风格迁移
一.原理
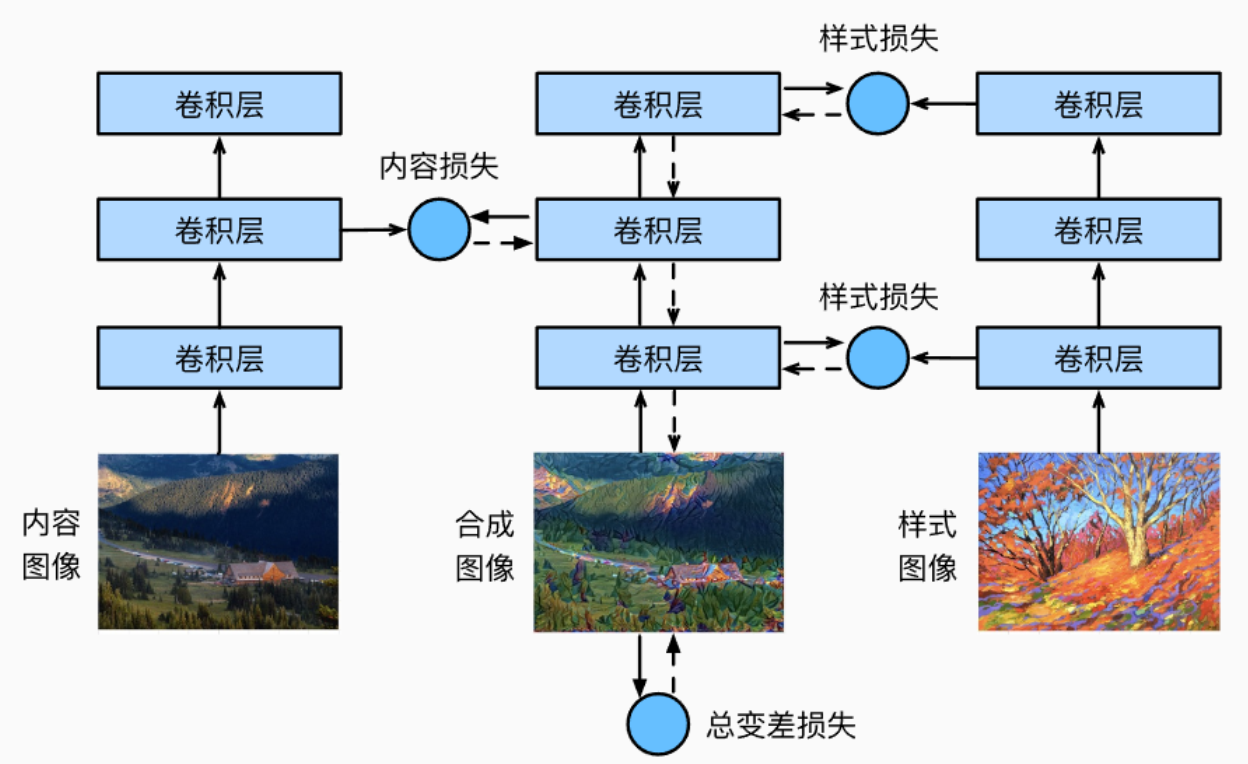
- 这里面画的三个卷积层组们都是一样的,都是用的同样的网络,并且这个网络用的是预训练好的参数,他们的作用是特征提取,在训练过程中参数不会更新。
- 这个网络的参数是那个合成图像。
- 损失包括三部分,合成图像和内容图像的损失,合成图像和样式图像的损失,合成图形自身的全变分去噪损失(total variation denoising)
二.代码实现
- 获取内容图像和风格图像
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
from helptrain import mylib as mb
content_img = d2l.Image.open('../data/rainier.jpg')
mb.plt.imshow(content_img)
style_img = d2l.Image.open('../data/autumn-oak.jpg')
d2l.plt.imshow(style_img)


2. 对内容图像和风格图像做预处理使得可以作为特征提取网络的输入并且定义一个逆操作使得合成图像可以变回原格式输出
# 预处理和后处理
rgb_mean = torch.tensor([0.485,0.456,0.406])
rgb_std = torch.tensor([0.229,0.224,0.225])
def preprocess(img, image_shape): # 图片变为训练的tensor
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(image_shape),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=rgb_mean,std=rgb_std) ])
return transforms(img).unsqueeze(0)
def postprocess(img): # tensor变为图片
img = img[0].to(rgb_std.device)
img = torch.clamp(img.permute(1,2,0) * rgb_std + rgb_mean, 0, 1)
return torchvision.transforms.ToPILImage()(img.permute(2,0,1))
- 定义提取特征的网络和获取特征、风格的函数
抽取图像特征
pretrained_net = torchvision.models.vgg19(pretrained=True)
# 这些数字代表取vgg19的某些卷积输出层的索引
style_layers, content_layers = [0, 5, 10, 19, 28], [25] # 越小越靠近输入,越靠近输入越匹配局部的信息
net = nn.Sequential(*[pretrained_net.features[i]
for i in range(max(content_layers + style_layers) + 1)])
def extract_features(X, content_layers, style_layers):
contents = []
styles = []
for i in range(len(net)):
X = net[i](X) # 每一层抽特征
if i in style_layers: # 如果该层为样式层,则返回样式
styles.append(X)
if i in content_layers: # 如果该层为内容层,则返回内容
contents.append(X)
return contents, styles
#获取内容特征
def get_contents(image_shape, device):
content_X = preprocess(content_img, image_shape).to(device)
content_Y, _ = extract_features(content_X, content_layers, style_layers)
return content_X, content_Y
#获取风格特征
def get_styles(image_shape, device):
style_X = preprocess(style_img, image_shape).to(device)
_, styles_Y = extract_features(style_X, content_layers, style_layers)
return style_X, styles_Y
- 获取真正的风格特征

def gram(X):
num_channels, n = X.shape[1], X.numel() // X.shape[1]
X = X.reshape((num_channels, n))
return torch.matmul(X, X.T) / (num_channels * n)
其实就是对特征图不同的通道之间做了求相关的操作。
5. 定义损失函数
#定义损失函数
def content_loss(Y_hat, Y): # 内容损失相差
return torch.square(Y_hat - Y.detach()).mean()
