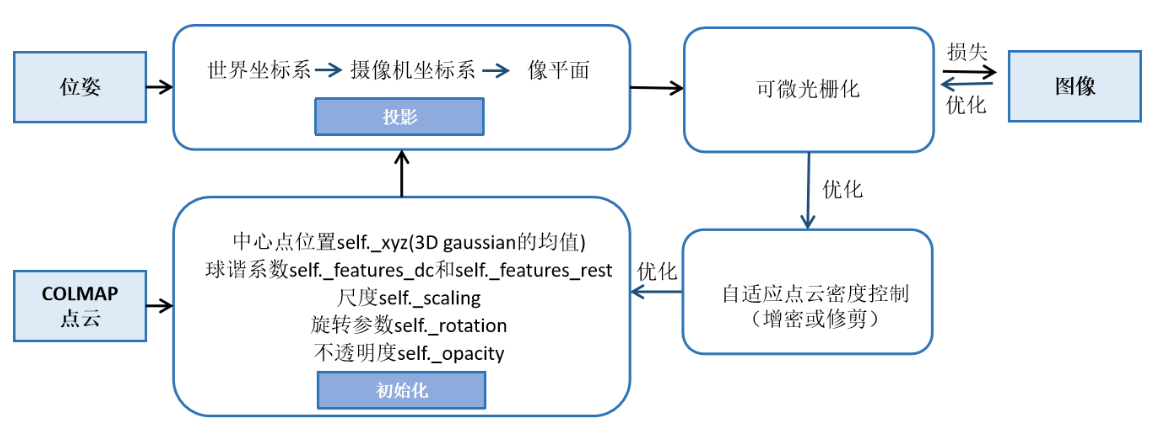
1 模型训练
| def training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from): |
| first_iter = 0 |
| |
| gaussians = GaussianModel(dataset.sh_degree) |
| |
| scene = Scene(dataset, gaussians) |
| |
| gaussians.training_setup(opt) |
| |
| if checkpoint: |
| (model_params, first_iter) = torch.load(checkpoint) |
| gaussians.restore(model_params, opt) |
| |
| bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0] |
| background = torch.tensor(bg_color, dtype=torch.float32, device="cuda") |
| |
| |
| iter_start = torch.cuda.Event(enable_timing=True) |
| iter_end = torch.cuda.Event(enable_timing=True) |
| |
| viewpoint_stack = None |
| ema_loss_for_log = 0.0 |
| |
| progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress") |
| first_iter += 1 |
| for iteration in range(first_iter, opt.iterations + 1): |
| |
| iter_start.record() |
| |
| |
| gaussians.update_learning_rate(iteration) |
| |
| |
| if iteration % 1000 == 0: |
| gaussians.oneupSHdegree() |
| |
| |
| if not viewpoint_stack: |
| viewpoint_stack = scene.getTrainCameras().copy() |
| viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1)) |
| |
| |
| if (iteration - 1) == debug_from: |
| pipe.debug = True |
| |
| |
| bg = torch.rand((3), device="cuda") if opt.random_background else background |
| |
| |
| render_pkg = render(viewpoint_cam, gaussians, pipe, bg) |
| image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"] |
| |
| |
| gt_image = viewpoint_cam.original_image.cuda() |
| Ll1 = l1_loss(image, gt_image) |
| loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image)) |
| loss.backward() |
| |
| |
| iter_end.record() |
| |
| with torch.no_grad(): |
| |
| ema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_log |
| if iteration % 10 == 0: |
| progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}"}) |
| progress_bar.update(10) |
| if iteration == opt.iterations: |
| progress_bar.close() |
| |
| |
| training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background)) |
| if iteration in saving_iterations: |
| print("\n[ITER {}] Saving Gaussians".format(iteration)) |
| scene.save(iteration) |
| |
| |
| if iteration < opt.densify_until_iter: |
| gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter]) |
| gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter) |
| |
| if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0: |
| size_threshold = 20 if iteration > opt.opacity_reset_interval else None |
| gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold) |
| |
| if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter): |
| gaussians.reset_opacity() |
| |
| |
| if iteration < opt.iterations: |
| gaussians.optimizer.step() |
| gaussians.optimizer.zero_grad(set_to_none=True) |
| |
| |
| if iteration in checkpoint_iterations: |
| print("\n[ITER {}] Saving Checkpoint".format(iteration)) |
| torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth") |
2 数据加载
| class Scene: |
| """ |
| Scene 类用于管理场景的3D模型,包括相机参数、点云数据和高斯模型的初始化和加载 |
| """ |
| |
| def __init__(self, args: ModelParams, gaussians: GaussianModel, load_iteration=None, shuffle=True, resolution_scales=[1.0]): |
| """ |
| 初始化场景对象 |
| |
| :param args: 包含模型路径和源路径等模型参数 |
| :param gaussians: 高斯模型对象,用于场景点的3D表示 |
| :param load_iteration: 指定加载模型的迭代次数,如果为-1,则自动寻找最大迭代次数 |
| :param shuffle: 是否在训练前打乱相机列表 |
| :param resolution_scales: 分辨率比例列表,用于处理不同分辨率的相机 |
| """ |
| self.model_path = args.model_path |
| self.loaded_iter = None |
| self.gaussians = gaussians |
| |
| |
| if load_iteration: |
| if load_iteration == -1: |
| self.loaded_iter = searchForMaxIteration(os.path.join(self.model_path, "point_cloud")) |
| else: |
| self.loaded_iter = load_iteration |
| print(f"Loading trained model at iteration {self.loaded_iter}") |
| |
| self.train_cameras = {} |
| self.test_cameras = {} |
| |
| |
| if os.path.exists(os.path.join(args.source_path, "sparse")): |
| scene_info = sceneLoadTypeCallbacks["Colmap"](args.source_path, args.images, args.eval) |
| elif os.path.exists(os.path.join(args.source_path, "transforms_train.json")): |
| print("Found transforms_train.json file, assuming Blender data set!") |
| scene_info = sceneLoadTypeCallbacks["Blender"](args.source_path, args.white_background, args.eval) |
| else: |
| assert False, "Could not recognize scene type!" |
| |
| |
| if self.loaded_iter: |
| self.gaussians.load_ply(os.path.join(self.model_path, "point_cloud", "iteration_" + str(self.loaded_iter), "point_cloud.ply")) |
| else: |
| self.gaussians.create_from_pcd(scene_info.point_cloud, self.cameras_extent) |
| |
| |
| for resolution_scale in resolution_scales: |
| print("Loading Training Cameras") |
| self.train_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.train_cameras, resolution_scale, args) |
| print("Loading Test Cameras") |
| self.test_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.test_cameras, resolution_scale, args) |
| |
| def save(self, iteration): |
| """ |
| 保存当前迭代下的3D高斯模型点云。 |
| |
| :param iteration: 当前的迭代次数。 |
| """ |
| point_cloud_path = os.path.join(self.model_path, f"point_cloud/iteration_{iteration}") |
| self.gaussians.save_ply(os.path.join(point_cloud_path, "point_cloud.ply")) |
| |
| def getTrainCameras(self, scale=1.0): |
| """ |
| 获取指定分辨率比例的训练相机列表 |
| |
| :param scale: 分辨率比例 |
| :return: 指定分辨率比例的训练相机列表 |
| """ |
| return self.train_cameras[scale] |
| |
| sceneLoadTypeCallbacks = { |
| "Colmap": readColmapSceneInfo, |
| "Blender" : readNerfSyntheticInfo |
| } |
| def readColmapSceneInfo(path, images, eval, llffhold=8): |
| |
| try: |
| cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin") |
| cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin") |
| cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file) |
| cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file) |
| except: |
| |
| cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt") |
| cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt") |
| cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file) |
| cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file) |
| |
| |
| reading_dir = "images" if images is None else images |
| |
| cam_infos_unsorted = readColmapCameras(cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, images_folder=os.path.join(path, reading_dir)) |
| |
| cam_infos = sorted(cam_infos_unsorted.copy(), key=lambda x: x.image_name) |
| |
| |
| |
| if eval: |
| train_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold != 0] |
| test_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold == 0] |
| else: |
| |
| train_cam_infos = cam_infos |
| test_cam_infos = [] |
| |
| |
| nerf_normalization = getNerfppNorm(train_cam_infos) |
| |
| |
| ply_path = os.path.join(path, "sparse/0/points3D.ply") |
| bin_path = os.path.join(path, "sparse/0/points3D.bin") |
| txt_path = os.path.join(path, "sparse/0/points3D.txt") |
| if not os.path.exists(ply_path): |
| print("Converting point3d.bin to .ply, will happen only the first time you open the scene.") |
| try: |
| xyz, rgb, _ = read_points3D_binary(bin_path) |
| except: |
| xyz, rgb, _ = read_points3D_text(txt_path) |
| storePly(ply_path, xyz, rgb) |
| try: |
| pcd = fetchPly(ply_path) |
| except: |
| pcd = None |
| |
| |
| scene_info = SceneInfo(point_cloud=pcd, |
| train_cameras=train_cam_infos, |
| test_cameras=test_cam_infos, |
| nerf_normalization=nerf_normalization, |
| ply_path=ply_path) |
| return scene_info |
| |
| def readColmapCameras(cam_extrinsics, cam_intrinsics, images_folder): |
| cam_infos = [] |
| |
| |
| for idx, key in enumerate(cam_extrinsics): |
| |
| sys.stdout.write('\r') |
| sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics))) |
| sys.stdout.flush() |
| |
| |
| extr = cam_extrinsics[key] |
| intr = cam_intrinsics[extr.camera_id] |
| height = intr.height |
| width = intr.width |
| |
| uid = intr.id |
| |
| R = np.transpose(qvec2rotmat(extr.qvec)) |
| |
| T = np.array(extr.tvec) |
| |
| |
| if intr.model == "SIMPLE_PINHOLE": |
| |
| focal_length_x = intr.params[0] |
| FovY = focal2fov(focal_length_x, height) |
| FovX = focal2fov(focal_length_x, width) |
| elif intr.model == "PINHOLE": |
| |
| focal_length_x = intr.params[0] |
| focal_length_y = intr.params[1] |
| FovY = focal2fov(focal_length_y, height) |
| FovX = focal2fov(focal_length_x, width) |
| else: |
| |
| assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!" |
| |
| |
| image_path = os.path.join(images_folder, os.path.basename(extr.name)) |
| image_name = os.path.basename(image_path).split(".")[0] |
| |
| image = Image.open(image_path) |
