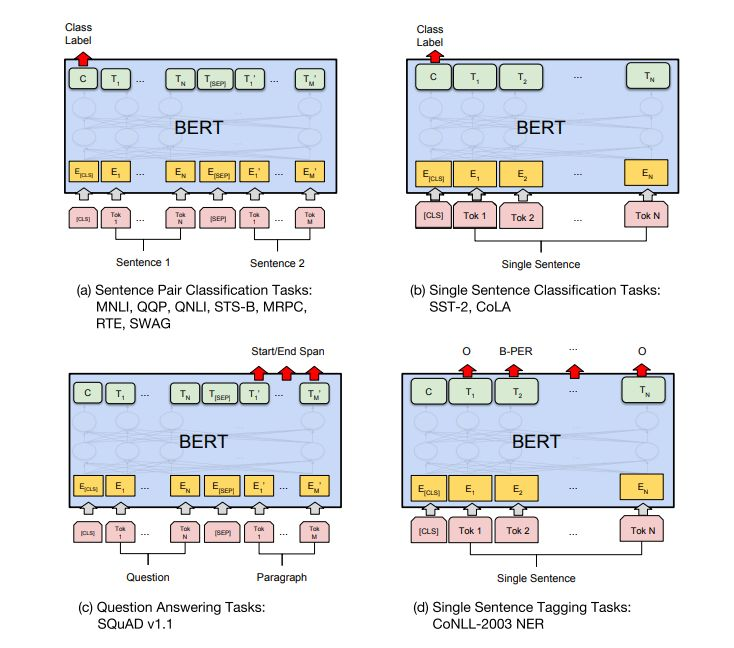
图 3:我们的任务特定模型是由向 BERT 添加了一个额外的输出层而形成的,因此一小部分参数需要从头开始学习。在众多任务中,(a) 和 (b) 任务是序列级任务,(c) 和 (d) 是 token 级任务,图中 E 表示输入嵌入,T_i 表示 token i 的语境表征,[CLS] 是分类输出的特殊符号,[SEP] 是分割非连续 token 序列的特殊符号。
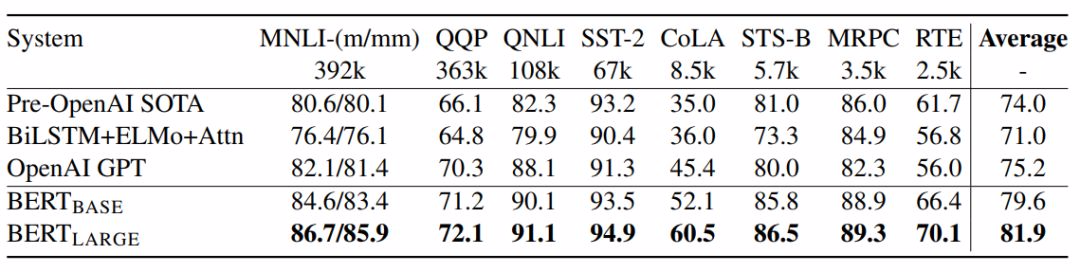
图4:GLUE测试结果,由GLUE评估服务器给出。每个任务下方的数字表示训练样例的数量。“平均”一栏中的数据与GLUE官方评分稍有不同,因为我们排除了有问题的WNLI集。BERT 和OpenAI GPT的结果是单模型、单任务下的数据。
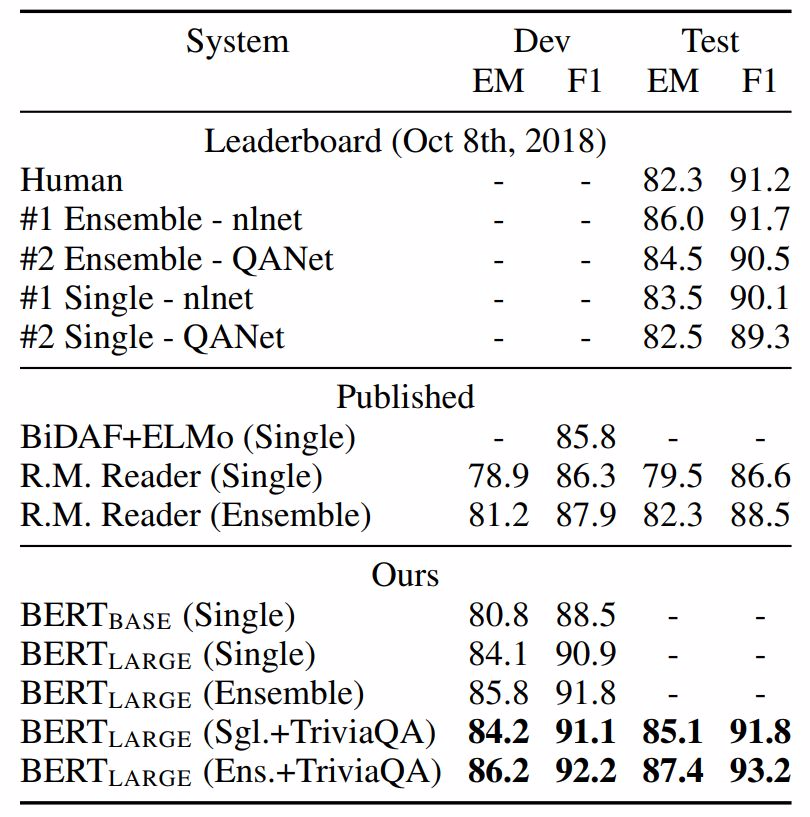
图5:SQuAD 结果。BERT 集成是使用不同预训练检查点和微调种子(fine-tuning seed)的 7x 系统。
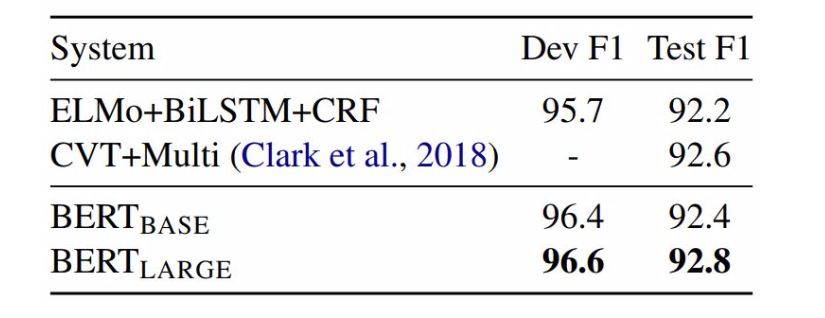
图6:CoNLL-2003 命名实体识别结果。超参数由开发集选择,得出的开发和测试分数是使用这些超参数进行五次随机重启的平均值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号