def style_loss(Y_hat, gram_Y): # 样式损失相差
return torch.square(gram(Y_hat) - gram_Y.detach()).mean()
def tv_loss(Y_hat): # 全变分损失
return 0.5 * (torch.abs(Y_hat[:,:,1:,:] - Y_hat[:,:,:-1,:]).mean()+
torch.abs(Y_hat[:,:,:,1:] - Y_hat[:,:,:,:-1]).mean())
# 风格转移的损失函数是内容损失、风格损失和总变化损失的加权和
content_weight, style_weight, tv_weight = 1, 1e3, 10
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):# 计算总损失
# X为合成图像
contents_l = [
content_loss(Y_hat, Y) * content_weight
for Y_hat, Y in zip(contents_Y_hat, contents_Y) ]
styles_l = [
style_loss(Y_hat, Y) * style_weight
for Y_hat, Y in zip(styles_Y_hat, styles_Y_gram) ]
tv_l = tv_loss(X) * tv_weight
l = sum(10 * styles_l + contents_l + [tv_l])
return contents_l, styles_l, tv_l, l
- 定义参与训练的网络
class SynthesizedImage(nn.Module):
def __init__(self, img_shape, **kwargs):
super(SynthesizedImage, self).__init__(**kwargs)
self.weight = nn.Parameter(torch.rand(*img_shape))
def forward(self):
return self.weight
- 训练
def get_inits(X, device, lr, styles_Y):
gen_img = SynthesizedImage(X.shape).to(device)
gen_img.weight.data.copy_(X.data)
trainer = torch.optim.Adam(gen_img.parameters(),lr=lr)
styles_Y_gram = [gram(Y) for Y in styles_Y]
return gen_img(), styles_Y_gram, trainer
# 训练模型
def train(X, contents_Y, styles_Y, device, lr, num_epochs, lr_decay_epoch):
X, styles_Y_gram, trainer = get_inits(X, device, lr, styles_Y)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_decay_epoch, 0.8)
animator = d2l.Animator(xlabel='epoch',ylabel='loss',xlim=[10,num_epochs],
legend=['content','style','TV'],ncols=2,figsize=(7, 2.5))
for epoch in range(num_epochs):
trainer.zero_grad()
contents_Y_hat, styles_Y_hat = extract_features(X, content_layers, style_layers)
contents_l, styles_l, tv_l, l = compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram)
l.backward()
trainer.step()
scheduler.step()
if(epoch+1) % 10 == 0:
animator.axes[1].imshow(postprocess(X))
animator.add(epoch + 1,
[float(sum(contents_l)),
float(sum(styles_l)),
float(tv_l)])
return X
device, image_shape = d2l.try_gpu(), (500, 500)
net = net.to(device)
content_X, contents_Y = get_contents(image_shape, device)
_, styles_Y = get_styles(image_shape, device)
output = train(content_X, contents_Y, styles_Y, device, 0.3, 500, 50)
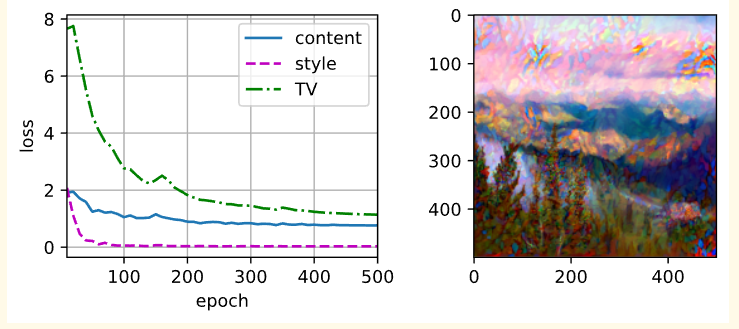
- 结果
本文来自博客园,作者:SXQ-BLOG,转载请注明原文链接:https://www.cnblogs.com/sxq-blog/p/16694120.html