| |
| |
| cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, image=image, |
| image_path=image_path, image_name=image_name, width=width, height=height) |
| cam_infos.append(cam_info) |
| |
| |
| sys.stdout.write('\n') |
| |
| return cam_infos |
3 模型构建
| gaussians = GaussianModel(dataset.sh_degree) |
| def __init__(self, sh_degree: int): |
| """ |
| 初始化3D高斯模型的参数。 |
| |
| :param sh_degree: 球谐函数的最大次数,用于控制颜色表示的复杂度。 |
| """ |
| |
| self.active_sh_degree = 0 |
| self.max_sh_degree = sh_degree |
| |
| |
| self._xyz = torch.empty(0) |
| self._features_dc = torch.empty(0) |
| self._features_rest = torch.empty(0) |
| self._scaling = torch.empty(0) |
| self._rotation = torch.empty(0) |
| self._opacity = torch.empty(0) |
| self.max_radii2D = torch.empty(0) |
| self.xyz_gradient_accum = torch.empty(0) |
| self.denom = torch.empty(0) |
| self.optimizer = None |
| |
| |
| self.setup_functions() |
| |
| def setup_functions(self): |
| """ |
| 定义和初始化一些用于处理3D高斯模型参数的函数。 |
| """ |
| |
| |
| def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation): |
| L = build_scaling_rotation(scaling_modifier * scaling, rotation) |
| actual_covariance = L @ L.transpose(1, 2) |
| symm = strip_symmetric(actual_covariance) |
| return symm |
| |
| |
| self.scaling_activation = torch.exp |
| self.scaling_inverse_activation = torch.log |
| |
| self.covariance_activation = build_covariance_from_scaling_rotation |
| |
| self.opacity_activation = torch.sigmoid |
| self.inverse_opacity_activation = inverse_sigmoid |
| |
| self.rotation_activation = torch.nn.functional.normalize |
| def build_scaling_rotation(s, r): |
| """ |
| 构建3D高斯模型的尺度-旋转矩阵。 |
| |
| :param s: 尺度参数。 |
| :param r: 旋转参数。 |
| :return: 尺度-旋转矩阵。 |
| """ |
| L = torch.zeros((s.shape[0], 3, 3), dtype=torch.float, device="cuda") |
| R = build_rotation(r) |
| |
| |
| L[:, 0, 0] = s[:, 0] |
| L[:, 1, 1] = s[:, 1] |
| L[:, 2, 2] = s[:, 2] |
| |
| L = R @ L |
| return L |
| |
| def strip_symmetric(sym): |
| """ |
| 提取协方差矩阵的对称部分。 |
| |
| :param sym: 协方差矩阵。 |
| :return: 对称部分。 |
| """ |
| return strip_lowerdiag(sym) |
| |
| def strip_lowerdiag(L): |
| """ |
| 从协方差矩阵中提取六个独立参数。 |
| |
| :param L: 协方差矩阵。 |
| :return: 六个独立参数组成的张量。 |
| """ |
| uncertainty = torch.zeros((L.shape[0], 6), dtype=torch.float, device="cuda") |
| |
| |
| uncertainty[:, 0] = L[:, 0, 0] |
| uncertainty[:, 1] = L[:, 0, 1] |
| uncertainty[:, 2] = L[:, 0, 2] |
| uncertainty[:, 3] = L[:, 1, 1] |
| uncertainty[:, 4] = L[:, 1, 2] |
| uncertainty[:, 5] = L[:, 2, 2] |
| return uncertainty |
| def training_setup(self, training_args): |
| """ |
| 设置训练参数,包括初始化用于累积梯度的变量,配置优化器,以及创建学习率调度器 |
| |
| :param training_args: 包含训练相关参数的对象。 |
| """ |
| |
| self.percent_dense = training_args.percent_dense |
| |
| |
| self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") |
| |
| self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") |
| |
| |
| l = [ |
| {'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"}, |
| {'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"}, |
| {'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"}, |
| {'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"}, |
| {'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"}, |
| {'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"} |
| ] |
| |
| self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15) |
| |
| |
| self.xyz_scheduler_args = get_expon_lr_func( |
| lr_init=training_args.position_lr_init*self.spatial_lr_scale, |
| lr_final=training_args.position_lr_final*self.spatial_lr_scale, |
| lr_delay_mult=training_args.position_lr_delay_mult, |
| max_steps=training_args.position_lr_max_steps |
| ) |
| def get_expon_lr_func(lr_init, lr_final, lr_delay_steps=0, lr_delay_mult=1.0, max_steps=1000000): |
| """ |
| 创建一个学习率调度函数,该函数根据训练进度动态调整学习率 |
| |
| :param lr_init: 初始学习率。 |
| :param lr_final: 最终学习率。 |
| :param lr_delay_steps: 学习率延迟步数,在这些步数内学习率将被降低。 |
| :param lr_delay_mult: 学习率延迟乘数,用于计算初始延迟学习率。 |
| :param max_steps: 最大步数,用于规范化训练进度。 |
| :return: 一个函数,根据当前步数返回调整后的学习率。 |
| """ |
| def helper(step): |
| |
| if step < 0 or (lr_init == 0.0 and lr_final == 0.0): |
| return 0.0 |
| |
| if lr_delay_steps > 0: |
| delay_rate = lr_delay_mult + (1 - lr_delay_mult) * np.sin( |
| 0.5 * np.pi * np.clip(step / lr_delay_steps, 0, 1) |
| ) |
| else: |
| delay_rate = 1.0 |
| |
| t = np.clip(step / max_steps, 0, 1) |
| log_lerp = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t) |
| |
| return delay_rate * log_lerp |
| |
| return helper |
| def create_from_pcd(self, pcd: BasicPointCloud, spatial_lr_scale: float): |
| """ |
| 从点云数据初始化模型参数。 |
| |
| :param pcd: 点云数据,包含点的位置和颜色。 |
| :param spatial_lr_scale: 空间学习率缩放因子,影响位置参数的学习率。 |
| """ |
| |
| self.spatial_lr_scale = spatial_lr_scale |
| fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda() |
| fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda()) |
| |
| |
| features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda() |
| features[:, :3, 0] = fused_color |
| features[:, 3:, 1:] = 0.0 |
| |
| |
| print("Number of points at initialisation : ", fused_point_cloud.shape[0]) |
| |
| |
| dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001) |
| scales = torch.log(torch.sqrt(dist2))[..., None].repeat(1, 3) |
| |
| |
| rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda") |
| rots[:, 0] = 1 |
| |
| |
| opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda")) |
| |
| |
| self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True)) |
| self._features_dc = nn.Parameter(features[:, :, 0:1].transpose(1, 2).contiguous().requires_grad_(True)) |
| self._features_rest = nn.Parameter(features[:, :, 1:].transpose(1, 2).contiguous().requires_grad_(True)) |
| self._scaling = nn.Parameter(scales.requires_grad_(True)) |
| self._rotation = nn.Parameter(rots.requires_grad_(True)) |
| self._opacity = nn.Parameter(opacities.requires_grad_(True)) |
| self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda") |
| def RGB2SH(rgb): |
| """ |
| 将RGB颜色值转换为球谐系数C0项的系数。 |
| |
| :param rgb: RGB颜色值。 |
| :return: 转换后的球谐系数C0项的系数。 |
| """ |
| return (rgb - 0.5) / C0 |
根据梯度对3d gaussian进行增加或者删除
| def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size): |
| """ |
| 对3D高斯分布进行密集化和修剪的操作 |
| |
| :param max_grad: 梯度的最大阈值,用于判断是否需要克隆或分割。 |
| :param min_opacity: 不透明度的最小阈值,低于此值的3D高斯将被删除。 |
| :param extent: 场景的尺寸范围,用于评估高斯分布的大小是否合适。 |
| :param max_screen_size: 最大屏幕尺寸阈值,用于修剪过大的高斯分布。 |
| """ |
| |
| grads = self.xyz_gradient_accum / self.denom |
| grads[grads.isnan()] = 0.0 |
| |
| |
| self.densify_and_clone(grads, max_grad, extent) |
| self.densify_and_split(grads, max_grad, extent) |
| |
| |
| prune_mask = (self.get_opacity < min_opacity).squeeze() |
| if max_screen_size: |
| big_points_vs = self.max_radii2D > max_screen_size |
| big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent |
| prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws) |
| |
| |
| self.prune_points(prune_mask) |
| |
| |
| torch.cuda.empty_cache() |
| def prune_points(self, mask): |
| """ |
| 删除不符合要求的3D高斯分布。 |
| |
| :param mask: 一个布尔张量,表示需要删除的3D高斯分布。 |
| """ |
| |
| valid_points_mask = ~mask |
| optimizable_tensors = self._prune_optimizer(valid_points_mask) |
| |
| |
| self._xyz = optimizable_tensors["xyz"] |
| self._features_dc = optimizable_tensors["f_dc"] |
| self._features_rest = optimizable_tensors["f_rest"] |
| self._opacity = optimizable_tensors["opacity"] |
| self._scaling = optimizable_tensors["scaling"] |
| self._rotation = optimizable_tensors["rotation"] |
| |
| |
| self.xyz_gradient_accum = self.xyz_gradient_accum[valid_points_mask] |
| self.denom = self.denom[valid_points_mask] |
| self.max_radii2D = self.max_radii2D[valid_points_mask] |
| def _prune_optimizer(self, mask): |
| """ |
| 删除不符合要求的3D高斯分布在优化器中对应的参数 |
| |
| :param mask: 一个布尔张量,表示需要保留的3D高斯分布。 |
| :return: 更新后的可优化张量字典。 |
| """ |
| optimizable_tensors = {} |
| for group in self.optimizer.param_groups: |
| stored_state = self.optimizer.state.get(group['params'][0], None) |
| if stored_state is not None: |
| |
| stored_state["exp_avg"] = stored_state["exp_avg"][mask] |
| stored_state["exp_avg_sq"] = stored_state["exp_avg_sq"][mask] |
| |
| |
| del self.optimizer.state[group['params'][0]] |
| group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(True))) |
| self.optimizer.state[group['params'][0]] = stored_state |
| |
| optimizable_tensors[group["name"]] = group["params"][0] |
| else: |
| group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(True)) |
| optimizable_tensors[group["name"]] = group["params"][0] |
| |
| return optimizable_tensors |
