转置卷积
一. 基本操作
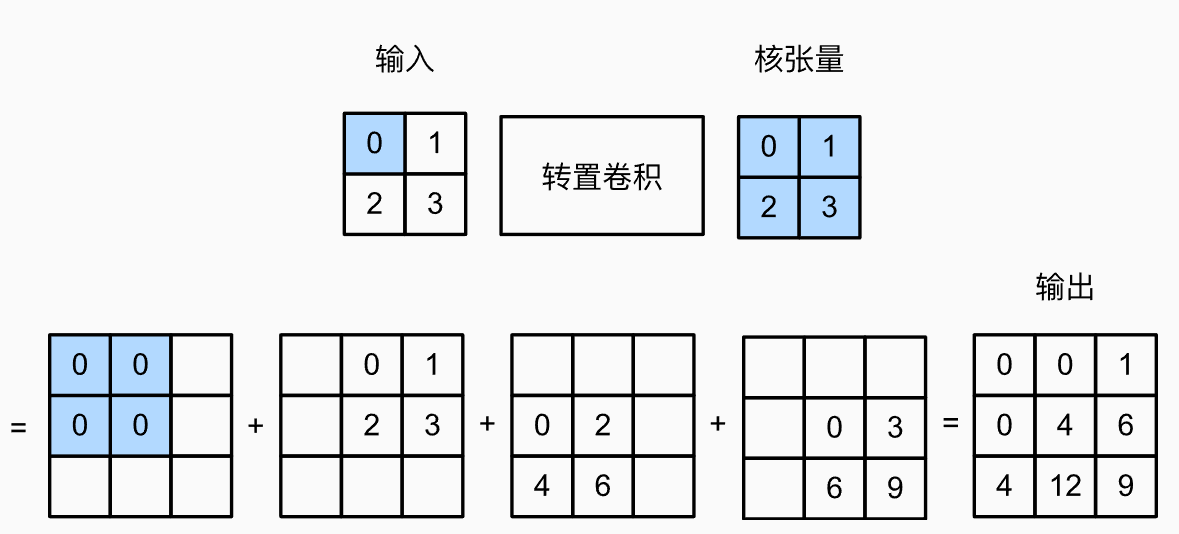
不同于一般的卷积做的是多个元素->1个元素,转置卷积是从1个元素到多个元素
二. 填充、步幅和多通道
1. 填充
- 常规卷积中padding是在输入的外圈添加元素,转置卷积中的padding则是在输出中删除外圈的元素
x = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) x = x.reshape(1, 1, 2, 2) k = torch.tensor([[4.0, 7.0], [2.0, 2.0]]) k = k.reshape(1, 1, 2, 2) tconv1 = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=0, bias=False) tconv1.weight.data = k print(tconv1(x)) tconv2 = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False) tconv2.weight.data = k print(tconv2(x))
Output:
tensor([[[[ 0., 4., 7.], [ 8., 28., 23.], [ 4., 10., 6.]]]], grad_fn=<ConvolutionBackward0>) tensor([[[[28.]]]], grad_fn=<ConvolutionBackward0>)
2. 步幅
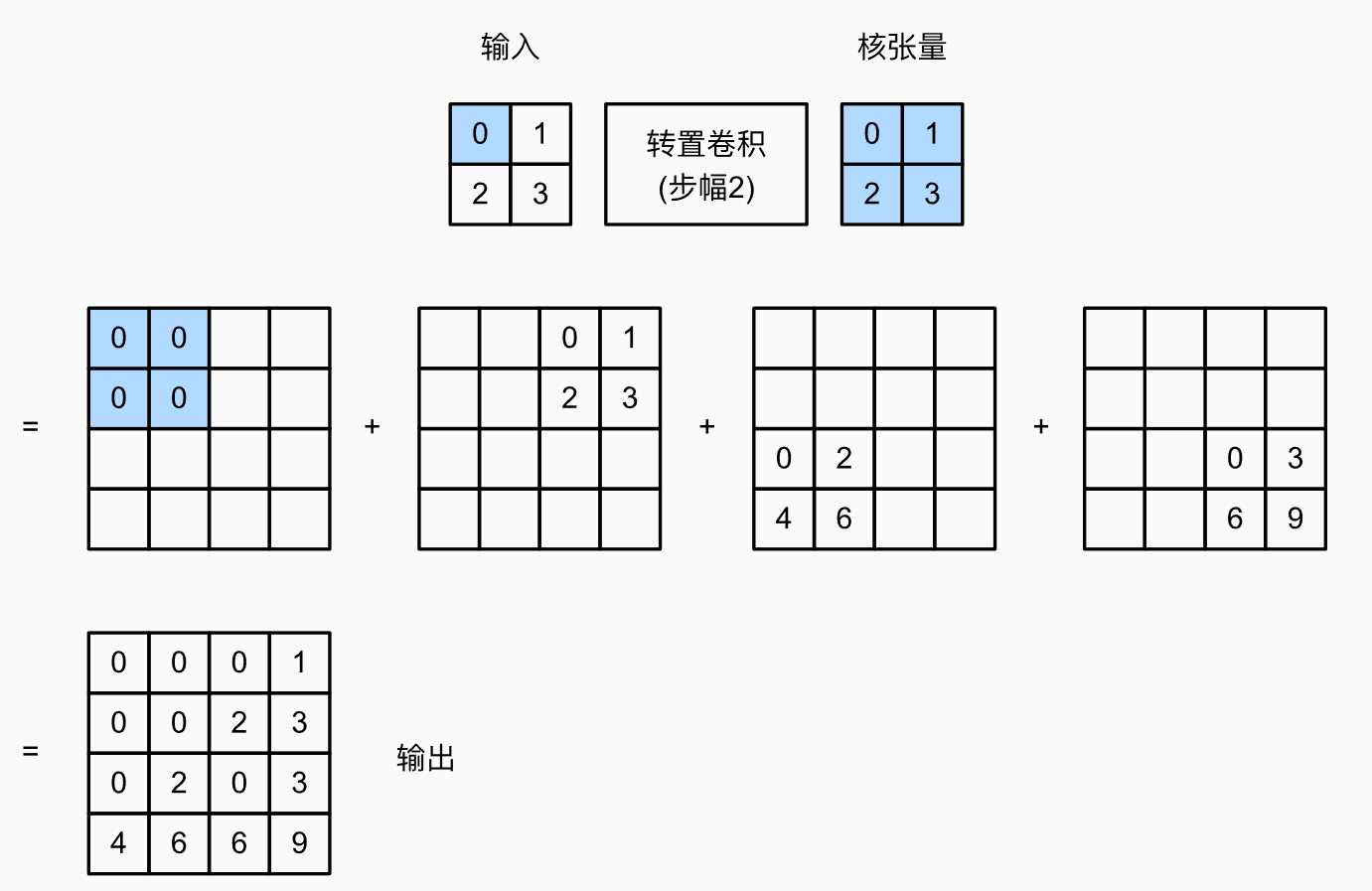
- 步幅这里指的是每一个像素扩展出的的输出的摆放方式。
x = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) x = x.reshape(1, 1, 2, 2) k = torch.tensor([[4.0, 7.0], [2.0, 2.0]]) k = k.reshape(1, 1, 2, 2) tconv1 = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=4, bias=False) tconv1.weight.data = k print(tconv1(X))
Output:
tensor([[[[ 0., 0., 0., 0., 4., 7.], [ 0., 0., 0., 0., 2., 2.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 8., 14., 0., 0., 12., 21.], [ 4., 4., 0., 0., 6., 6.]]]], grad_fn=<ConvolutionBackward0>)
3. 多通道