| def densify_and_clone(self, grads, grad_threshold, scene_extent): |
| """ |
| 对那些梯度超过一定阈值且尺度小于一定阈值的3D高斯进行克隆操作。 |
| 这意味着这些高斯在空间中可能表示的细节不足,需要通过克隆来增加细节。 |
| """ |
| |
| selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False) |
| selected_pts_mask = torch.logical_and(selected_pts_mask, |
| torch.max(self.get_scaling, dim=1).values <= self.percent_dense * scene_extent) |
| |
| |
| new_xyz = self._xyz[selected_pts_mask] |
| new_features_dc = self._features_dc[selected_pts_mask] |
| new_features_rest = self._features_rest[selected_pts_mask] |
| new_opacities = self._opacity[selected_pts_mask] |
| new_scaling = self._scaling[selected_pts_mask] |
| new_rotation = self._rotation[selected_pts_mask] |
| |
| |
| self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation) |
| def densify_and_split(self, grads, grad_threshold, scene_extent, N=2): |
| """ |
| 对那些梯度超过一定阈值且尺度大于一定阈值的3D高斯进行分割操作。 |
| 这意味着这些高斯可能过于庞大,覆盖了过多的空间区域,需要分割成更小的部分以提升细节。 |
| """ |
| |
| n_init_points = self.get_xyz.shape[0] |
| padded_grad = torch.zeros((n_init_points), device="cuda") |
| padded_grad[:grads.shape[0]] = grads.squeeze() |
| |
| |
| selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False) |
| selected_pts_mask = torch.logical_and(selected_pts_mask, |
| torch.max(self.get_scaling, dim=1).values > self.percent_dense * scene_extent) |
| |
| |
| stds = self.get_scaling[selected_pts_mask].repeat(N, 1) |
| means = torch.zeros((stds.size(0), 3), device="cuda") |
| samples = torch.normal(mean=means, std=stds) |
| rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N, 1, 1) |
| |
| |
| new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1) |
| |
| |
| new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N, 1) / (0.8 * N)) |
| new_rotation = self._rotation[selected_pts_mask].repeat(N, 1) |
| new_features_dc = self._features_dc[selected_pts_mask].repeat(N, 1, 1) |
| new_features_rest = self._features_rest[selected_pts_mask].repeat(N, 1, 1) |
| new_opacity = self._opacity[selected_pts_mask].repeat(N, 1) |
| |
| |
| self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation) |
| |
| |
| prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool))) |
| self.prune_points(prune_filter) |
| def densification_postfix(self, new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation): |
| """ |
| 将新生成的3D高斯分布的属性添加到模型的参数中。 |
| """ |
| d = {"xyz": new_xyz, |
| "f_dc": new_features_dc, |
| "f_rest": new_features_rest, |
| "opacity": new_opacities, |
| "scaling": new_scaling, |
| "rotation": new_rotation} |
| |
| optimizable_tensors = self.cat_tensors_to_optimizer(d) |
| self._xyz = optimizable_tensors["xyz"] |
| self._features_dc = optimizable_tensors["f_dc"] |
| self._features_rest = optimizable_tensors["f_rest"] |
| self._opacity = optimizable_tensors["opacity"] |
| self._scaling = optimizable_tensors["scaling"] |
| self._rotation = optimizable_tensors["rotation"] |
| |
| self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") |
| self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") |
| self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda") |
| def cat_tensors_to_optimizer(self, tensors_dict): |
| """ |
| 将新的参数张量添加到优化器的参数组中 |
| """ |
| optimizable_tensors = {} |
| for group in self.optimizer.param_groups: |
| extension_tensor = tensors_dict[group["name"]] |
| stored_state = self.optimizer.state.get(group['params'][0], None) |
| if stored_state is not None: |
| stored_state["exp_avg"] = torch.cat((stored_state["exp_avg"], torch.zeros_like(extension_tensor)), dim=0) |
| stored_state["exp_avg_sq"] = torch.cat((stored_state["exp_avg_sq"], torch.zeros_like(extension_tensor)), dim=0) |
| |
| del self.optimizer.state[group['params'][0]] |
| group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True)) |
| self.optimizer.state[group['params'][0]] = stored_state |
| |
| optimizable_tensors[group["name"]] = group["params"][0] |
| else: |
| group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True)) |
| optimizable_tensors[group["name"]] = group["params"][0] |
| |
| return optimizable_tensors |
| def build_rotation(r): |
| """ |
| 根据旋转四元数构建旋转矩阵。 |
| """ |
| norm = torch.sqrt(r[:,0]*r[:,0] + r[:,1]*r[:,1] + r[:,2]*r[:,2] + r[:,3]*r[:,3]) |
| q = r / norm[:, None] |
| R = torch.zeros((q.size(0), 3, 3), device='cuda') |
| |
| ... |
| return R |
学习率更新
| def update_learning_rate(self, iteration): |
| """ |
| 根据当前的迭代次数动态调整xyz参数的学习率 |
| |
| :param iteration: 当前的迭代次数。 |
| """ |
| |
| for param_group in self.optimizer.param_groups: |
| |
| if param_group["name"] == "xyz": |
| |
| lr = self.xyz_scheduler_args(iteration) |
| |
| param_group['lr'] = lr |
| |
| return lr |
重置不透明度
| def reset_opacity(self): |
| """ |
| 重置不透明度参数。这个方法将所有的不透明度值设置为一个较小的值(但不是0),以避免在训练过程中因为不透明度过低而导致的问题。 |
| """ |
| |
| opacities_new = inverse_sigmoid(torch.min(self.get_opacity, torch.ones_like(self.get_opacity) * 0.01)) |
| |
| |
| optimizable_tensors = self.replace_tensor_to_optimizer(opacities_new, "opacity") |
| |
| |
| self._opacity = optimizable_tensors["opacity"] |
| |
| def replace_tensor_to_optimizer(self, tensor, name): |
| """ |
| 将指定的参数张量替换到优化器中,这主要用于更新模型的某些参数(例如不透明度)并确保优化器使用新的参数值。 |
| |
| :param tensor: 新的参数张量。 |
| :param name: 参数的名称,用于在优化器的参数组中定位该参数。 |
| :return: 包含已更新参数的字典。 |
| """ |
| optimizable_tensors = {} |
| for group in self.optimizer.param_groups: |
| |
| if group["name"] == name: |
| |
| stored_state = self.optimizer.state.get(group['params'][0], None) |
| stored_state["exp_avg"] = torch.zeros_like(tensor) |
| stored_state["exp_avg_sq"] = torch.zeros_like(tensor) |
| |
| |
| del self.optimizer.state[group['params'][0]] |
| group["params"][0] = nn.Parameter(tensor.requires_grad_(True)) |
| self.optimizer.state[group['params'][0]] = stored_state |
| |
| |
| optimizable_tensors[group["name"]] = group["params"][0] |
| return optimizable_tensors |
4 图像渲染
| def render(viewpoint_camera, pc: GaussianModel, pipe, bg_color: torch.Tensor, scaling_modifier=1.0, override_color=None): |
| """ |
| 渲染场景的函数。 |
| |
| :param viewpoint_camera: 视点相机,包含视场角、图像尺寸和变换矩阵等信息。 |
| :param pc: 3D高斯模型,代表场景中的点云。 |
| :param pipe: 渲染管线配置,可能包含调试标志等信息。 |
| :param bg_color: 背景颜色,必须是一个GPU上的张量。 |
| :param scaling_modifier: 可选的缩放修正值,用于调整3D高斯的尺度。 |
| :param override_color: 可选的覆盖颜色,如果指定,则所有3D高斯使用这个颜色而不是自身的颜色。 |
| """ |
| |
| |
| screenspace_points = torch.zeros_like(pc.get_xyz, dtype=pc.get_xyz.dtype, requires_grad=True, device="cuda") + 0 |
| try: |
| screenspace_points.retain_grad() |
| except: |
| pass |
| |
| |
| tanfovx = math.tan(viewpoint_camera.FoVx * 0.5) |
| tanfovy = math.tan(viewpoint_camera.FoVy * 0.5) |
| |
| |
| raster_settings = GaussianRasterizationSettings( |
| image_height=int(viewpoint_camera.image_height), |
| image_width=int(viewpoint_camera.image_width), |
| tanfovx=tanfovx, |
| tanfovy=tanfovy, |
| bg=bg_color, |
| scale_modifier=scaling_modifier, |
| viewmatrix=viewpoint_camera.world_view_transform, |
| projmatrix=viewpoint_camera.full_proj_transform, |
| sh_degree=pc.active_sh_degree, |
| campos=viewpoint_camera.camera_center, |
| prefiltered=False, |
| debug=pipe.debug |
| ) |
| |
| |
| rasterizer = GaussianRasterizer(raster_settings=raster_settings) |
| |
| |
| means3D = pc.get_xyz |
| means2D = screenspace_points |
| opacity = pc.get_opacity |
| |
| |
| if pipe.compute_cov3D_python: |
| cov3D_precomp = pc.get_covariance(scaling_modifier) |
| else: |
| scales = pc.get_scaling |
| rotations = pc.get_rotation |
| |
| |
| shs = None |
| colors_precomp = None |
| if override_color is None: |
| if pipe.convert_SHs_python: |
| |
| ... |
| else: |
| shs = pc.get_features |
| else: |
| colors_precomp = override_color |
| |
| |
| rendered_image, radii = rasterizer( |
| means3D=means3D, |
| means2D=means2D, |
| shs=shs, |
| colors_precomp=colors_precomp, |
| opacities=opacity, |
| scales=scales, |
| rotations=rotations, |
| cov3D_precomp=cov3D_precomp) |
| |
| |
| return {"render": rendered_image, |
| "viewspace_points": screenspace_points, |
| "visibility_filter": radii > 0, |
| "radii": radii} |
用于光栅化3d高斯分布的模块
| def __init__(self, raster_settings): |
| """ |
| 初始化光栅化器实例。 |
| |
| :param raster_settings: 光栅化的设置参数,包括图像高度、宽度、视场角、背景颜色、视图和投影矩阵等。 |
| """ |
| super().__init__() |
| self.raster_settings = raster_settings |
| |
| def markVisible(self, positions): |
| """ |
| 标记给定位置的点是否在相机的视锥体内,即判断点是否对相机可见(基于视锥剔除)。 |
| |
| :param positions: 点的位置,通常是3D高斯分布的中心位置。 |
| :return: 一个布尔张量,表示每个点是否可见。 |
| """ |
| with torch.no_grad(): |
| raster_settings = self.raster_settings |
| |
| visible = _C.mark_visible( |
| positions, |
| raster_settings.viewmatrix, |
| raster_settings.projmatrix) |
| |
| return visible |
| |
| def forward(self, means3D, means2D, opacities, shs=None, colors_precomp=None, scales=None, rotations=None, cov3D_precomp=None): |
| """ |
| 光栅化器的前向传播方法,用于将3D高斯分布渲染成2D图像。 |
| |
| :param means3D: 3D高斯分布的中心位置。 |
| :param means2D: 屏幕空间中3D高斯分布的预期位置,用于梯度回传。 |
| :param opacities: 高斯分布的不透明度。 |
| :param shs: 球谐系数,用于从方向光照计算颜色。 |
| :param colors_precomp: 预计算的颜色。 |
| :param scales: 高斯分布的尺度参数。 |
| :param rotations: 高斯分布的旋转参数。 |
| :param cov3D_precomp: 预先计算的3D协方差矩阵。 |
| :return: 光栅化后的2D图像。 |
| """ |
| raster_settings = self.raster_settings |
| |
| |
| if (shs is None and colors_precomp is None) or (shs is not None and colors_precomp is not None): |
| raise Exception('Please provide exactly one of either SHs or precomputed colors!') |
| |
| if ((scales is None or rotations is None) and cov3D_precomp is None) or ((scales is not None or rotations is not None) and cov3D_precomp is not None): |
| raise Exception('Please provide exactly one of either scale/rotation pair or precomputed 3D covariance!') |
| |
| |
| if shs is None: |
| shs = torch.Tensor([]) |
| if colors_precomp is None: |
| colors_precomp = torch.Tensor([]) |
| |
| if scales is None: |
| scales = torch.Tensor([]) |
| if rotations is None: |
| rotations = torch.Tensor([]) |
| if cov3D_precomp is None: |
| cov3D_precomp = torch.Tensor([]) |
| |
| |
| return rasterize_gaussians( |
| means3D, |
| means2D, |
| shs, |
| colors_precomp, |
| opacities, |
| scales, |
| rotations, |
| cov3D_precomp, |
| raster_settings, |
| ) |
| def rasterize_gaussians( |
| means3D, |
| means2D, |
| sh, |
| colors_precomp, |
| opacities, |
| scales, |
| rotations, |
| cov3Ds_precomp, |
| raster_settings, |
| ): |
| return _RasterizeGaussians.apply( |
| means3D, |
| means2D, |
| sh, |
| colors_precomp, |
| opacities, |
| scales, |
| rotations, |
| cov3Ds_precomp, |
| raster_settings, |
| ) |
| |
| |
| class _RasterizeGaussians(torch.autograd.Function): |
| @staticmethod |
| def forward( |
| ctx, |
| means3D, |
| means2D, |
| sh, |
| colors_precomp, |
| opacities, |
| scales, |
| rotations, |
| cov3Ds_precomp, |
| raster_settings, |
| ): |
| |
| args = ( |
| raster_settings.bg, |
| means3D, |
| colors_precomp, |
| opacities, |
| scales, |
| rotations, |
| raster_settings.scale_modifier, |
| cov3Ds_precomp, |
| raster_settings.viewmatrix, |
| raster_settings.projmatrix, |
| raster_settings.tanfovx, |
| raster_settings.tanfovy, |
| raster_settings.image_height, |
| raster_settings.image_width, |
| sh, |
| raster_settings.sh_degree, |
| raster_settings.campos, |
| raster_settings.prefiltered, |
| raster_settings.debug |
| ) |
| |
| |
| if raster_settings.debug: |
| cpu_args = cpu_deep_copy_tuple(args) |
| try: |
| num_rendered, color, radii, geomBuffer, binningBuffer, imgBuffer = _C.rasterize_gaussians(*args) |
| except Exception as ex: |
| torch.save(cpu_args, "snapshot_fw.dump") |
| print("\nAn error occured in forward. Please forward snapshot_fw.dump for debugging.") |
| raise ex |
| else: |
| num_rendered, color, radii, geomBuffer, binningBuffer, imgBuffer = _C.rasterize_gaussians(*args) |
| |
| |
| ctx.raster_settings = raster_settings |
| ctx.num_rendered = num_rendered |
| ctx.save_for_backward(colors_precomp, means3D, scales, rotations, cov3Ds_precomp, radii, sh, geomBuffer, binningBuffer, imgBuffer) |
| return color, radii |
| |
| @staticmethod |
| def backward(ctx, grad_out_color, _): |
| |
| |
| num_rendered = ctx.num_rendered |
| raster_settings = ctx.raster_settings |
| colors_precomp, means3D, scales, rotations, cov3Ds_precomp, radii, sh, geomBuffer, binningBuffer, imgBuffer = ctx.saved_tensors |
| |
| |
| args = (raster_settings.bg, |
| means3D, |
| radii, |
| colors_precomp, |
| scales, |
| rotations, |
| raster_settings.scale_modifier, |
| cov3Ds_precomp, |
| raster_settings.viewmatrix, |
| raster_settings.projmatrix, |
| raster_settings.tanfovx, |
| raster_settings.tanfovy, |
| grad_out_color, |
| sh, |
| raster_settings.sh_degree, |
| raster_settings.campos, |
| geomBuffer, |
| num_rendered, |
| binningBuffer, |
| imgBuffer, |
| raster_settings.debug) |
| |
| |
| if raster_settings.debug: |
| cpu_args = cpu_deep_copy_tuple(args) |
| try: |
| grad_means2D, grad_colors_precomp, grad_opacities, grad_means3D, grad_cov3Ds_precomp, grad_sh, grad_scales, grad_rotations = _C.rasterize_gaussians_backward(*args) |
| except Exception as ex: |
| torch.save(cpu_args, "snapshot_bw.dump") |
| print("\nAn error occured in backward. Writing snapshot_bw.dump for debugging.\n") |
| raise ex |
| else: |
| grad_means2D, grad_colors_precomp, grad_opacities, grad_means3D, grad_cov3Ds_precomp, grad_sh, grad_scales, grad_rotations = _C.rasterize_gaussians_backward(*args) |
| |
| grads = ( |
| grad_means3D, |
| grad_means2D, |
| grad_sh, |
| grad_colors_precomp, |
| grad_opacities, |
| grad_scales, |
| grad_rotations, |
| grad_cov3Ds_precomp, |
| None, |
| ) |
| |
| return grads |
图像渲染cuda实现部分
| PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) { |
| m.def("rasterize_gaussians", &RasterizeGaussiansCUDA); |
| m.def("rasterize_gaussians_backward", &RasterizeGaussiansBackwardCUDA); |
| m.def("mark_visible", &markVisible); |
| } |
| |
| |
| std::function<char*(size_t n)=""> resizeFunctional(torch::Tensor& t) { |
| auto lambda = [&t](size_t N) { |
| t.resize_({(long long)N}); |
| return reinterpret_cast<char*>(t.contiguous().data_ptr()); |
| }; |
| return lambda; |
| } |
| |
| std::tuple<int, torch::tensor,="" torch::tensor=""> |
| RasterizeGaussiansCUDA( |
| const torch::Tensor& background, |
| const torch::Tensor& means3D, |
| const torch::Tensor& colors, |
| const torch::Tensor& opacity, |
| const torch::Tensor& scales, |
| const torch::Tensor& rotations, |
| const float scale_modifier, |
| const torch::Tensor& cov3D_precomp, |
| const torch::Tensor& viewmatrix, |
| const torch::Tensor& projmatrix, |
| const float tan_fovx, |
| const float tan_fovy, |
| const int image_height, |
| const int image_width, |
| const torch::Tensor& sh, |
| const int degree, |
| const torch::Tensor& campos, |
| const bool prefiltered, |
| const bool debug) |
| { |
| if (means3D.ndimension() != 2 || means3D.size(1) != 3) { |
| AT_ERROR("means3D must have dimensions (num_points, 3)"); |
| } |
| |
| const int P = means3D.size(0); |
| const int H = image_height; |
| const int W = image_width; |
| |
| auto int_opts = means3D.options().dtype(torch::kInt32); |
| auto float_opts = means3D.options().dtype(torch::kFloat32); |
| |
| torch::Tensor out_color = torch::full({NUM_CHANNELS, H, W}, 0.0, float_opts); |
| torch::Tensor radii = torch::full({P}, 0, means3D.options().dtype(torch::kInt32)); |
| |
| torch::Device device(torch::kCUDA); |
| torch::TensorOptions options(torch::kByte); |
| torch::Tensor geomBuffer = torch::empty({0}, options.device(device)); |
| torch::Tensor binningBuffer = torch::empty({0}, options.device(device)); |
| torch::Tensor imgBuffer = torch::empty({0}, options.device(device)); |
| std::function<char*(size_t)> geomFunc = resizeFunctional(geomBuffer); |
| std::function<char*(size_t)> binningFunc = resizeFunctional(binningBuffer); |
| std::function<char*(size_t)> imgFunc = resizeFunctional(imgBuffer); |
| |
| int rendered = 0; |
| if(P != 0) |
| { |
| int M = 0; |
| if(sh.size(0) != 0) |
| { |
| M = sh.size(1); |
| } |
| |
| rendered = CudaRasterizer::Rasterizer::forward( |
| geomFunc, |
| binningFunc, |
| imgFunc, |
| P, degree, M, |
| background.contiguous().data<float>(), |
| W, H, |
| means3D.contiguous().data<float>(), |
| sh.contiguous().data_ptr<float>(), |
| colors.contiguous().data<float>(), |
| opacity.contiguous().data<float>(), |
| scales.contiguous().data_ptr<float>(), |
| scale_modifier, |
| rotations.contiguous().data_ptr<float>(), |
| cov3D_precomp.contiguous().data<float>(), |
| viewmatrix.contiguous().data<float>(), |
| projmatrix.contiguous().data<float>(), |
| campos.contiguous().data<float>(), |
| tan_fovx, |
| tan_fovy, |
| prefiltered, |
| out_color.contiguous().data<float>(), |
| radii.contiguous().data<int>(), |
| debug); |
| } |
| return std::make_tuple(rendered, out_color, radii, geomBuffer, binningBuffer, imgBuffer); |
| } |
| |
| |
| |
| int CudaRasterizer::Rasterizer::forward( |
| std::function<char* (size_t)=""> geometryBuffer, |
| std::function<char* (size_t)=""> binningBuffer, |
| std::function<char* (size_t)=""> imageBuffer, |
| const int P, int D, int M, |
| const float* background, |
| const int width, int height, |
| const float* means3D, |
| const float* shs, |
| const float* colors_precomp, |
| const float* opacities, |
| const float* scales, |
| const float scale_modifier, |
| const float* rotations, |
| const float* cov3D_precomp, |
| const float* viewmatrix, |
| const float* projmatrix, |
| const float* cam_pos, |
| const float tan_fovx, float tan_fovy, |
| const bool prefiltered, |
| float* out_color, |
| int* radii, |
| bool debug) |
| { |
| const float focal_y = height / (2.0f * tan_fovy); |
| const float focal_x = width / (2.0f * tan_fovx); |
| |
| size_t chunk_size = required<geometrystate>(P); |
| char* chunkptr = geometryBuffer(chunk_size); |
| GeometryState geomState = GeometryState::fromChunk(chunkptr, P); |
| |
| if (radii == nullptr) |
| { |
| radii = geomState.internal_radii; |
| } |
| |
| |
| dim3 tile_grid((width + BLOCK_X - 1) / BLOCK_X, (height + BLOCK_Y - 1) / BLOCK_Y, 1); |
| |
| dim3 block(BLOCK_X, BLOCK_Y, 1); |
| |
| |
| size_t img_chunk_size = required<imagestate>(width * height); |
| char* img_chunkptr = imageBuffer(img_chunk_size); |
| ImageState imgState = ImageState::fromChunk(img_chunkptr, width * height); |
| |
| if (NUM_CHANNELS != 3 && colors_precomp == nullptr) |
| { |
| throw std::runtime_error("For non-RGB, provide precomputed Gaussian colors!"); |
| } |
| |
| |
| CHECK_CUDA(FORWARD::preprocess( |
| P, D, M, |
| means3D, |
| (glm::vec3*)scales, |
| scale_modifier, |
| (glm::vec4*)rotations, |
| opacities, |
| shs, |
| geomState.clamped, |
| cov3D_precomp, |
| colors_precomp, |
| viewmatrix, |
| projmatrix, |
| (glm::vec3*)cam_pos, |
| width, height, |
| focal_x, focal_y, |
| tan_fovx, tan_fovy, |
| radii, |
| geomState.means2D, |
| geomState.depths, |
| geomState.cov3D, |
| geomState.rgb, |
| geomState.conic_opacity, |
| tile_grid, |
| geomState.tiles_touched, |
| prefiltered |
| ), debug) |
| |
| |
| |
| CHECK_CUDA(cub::DeviceScan::InclusiveSum(geomState.scanning_space, geomState.scan_size, geomState.tiles_touched, geomState.point_offsets, P), debug) |
| |
| |
| int num_rendered; |
| |
| CHECK_CUDA(cudaMemcpy(&num_rendered, geomState.point_offsets + P - 1, sizeof(int), cudaMemcpyDeviceToHost), debug); |
| |
| size_t binning_chunk_size = required<binningstate>(num_rendered); |
| char* binning_chunkptr = binningBuffer(binning_chunk_size); |
| BinningState binningState = BinningState::fromChunk(binning_chunkptr, num_rendered); |
| |
| |
| |
| |
| |
| duplicateWithKeys << <(P + 255) / 256, 256 >> > ( |
| P, |
| geomState.means2D, |
| geomState.depths, |
| geomState.point_offsets, |
| binningState.point_list_keys_unsorted, |
| binningState.point_list_unsorted, |
| radii, |
| tile_grid) |
| CHECK_CUDA(, debug) |
| |
| int bit = getHigherMsb(tile_grid.x * tile_grid.y); |
| |
| |
| |
| |
| |
| |
| CHECK_CUDA(cub::DeviceRadixSort::SortPairs( |
| binningState.list_sorting_space, |
| binningState.sorting_size, |
| binningState.point_list_keys_unsorted, binningState.point_list_keys, |
| binningState.point_list_unsorted, binningState.point_list, |
| num_rendered, 0, 32 + bit), debug) |
| |
| |
| CHECK_CUDA(cudaMemset(imgState.ranges, 0, tile_grid.x * tile_grid.y * sizeof(uint2)), debug); |
| |
| |
| |
| |
| if (num_rendered > 0) |
| identifyTileRanges << <(num_rendered + 255) / 256, 256 >> > ( |
| num_rendered, |
| binningState.point_list_keys, |
| imgState.ranges); |
| CHECK_CUDA(, debug) |
| |
| |
| const float* feature_ptr = colors_precomp != nullptr ? colors_precomp : geomState.rgb; |
| CHECK_CUDA(FORWARD::render( |
| tile_grid, |
| block, |
| imgState.ranges, |
| binningState.point_list, |
| width, height, |
| geomState.means2D, |
| feature_ptr, |
| geomState.conic_opacity, |
| imgState.accum_alpha, |
| imgState.n_contrib, |
| background, |
| out_color), debug) |
| |
| return num_rendered; |
| } |
| |
| |
| |
| __global__ void duplicateWithKeys( |
| int P, |
| const float2* points_xy, |
| const float* depths, |
| const uint32_t* offsets, |
| uint64_t* gaussian_keys_unsorted, |
| uint32_t* gaussian_values_unsorted, |
| int* radii, |
| dim3 grid) |
| { |
| auto idx = cg::this_grid().thread_rank(); |
| if (idx >= P) |
| return; |
| |
| if (radii[idx] > 0) |
| { |
| |
| uint32_t off = (idx == 0) ? 0 : offsets[idx - 1]; |
| uint2 rect_min, rect_max; |
| |
| getRect(points_xy[idx], radii[idx], rect_min, rect_max, grid); |
| |
| |
| |
| |
| |
| for (int y = rect_min.y; y < rect_max.y; y++) |
| { |
| for (int x = rect_min.x; x < rect_max.x; x++) |
| { |
| uint64_t key = y * grid.x + x; |
| key <<= 32; |
| key |= *((uint32_t*)&depths[idx]); |
| gaussian_keys_unsorted[off] = key; |
| gaussian_values_unsorted[off] = idx; |
| off++; |
| } |
| } |
| } |
| } |
| |
| |
| __forceinline__ __device__ void getRect(const float2 p, int max_radius, uint2& rect_min, uint2& rect_max, dim3 grid) |
| { |
| rect_min = { |
| min(grid.x, max((int)0, (int)((p.x - max_radius) / BLOCK_X))), |
| min(grid.y, max((int)0, (int)((p.y - max_radius) / BLOCK_Y))) |
| }; |
| rect_max = { |
| min(grid.x, max((int)0, (int)((p.x + max_radius + BLOCK_X - 1) / BLOCK_X))), |
| min(grid.y, max((int)0, (int)((p.y + max_radius + BLOCK_Y - 1) / BLOCK_Y))) |
| }; |
| } |
| |
| |
| |
| |
| uint32_t getHigherMsb(uint32_t n) |
| { |
| uint32_t msb = sizeof(n) * 4; |
| uint32_t step = msb; |
| while (step > 1) |
| { |
| step /= 2; |
| if (n >> msb) |
| msb += step; |
| else |
| msb -= step; |
| } |
| if (n >> msb) |
| msb++; |
| return msb; |
| } |
| |
| |
| |
| |
| |
| |
| __global__ void identifyTileRanges(int L, uint64_t* point_list_keys, uint2* ranges) |
| { |
| auto idx = cg::this_grid().thread_rank(); |
| if (idx >= L) |
| return; |
| |
| |
| uint64_t key = point_list_keys[idx]; |
| uint32_t currtile = key >> 32; |
| if (idx == 0) |
| ranges[currtile].x = 0; |
| else |
| { |
| uint32_t prevtile = point_list_keys[idx - 1] >> 32; |
| if (currtile != prevtile) |
| { |
| ranges[prevtile].y = idx; |
| ranges[currtile].x = idx; |
| } |
| } |
| if (idx == L - 1) |
| ranges[currtile].y = L; |
| } |
| |
| |
| |
| |
| size_t required(size_t P) |
| { |
| char* size = nullptr; |
| T::fromChunk(size, P); |
| return ((size_t)size) + 128; |
| } |
| |
| |
| |
| |
| static void obtain(char*& chunk, T*& ptr, std::size_t count, std::size_t alignment) |
| { |
| std::size_t offset = (reinterpret_cast<std::uintptr_t>(chunk) + alignment - 1) & ~(alignment - 1); |
| ptr = reinterpret_cast<t*>(offset); |
| chunk = reinterpret_cast<char*>(ptr + count); |
| } |
| |
| |
| struct GeometryState |
| { |
| size_t scan_size; |
| float* depths; |
| char* scanning_space; |
| bool* clamped; |
| int* internal_radii; |
| float2* means2D; |
| float* cov3D; |
| float4* conic_opacity; |
| float* rgb; |
| uint32_t* point_offsets; |
| uint32_t* tiles_touched; |
| |
| static GeometryState fromChunk(char*& chunk, size_t P); |
| }; |
| |
| |
| |
| |
| CudaRasterizer::GeometryState CudaRasterizer::GeometryState::fromChunk(char*& chunk, size_t P) |
| { |
| GeometryState geom; |
| obtain(chunk, geom.depths, P, 128); |
| obtain(chunk, geom.clamped, P * 3, 128); |
| obtain(chunk, geom.internal_radii, P, 128); |
| obtain(chunk, geom.means2D, P, 128); |
| obtain(chunk, geom.cov3D, P * 6, 128); |
| obtain(chunk, geom.conic_opacity, P, 128); |
| obtain(chunk, geom.rgb, P * 3, 128); |
| obtain(chunk, geom.tiles_touched, P, 128); |
| cub::DeviceScan::InclusiveSum(nullptr, geom.scan_size, geom.tiles_touched, geom.tiles_touched, P); |
| obtain(chunk, geom.scanning_space, geom.scan_size, 128); |
| obtain(chunk, geom.point_offsets, P, 128); |
| return geom; |
| } |
| |
| struct ImageState |
| { |
| uint2* ranges; |
| uint32_t* n_contrib; |
| float* accum_alpha; |
| |
| static ImageState fromChunk(char*& chunk, size_t N); |
| }; |
| |
| CudaRasterizer::ImageState CudaRasterizer::ImageState::fromChunk(char*& chunk, size_t N) |
| { |
| ImageState img; |
| obtain(chunk, img.accum_alpha, N, 128); |
| obtain(chunk, img.n_contrib, N, 128); |
| obtain(chunk, img.ranges, N, 128); |
| return img; |
| } |
| |
| struct BinningState |
| { |
| size_t sorting_size; |
| uint64_t* point_list_keys_unsorted; |
| uint64_t* point_list_keys; |
| uint32_t* point_list_unsorted; |
| uint32_t* point_list; |
| char* list_sorting_space; |
| |
| static BinningState fromChunk(char*& chunk, size_t P); |
| }; |
| |
| |
| CudaRasterizer::BinningState CudaRasterizer::BinningState::fromChunk(char*& chunk, size_t P) |
| { |
| BinningState binning; |
| obtain(chunk, binning.point_list, P, 128); |
| obtain(chunk, binning.point_list_unsorted, P, 128); |
| obtain(chunk, binning.point_list_keys, P, 128); |
| obtain(chunk, binning.point_list_keys_unsorted, P, 128); |
| |
| cub::DeviceRadixSort::SortPairs( |
| nullptr, binning.sorting_size, |
| binning.point_list_keys_unsorted, binning.point_list_keys, |
| binning.point_list_unsorted, binning.point_list, P); |
| obtain(chunk, binning.list_sorting_space, binning.sorting_size, 128); |
| return binning; |
| } |
cuda前向传播预处理
| void FORWARD::preprocess(int P, int D, int M, |
| const float* means3D, |
| const glm::vec3* scales, |
| const float scale_modifier, |
| const glm::vec4* rotations, |
| const float* opacities, |
| const float* shs, |
| bool* clamped, |
| const float* cov3D_precomp, |
| const float* colors_precomp, |
| const float* viewmatrix, |
| const float* projmatrix, |
| const glm::vec3* cam_pos, |
| const int W, int H, |
| const float focal_x, float focal_y, |
| const float tan_fovx, float tan_fovy, |
| int* radii, |
| float2* means2D, |
| float* depths, |
| float* cov3Ds, |
| float* rgb, |
| float4* conic_opacity, |
| const dim3 grid, |
| uint32_t* tiles_touched, |
| bool prefiltered) |
| { |
| preprocessCUDA<num_channels> << <(P + 255) / 256, 256 >> > ( |
| P, D, M, |
| means3D, |
| scales, |
| scale_modifier, |
| rotations, |
| opacities, |
| shs, |
| clamped, |
| cov3D_precomp, |
| colors_precomp, |
| viewmatrix, |
| projmatrix, |
| cam_pos, |
| W, H, |
| tan_fovx, tan_fovy, |
| focal_x, focal_y, |
| radii, |
| means2D, |
| depths, |
| cov3Ds, |
| rgb, |
| conic_opacity, |
| grid, |
| tiles_touched, |
| prefiltered |
| ); |
| } |
| |
| |
| template<int c=""> |
| __global__ void preprocessCUDA(int P, int D, int M, |
| const float* orig_points, |
| const glm::vec3* scales, |
| const float scale_modifier, |
| const glm::vec4* rotations, |
| const float* opacities, |
| const float* shs, |
| bool* clamped, |
| const float* cov3D_precomp, |
| const float* colors_precomp, |
| const float* viewmatrix, |
| const float* projmatrix, |
| const glm::vec3* cam_pos, |
| const int W, int H, |
| const float tan_fovx, float tan_fovy, |
| const float focal_x, float focal_y, |
| int* radii, |
| float2* points_xy_image, |
| float* depths, |
| float* cov3Ds, |
| float* rgb, |
| float4* conic_opacity, |
| const dim3 grid, |
| uint32_t* tiles_touched, |
| bool prefiltered) |
| { |
| |
| auto idx = cg::this_grid().thread_rank(); |
| if (idx >= P) |
| return; |
| |
| |
| |
| radii[idx] = 0; |
| tiles_touched[idx] = 0; |
| |
| |
| |
| float3 p_view; |
| if (!in_frustum(idx, orig_points, viewmatrix, projmatrix, prefiltered, p_view)) |
| return; |
| |
| |
| float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] }; |
| |
| float4 p_hom = transformPoint4x4(p_orig, projmatrix); |
| float p_w = 1.0f / (p_hom.w + 0.0000001f); |
| |
| float3 p_proj = { p_hom.x * p_w, p_hom.y * p_w, p_hom.z * p_w }; |
| |
| |
| |
| const float* cov3D; |
| if (cov3D_precomp != nullptr) |
| { |
| cov3D = cov3D_precomp + idx * 6; |
| } |
| else |
| { |
| |
| computeCov3D(scales[idx], scale_modifier, rotations[idx], cov3Ds + idx * 6); |
| cov3D = cov3Ds + idx * 6; |
| } |
| |
| |
| |
| float3 cov = computeCov2D(p_orig, focal_x, focal_y, tan_fovx, tan_fovy, cov3D, viewmatrix); |
| |
| |
| |
| float det = (cov.x * cov.z - cov.y * cov.y); |
| if (det == 0.0f) |
| return; |
| float det_inv = 1.f / det; |
| float3 conic = { cov.z * det_inv, -cov.y * det_inv, cov.x * det_inv }; |
| |
| |
| |
| |
| |
| |
| |
| float mid = 0.5f * (cov.x + cov.z); |
| float lambda1 = mid + sqrt(max(0.1f, mid * mid - det)); |
| float lambda2 = mid - sqrt(max(0.1f, mid * mid - det)); |
| float my_radius = ceil(3.f * sqrt(max(lambda1, lambda2))); |
| |
| |
| float2 point_image = { ndc2Pix(p_proj.x, W), ndc2Pix(p_proj.y, H) }; |
| uint2 rect_min, rect_max; |
| |
| |
| getRect(point_image, my_radius, rect_min, rect_max, grid); |
| |
| if ((rect_max.x - rect_min.x) * (rect_max.y - rect_min.y) == 0) |
| return; |
| |
| |
| |
| if (colors_precomp == nullptr) |
| { |
| |
| glm::vec3 result = computeColorFromSH(idx, D, M, (glm::vec3*)orig_points, *cam_pos, shs, clamped); |
| rgb[idx * C + 0] = result.x; |
| rgb[idx * C + 1] = result.y; |
| rgb[idx * C + 2] = result.z; |
| } |
| |
| |
| depths[idx] = p_view.z; |
| radii[idx] = my_radius; |
| points_xy_image[idx] = point_image; |
| |
| conic_opacity[idx] = { conic.x, conic.y, conic.z, opacities[idx] }; |
| tiles_touched[idx] = (rect_max.y - rect_min.y) * (rect_max.x - rect_min.x); |
| } |
| |
| |
| __forceinline__ __device__ bool in_frustum(int idx, |
| const float* orig_points, |
| const float* viewmatrix, |
| const float* projmatrix, |
| bool prefiltered, |
| float3& p_view) |
| { |
| float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] }; |
| |
| |
| |
| float4 p_hom = transformPoint4x4(p_orig, projmatrix); |
| float p_w = 1.0f / (p_hom.w + 0.0000001f); |
| float3 p_proj = { p_hom.x * p_w, p_hom.y * p_w, p_hom.z * p_w }; |
| |
| p_view = transformPoint4x3(p_orig, viewmatrix); |
| |
| if (p_view.z <= 0.2f) |
| { |
| if (prefiltered) |
| { |
| printf("Point is filtered although prefiltered is set. This shouldn't happen!"); |
| __trap(); |
| } |
| return false; |
| } |
| return true; |
| } |
| |
| |
| |
| |
| |
| __device__ void computeCov3D(const glm::vec3 scale, float mod, const glm::vec4 rot, float* cov3D) |
| { |
| |
| glm::mat3 S = glm::mat3(1.0f); |
| S[0][0] = mod * scale.x; |
| S[1][1] = mod * scale.y; |
| S[2][2] = mod * scale.z; |
| |
| |
| glm::vec4 q = rot; |
| float r = q.x; |
| float x = q.y; |
| float y = q.z; |
| float z = q.w; |
| |
| |
| glm::mat3 R = glm::mat3( |
| 1.f - 2.f * (y * y + z * z), 2.f * (x * y - r * z), 2.f * (x * z + r * y), |
| 2.f * (x * y + r * z), 1.f - 2.f * (x * x + z * z), 2.f * (y * z - r * x), |
| 2.f * (x * z - r * y), 2.f * (y * z + r * x), 1.f - 2.f * (x * x + y * y) |
| ); |
| |
| glm::mat3 M = S * R; |
| |
| |
| glm::mat3 Sigma = glm::transpose(M) * M; |
| |
| |
| cov3D[0] = Sigma[0][0]; |
| cov3D[1] = Sigma[0][1]; |
| cov3D[2] = Sigma[0][2]; |
| cov3D[3] = Sigma[1][1]; |
| cov3D[4] = Sigma[1][2]; |
| cov3D[5] = Sigma[2][2]; |
| } |
| |
| |
| __device__ float3 computeCov2D(const float3& mean, float focal_x, float focal_y, float tan_fovx, float tan_fovy, const float* cov3D, const float* viewmatrix) |
| { |
| |
| |
| |
| |
| |
| float3 t = transformPoint4x3(mean, viewmatrix); |
| |
| const float limx = 1.3f * tan_fovx; |
| const float limy = 1.3f * tan_fovy; |
| const float txtz = t.x / t.z; |
| const float tytz = t.y / t.z; |
| t.x = min(limx, max(-limx, txtz)) * t.z; |
| t.y = min(limy, max(-limy, tytz)) * t.z; |
| |
| |
| glm::mat3 J = glm::mat3( |
| focal_x / t.z, 0.0f, -(focal_x * t.x) / (t.z * t.z), |
| 0.0f, focal_y / t.z, -(focal_y * t.y) / (t.z * t.z), |
| 0, 0, 0); |
| |
| glm::mat3 W = glm::mat3( |
| viewmatrix[0], viewmatrix[4], viewmatrix[8], |
| viewmatrix[1], viewmatrix[5], viewmatrix[9], |
| viewmatrix[2], viewmatrix[6], viewmatrix[10]); |
| |
| glm::mat3 T = W * J; |
| |
| glm::mat3 Vrk = glm::mat3( |
| cov3D[0], cov3D[1], cov3D[2], |
| cov3D[1], cov3D[3], cov3D[4], |
| cov3D[2], cov3D[4], cov3D[5]); |
| |
| glm::mat3 cov = glm::transpose(T) * glm::transpose(Vrk) * T; |
| |
| |
| |
| cov[0][0] += 0.3f; |
| cov[1][1] += 0.3f; |
| return { float(cov[0][0]), float(cov[0][1]), float(cov[1][1]) }; |
| } |
| |
| |
| |
| |
| __device__ glm::vec3 computeColorFromSH(int idx, int deg, int max_coeffs, const glm::vec3* means, glm::vec3 campos, const float* shs, bool* clamped) |
| { |
| |
| |
| |
| glm::vec3 pos = means[idx]; |
| glm::vec3 dir = pos - campos; |
| dir = dir / glm::length(dir); |
| |
| glm::vec3* sh = ((glm::vec3*)shs) + idx * max_coeffs; |
| glm::vec3 result = SH_C0 * sh[0]; |
| |
| if (deg > 0) |
| { |
| float x = dir.x; |
| float y = dir.y; |
| float z = dir.z; |
| result = result - SH_C1 * y * sh[1] + SH_C1 * z * sh[2] - SH_C1 * x * sh[3]; |
| |
| if (deg > 1) |
| { |
| float xx = x * x, yy = y * y, zz = z * z; |
| float xy = x * y, yz = y * z, xz = x * z; |
| result = result + |
| SH_C2[0] * xy * sh[4] + |
| SH_C2[1] * yz * sh[5] + |
| SH_C2[2] * (2.0f * zz - xx - yy) * sh[6] + |
| SH_C2[3] * xz * sh[7] + |
| SH_C2[4] * (xx - yy) * sh[8]; |
| |
| if (deg > 2) |
| { |
| result = result + |
| SH_C3[0] * y * (3.0f * xx - yy) * sh[9] + |
| SH_C3[1] * xy * z * sh[10] + |
| SH_C3[2] * y * (4.0f * zz - xx - yy) * sh[11] + |
| SH_C3[3] * z * (2.0f * zz - 3.0f * xx - 3.0f * yy) * sh[12] + |
| SH_C3[4] * x * (4.0f * zz - xx - yy) * sh[13] + |
| SH_C3[5] * z * (xx - yy) * sh[14] + |
| SH_C3[6] * x * (xx - 3.0f * yy) * sh[15]; |
| } |
| } |
| } |
| result += 0.5f; |
| |
| |
| |
| clamped[3 * idx + 0] = (result.x < 0); |
| clamped[3 * idx + 1] = (result.y < 0); |
| clamped[3 * idx + 2] = (result.z < 0); |
| return glm::max(result, 0.0f); |
| } |
| |
| |
| __forceinline__ __device__ void getRect(const float2 p, int max_radius, uint2& rect_min, uint2& rect_max, dim3 grid) |
| { |
| rect_min = { |
| min(grid.x, max((int)0, (int)((p.x - max_radius) / BLOCK_X))), |
| min(grid.y, max((int)0, (int)((p.y - max_radius) / BLOCK_Y))) |
| }; |
| rect_max = { |
| min(grid.x, max((int)0, (int)((p.x + max_radius + BLOCK_X - 1) / BLOCK_X))), |
| min(grid.y, max((int)0, (int)((p.y + max_radius + BLOCK_Y - 1) / BLOCK_Y))) |
| }; |
| } |
| |
| __forceinline__ __device__ float3 transformPoint4x3(const float3& p, const float* matrix) |
| { |
| float3 transformed = { |
| matrix[0] * p.x + matrix[4] * p.y + matrix[8] * p.z + matrix[12], |
| matrix[1] * p.x + matrix[5] * p.y + matrix[9] * p.z + matrix[13], |
| matrix[2] * p.x + matrix[6] * p.y + matrix[10] * p.z + matrix[14], |
| }; |
| return transformed; |
| } |
| |
| __forceinline__ __device__ float4 transformPoint4x4(const float3& p, const float* matrix) |
| { |
| float4 transformed = { |
| matrix[0] * p.x + matrix[4] * p.y + matrix[8] * p.z + matrix[12], |
| matrix[1] * p.x + matrix[5] * p.y + matrix[9] * p.z + matrix[13], |
| matrix[2] * p.x + matrix[6] * p.y + matrix[10] * p.z + matrix[14], |
| matrix[3] * p.x + matrix[7] * p.y + matrix[11] * p.z + matrix[15] |
| }; |
| return transformed; |
| } |
| |
| |
| __forceinline__ __device__ float ndc2Pix(float v, int S) |
| { |
| return ((v + 1.0) * S - 1.0) * 0.5; |
| } |
cuda前传渲染
| void FORWARD::render( |
| const dim3 grid, dim3 block, |
| const uint2* ranges, |
| const uint32_t* point_list, |
| int W, int H, |
| const float2* means2D, |
| const float* colors, |
| const float4* conic_opacity, |
| float* final_T, |
| uint32_t* n_contrib, |
| const float* bg_color, |
| float* out_color) |
| { |
| renderCUDA<num_channels> << <grid, block="">> > ( |
| ranges, |
| point_list, |
| W, H, |
| means2D, |
| colors, |
| conic_opacity, |
| final_T, |
| n_contrib, |
| bg_color, |
| out_color); |
| } |
| |
| |
| |
| |
| |
| template <uint32_t channels=""> |
| __global__ void __launch_bounds__(BLOCK_X * BLOCK_Y) |
| renderCUDA( |
| const uint2* __restrict__ ranges, |
| const uint32_t* __restrict__ point_list, |
| int W, int H, |
| const float2* __restrict__ points_xy_image, |
| const float* __restrict__ features, |
| const float4* __restrict__ conic_opacity, |
| float* __restrict__ final_T, |
| uint32_t* __restrict__ n_contrib, |
| const float* __restrict__ bg_color, |
| float* __restrict__ out_color) |
| { |
| |
| auto block = cg::this_thread_block(); |
| uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X; |
| |
| uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y }; |
| |
| uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) }; |
| |
| uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y }; |
| |
| uint32_t pix_id = W * pix.y + pix.x; |
| |
| float2 pixf = { (float)pix.x, (float)pix.y }; |
| |
| |
| bool inside = pix.x < W&& pix.y < H; |
| |
| bool done = !inside; |
| |
| |
| |
| uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x]; |
| const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE); |
| |
| int toDo = range.y - range.x; |
| |
| |
| __shared__ int collected_id[BLOCK_SIZE]; |
| __shared__ float2 collected_xy[BLOCK_SIZE]; |
| __shared__ float4 collected_conic_opacity[BLOCK_SIZE]; |
| |
| |
| float T = 1.0f; |
| uint32_t contributor = 0; |
| uint32_t last_contributor = 0; |
| float C[CHANNELS] = { 0 }; |
| |
| |
| for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE) |
| { |
| |
| int num_done = __syncthreads_count(done); |
| if (num_done == BLOCK_SIZE) |
| break; |
| |
| |
| int progress = i * BLOCK_SIZE + block.thread_rank(); |
| if (range.x + progress < range.y) |
| { |
| |
| int coll_id = point_list[range.x + progress]; |
| collected_id[block.thread_rank()] = coll_id; |
| collected_xy[block.thread_rank()] = points_xy_image[coll_id]; |
| collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id]; |
| } |
| block.sync(); |
| |
| |
| for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++) |
| { |
| |
| contributor++; |
| |
| |
| |
| float2 xy = collected_xy[j]; |
| float2 d = { xy.x - pixf.x, xy.y - pixf.y }; |
| float4 con_o = collected_conic_opacity[j]; |
| |
| float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y; |
| if (power > 0.0f) |
| continue; |
| |
| |
| |
| |
| |
| float alpha = min(0.99f, con_o.w * exp(power)); |
| if (alpha < 1.0f / 255.0f) |
| continue; |
| float test_T = T * (1 - alpha); |
| if (test_T < 0.0001f) |
| { |
| done = true; |
| continue; |
| } |
| |
| |
| for (int ch = 0; ch < CHANNELS; ch++) |
| C[ch] += features[collected_id[j] * CHANNELS + ch] * alpha * T; |
| |
| T = test_T; |
| |
| |
| |
| last_contributor = contributor; |
| } |
| } |
| |
| |
| |
| if (inside) |
| { |
| final_T[pix_id] = T; |
| n_contrib[pix_id] = last_contributor; |
| for (int ch = 0; ch < CHANNELS; ch++) |
| out_color[ch * H * W + pix_id] = C[ch] + T * bg_color[ch]; |
| } |
| } |
cuda反向传播代码
| std::tuple<torch::tensor, torch::tensor,="" torch::tensor=""> |
| RasterizeGaussiansBackwardCUDA( |
| const torch::Tensor& background, |
| const torch::Tensor& means3D, |
| const torch::Tensor& radii, |
| const torch::Tensor& colors, |
| const torch::Tensor& scales, |
| const torch::Tensor& rotations, |
| const float scale_modifier, |
| const torch::Tensor& cov3D_precomp, |
| const torch::Tensor& viewmatrix, |
| const torch::Tensor& projmatrix, |
| const float tan_fovx, |
| const float tan_fovy, |
| const torch::Tensor& dL_dout_color, |
| const torch::Tensor& sh, |
| const int degree, |
| const torch::Tensor& campos, |
| const torch::Tensor& geomBuffer, |
| const int R, |
| const torch::Tensor& binningBuffer, |
| const torch::Tensor& imageBuffer, |
| const bool debug) |
| { |
| const int P = means3D.size(0); |
| const int H = dL_dout_color.size(1); |
| const int W = dL_dout_color.size(2); |
| |
| int M = 0; |
| if(sh.size(0) != 0) |
| { |
| M = sh.size(1); |
| } |
| |
| torch::Tensor dL_dmeans3D = torch::zeros({P, 3}, means3D.options()); |
| torch::Tensor dL_dmeans2D = torch::zeros({P, 3}, means3D.options()); |
| torch::Tensor dL_dcolors = torch::zeros({P, NUM_CHANNELS}, means3D.options()); |
| torch::Tensor dL_dconic = torch::zeros({P, 2, 2}, means3D.options()); |
| torch::Tensor dL_dopacity = torch::zeros({P, 1}, means3D.options()); |
| torch::Tensor dL_dcov3D = torch::zeros({P, 6}, means3D.options()); |
| torch::Tensor dL_dsh = torch::zeros({P, M, 3}, means3D.options()); |
| torch::Tensor dL_dscales = torch::zeros({P, 3}, means3D.options()); |
| torch::Tensor dL_drotations = torch::zeros({P, 4}, means3D.options()); |
| |
| if(P != 0) |
| { |
| CudaRasterizer::Rasterizer::backward(P, degree, M, R, |
| background.contiguous().data<float>(), |
| W, H, |
| means3D.contiguous().data<float>(), |
| sh.contiguous().data<float>(), |
| colors.contiguous().data<float>(), |
| scales.data_ptr<float>(), |
| scale_modifier, |
| rotations.data_ptr<float>(), |
| cov3D_precomp.contiguous().data<float>(), |
| viewmatrix.contiguous().data<float>(), |
| projmatrix.contiguous().data<float>(), |
| campos.contiguous().data<float>(), |
| tan_fovx, |
| tan_fovy, |
| radii.contiguous().data<int>(), |
| reinterpret_cast<char*>(geomBuffer.contiguous().data_ptr()), |
| reinterpret_cast<char*>(binningBuffer.contiguous().data_ptr()), |
| reinterpret_cast<char*>(imageBuffer.contiguous().data_ptr()), |
| dL_dout_color.contiguous().data<float>(), |
| dL_dmeans2D.contiguous().data<float>(), |
| dL_dconic.contiguous().data<float>(), |
| dL_dopacity.contiguous().data<float>(), |
| dL_dcolors.contiguous().data<float>(), |
| dL_dmeans3D.contiguous().data<float>(), |
| dL_dcov3D.contiguous().data<float>(), |
| dL_dsh.contiguous().data<float>(), |
| dL_dscales.contiguous().data<float>(), |
| dL_drotations.contiguous().data<float>(), |
| debug); |
| } |
| |
| return std::make_tuple(dL_dmeans2D, dL_dcolors, dL_dopacity, dL_dmeans3D, dL_dcov3D, dL_dsh, dL_dscales, dL_drotations); |
| } |
| |
| |
| void CudaRasterizer::Rasterizer::backward( |
| const int P, int D, int M, int R, |
| const float* background, |
| const int width, int height, |
| const float* means3D, |
| const float* shs, |
| const float* colors_precomp, |
| const float* scales, |
| const float scale_modifier, |
| const float* rotations, |
| const float* cov3D_precomp, |
| const float* viewmatrix, |
| const float* projmatrix, |
| const float* campos, |
| const float tan_fovx, float tan_fovy, |
| const int* radii, |
| char* geom_buffer, |
| char* binning_buffer, |
| char* img_buffer, |
| const float* dL_dpix, |
| float* dL_dmean2D, |
| float* dL_dconic, |
| float* dL_dopacity, |
| float* dL_dcolor, |
| float* dL_dmean3D, |
| float* dL_dcov3D, |
| float* dL_dsh, |
| float* dL_dscale, |
| float* dL_drot, |
| bool debug) |
| { |
| GeometryState geomState = GeometryState::fromChunk(geom_buffer, P); |
| BinningState binningState = BinningState::fromChunk(binning_buffer, R); |
| ImageState imgState = ImageState::fromChunk(img_buffer, width * height); |
| |
| if (radii == nullptr) |
| { |
| radii = geomState.internal_radii; |
| } |
| |
| const float focal_y = height / (2.0f * tan_fovy); |
| const float focal_x = width / (2.0f * tan_fovx); |
| |
| const dim3 tile_grid((width + BLOCK_X - 1) / BLOCK_X, (height + BLOCK_Y - 1) / BLOCK_Y, 1); |
| const dim3 block(BLOCK_X, BLOCK_Y, 1); |
| |
| |
| |
| const float* color_ptr = (colors_precomp != nullptr) ? colors_precomp : geomState.rgb; |
| CHECK_CUDA(BACKWARD::render( |
| tile_grid, |
| block, |
| imgState.ranges, |
| binningState.point_list, |
| width, height, |
| background, |
| geomState.means2D, |
| geomState.conic_opacity, |
| color_ptr, |
| imgState.accum_alpha, |
| imgState.n_contrib, |
| dL_dpix, |
| (float3*)dL_dmean2D, |
| (float4*)dL_dconic, |
| dL_dopacity, |
| dL_dcolor), debug) |
| |
| |
| const float* cov3D_ptr = (cov3D_precomp != nullptr) ? cov3D_precomp : geomState.cov3D; |
| CHECK_CUDA(BACKWARD::preprocess(P, D, M, |
| (float3*)means3D, |
| radii, |
| shs, |
| geomState.clamped, |
| (glm::vec3*)scales, |
| (glm::vec4*)rotations, |
| scale_modifier, |
| cov3D_ptr, |
| viewmatrix, |
| projmatrix, |
| focal_x, focal_y, |
| tan_fovx, tan_fovy, |
| (glm::vec3*)campos, |
| (float3*)dL_dmean2D, |
| dL_dconic, |
| (glm::vec3*)dL_dmean3D, |
| dL_dcolor, |
| dL_dcov3D, |
| dL_dsh, |
| (glm::vec3*)dL_dscale, |
| (glm::vec4*)dL_drot), debug) |
| } |
cuda反传渲染代码
| void BACKWARD::render( |
| const dim3 grid, const dim3 block, |
| const uint2* ranges, |
| const uint32_t* point_list, |
| int W, int H, |
| const float* bg_color, |
| const float2* means2D, |
| const float4* conic_opacity, |
| const float* colors, |
| const float* final_Ts, |
| const uint32_t* n_contrib, |
| const float* dL_dpixels, |
| float3* dL_dmean2D, |
| float4* dL_dconic2D, |
| float* dL_dopacity, |
| float* dL_dcolors) |
| { |
| |
| renderCUDA << > >( |
| ranges, |
| point_list, |
| W, H, |
| bg_color, |
| means2D, |
| conic_opacity, |
| colors, |
| final_Ts, |
| n_contrib, |
| dL_dpixels, |
| dL_dmean2D, |
| dL_dconic2D, |
| dL_dopacity, |
| dL_dcolors |
| ); |
| } |
| |
| |
| template |
| __global__ void __launch_bounds__(BLOCK_X * BLOCK_Y) |
| renderCUDA( |
| const uint2* __restrict__ ranges, |
| const uint32_t* __restrict__ point_list, |
| int W, int H, |
| const float* __restrict__ bg_color, |
| const float2* __restrict__ points_xy_image, |
| const float4* __restrict__ conic_opacity, |
| const float* __restrict__ colors, |
| const float* __restrict__ final_Ts, |
| const uint32_t* __restrict__ n_contrib, |
| const float* __restrict__ dL_dpixels, |
| float3* __restrict__ dL_dmean2D, |
| float4* __restrict__ dL_dconic2D, |
| float* __restrict__ dL_dopacity, |
| float* __restrict__ dL_dcolors) |
| { |
| |
| auto block = cg::this_thread_block(); |
| const uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X; |
| const uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y }; |
| const uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) }; |
| const uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y }; |
| const uint32_t pix_id = W * pix.y + pix.x; |
| const float2 pixf = { (float)pix.x, (float)pix.y }; |
| |
| const bool inside = pix.x < W&& pix.y < H; |
| |
| const uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x]; |
| const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE); |
| |
| bool done = !inside; |
| int toDo = range.y - range.x; |
| |
| __shared__ int collected_id[BLOCK_SIZE]; |
| __shared__ float2 collected_xy[BLOCK_SIZE]; |
| __shared__ float4 collected_conic_opacity[BLOCK_SIZE]; |
| __shared__ float collected_colors[C * BLOCK_SIZE]; |
| |
| |
| const float T_final = inside ? final_Ts[pix_id] : 0; |
| float T = T_final; |
| |
| |
| uint32_t contributor = toDo; |
| const int last_contributor = inside ? n_contrib[pix_id] : 0; |
| |
| float accum_rec[C] = { 0 }; |
| float dL_dpixel[C]; |
| if (inside) |
| for (int i = 0; i < C; i++) |
| dL_dpixel[i] = dL_dpixels[i * H * W + pix_id]; |
| |
| float last_alpha = 0; |
| float last_color[C] = { 0 }; |
| |
| |
| const float ddelx_dx = 0.5 * W; |
| const float ddely_dy = 0.5 * H; |
| |
| |
| for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE) |
| { |
| |
| |
| block.sync(); |
| const int progress = i * BLOCK_SIZE + block.thread_rank(); |
| if (range.x + progress < range.y) |
| { |
| const int coll_id = point_list[range.y - progress - 1]; |
| collected_id[block.thread_rank()] = coll_id; |
| collected_xy[block.thread_rank()] = points_xy_image[coll_id]; |
| collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id]; |
| for (int i = 0; i < C; i++) |
| collected_colors[i * BLOCK_SIZE + block.thread_rank()] = colors[coll_id * C + i]; |
| } |
| block.sync(); |
| |
| |
| for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++) |
| { |
| |
| contributor--; |
| if (contributor >= last_contributor) |
| continue; |
| |
| |
| const float2 xy = collected_xy[j]; |
| const float2 d = { xy.x - pixf.x, xy.y - pixf.y }; |
| const float4 con_o = collected_conic_opacity[j]; |
| const float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y; |
| if (power > 0.0f) |
| continue; |
| |
| const float G = exp(power); |
| const float alpha = min(0.99f, con_o.w * G); |
| if (alpha < 1.0f / 255.0f) |
| continue; |
| |
| T = T / (1.f - alpha); |
| const float dchannel_dcolor = alpha * T; |
| |
| |
| |
| float dL_dalpha = 0.0f; |
| const int global_id = collected_id[j]; |
| for (int ch = 0; ch < C; ch++) |
| { |
| const float c = collected_colors[ch * BLOCK_SIZE + j]; |
| |
| accum_rec[ch] = last_alpha * last_color[ch] + (1.f - last_alpha) * accum_rec[ch]; |
| last_color[ch] = c; |
| |
| const float dL_dchannel = dL_dpixel[ch]; |
| dL_dalpha += (c - accum_rec[ch]) * dL_dchannel; |
| |
| |
| |
| atomicAdd(&(dL_dcolors[global_id * C + ch]), dchannel_dcolor * dL_dchannel); |
| } |
| dL_dalpha *= T; |
| |
| last_alpha = alpha; |
| |
| |
| |
| float bg_dot_dpixel = 0; |
| for (int i = 0; i < C; i++) |
| bg_dot_dpixel += bg_color[i] * dL_dpixel[i]; |
| dL_dalpha += (-T_final / (1.f - alpha)) * bg_dot_dpixel; |
| |
| |
| const float dL_dG = con_o.w * dL_dalpha; |
| const float gdx = G * d.x; |
| const float gdy = G * d.y; |
| const float dG_ddelx = -gdx * con_o.x - gdy * con_o.y; |
| const float dG_ddely = -gdy * con_o.z - gdx * con_o.y; |
| |
| |
| atomicAdd(&dL_dmean2D[global_id].x, dL_dG * dG_ddelx * ddelx_dx); |
| atomicAdd(&dL_dmean2D[global_id].y, dL_dG * dG_ddely * ddely_dy); |
| |
| |
| atomicAdd(&dL_dconic2D[global_id].x, -0.5f * gdx * d.x * dL_dG); |
| atomicAdd(&dL_dconic2D[global_id].y, -0.5f * gdx * d.y * dL_dG); |
| atomicAdd(&dL_dconic2D[global_id].w, -0.5f * gdy * d.y * dL_dG); |
| |
| |
| atomicAdd(&(dL_dopacity[global_id]), G * dL_dalpha); |
| } |
| } |
| } |
cuda反传预处理代码
| void BACKWARD::preprocess( |
| int P, int D, int M, |
| const float3* means3D, |
| const int* radii, |
| const float* shs, |
| const bool* clamped, |
| const glm::vec3* scales, |
| const glm::vec4* rotations, |
| const float scale_modifier, |
| const float* cov3Ds, |
| const float* viewmatrix, |
| const float* projmatrix, |
| const float focal_x, float focal_y, |
| const float tan_fovx, float tan_fovy, |
| const glm::vec3* campos, |
| const float3* dL_dmean2D, |
| const float* dL_dconic, |
| glm::vec3* dL_dmean3D, |
| float* dL_dcolor, |
| float* dL_dcov3D, |
| float* dL_dsh, |
| glm::vec3* dL_dscale, |
| glm::vec4* dL_drot) |
| { |
| |
| |
| |
| computeCov2DCUDA << <(P + 255) / 256, 256 >> > ( |
| P, |
| means3D, |
| radii, |
| cov3Ds, |
| focal_x, |
| focal_y, |
| tan_fovx, |
| tan_fovy, |
| viewmatrix, |
| dL_dconic, |
| (float3*)dL_dmean3D, |
| dL_dcov3D); |
| |
| |
| |
| preprocessCUDA << < (P + 255) / 256, 256 >> > ( |
| P, D, M, |
| (float3*)means3D, |
| radii, |
| shs, |
| clamped, |
| (glm::vec3*)scales, |
| (glm::vec4*)rotations, |
| scale_modifier, |
| projmatrix, |
| campos, |
| (float3*)dL_dmean2D, |
| (glm::vec3*)dL_dmean3D, |
| dL_dcolor, |
| dL_dcov3D, |
| dL_dsh, |
| dL_dscale, |
| dL_drot); |
| } |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