nn.ConvTranspose2d(2, 1, kernel_size=2, bias=False)指的是用1个的卷积核做转置卷积。
x = torch.tensor([[[0, 1.0], [2.0, 3.0]], [[4, 5], [7, 8]]]) x = x.reshape(1, 2, 2, 2) k = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[4, 5], [2, 3]]]) k = k.reshape(2, 1, 2, 2) tconv3 = nn.ConvTranspose2d(2, 1, kernel_size=2, bias=False) tconv3.weight.data = k print(x) print(k) print(tconv3(x)) print(tconv3(x).shape)
Output:
tensor([[[[0., 1.], [2., 3.]], [[4., 5.], [7., 8.]]]]) tensor([[[[0., 1.], [2., 3.]]], [[[4., 5.], [2., 3.]]]]) tensor([[[[16., 40., 26.], [36., 93., 61.], [18., 49., 33.]]]], grad_fn=<ConvolutionBackward0>) torch.Size([1, 1, 3, 3])
- 下面分析下为啥是这个结果
原图中第一个像素的扩展方式为:
其他像素点的展开方式也是同样的。
转置卷积同样遵循用几个卷积核输出几个通道的原则。
三. 转置卷积与普通卷积的形状互逆操作
只需要把Conv和ConvTranspose的kernel,padding,stride参数指定成一样的即可。
X = torch.rand(size=(1, 10, 16, 16)) conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3) tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3) tconv(conv(X)).shape == X.shape
Output:
True
四. 为什么叫做转置卷积
普通卷积的实现其实是通过矩阵乘法来实现的

上图中的 已经变成卷积后的图像尺寸了,那么想要从 变回原图的尺寸需要通过转置卷积来实现,只需要 便可以得到形如 的矩阵,其中 为形状和 一样的矩阵。至于 中的每一个元素就和ConvTranspose2d中的参数有关了。
注意
- 转置卷积也是卷积,也是和普通卷积一样左乘一个矩阵实现的
- 转置卷积只是可以把尺寸做互逆的操作,并不是做的数值的互逆
五. 转置卷积的用途
- 上采样
在应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(e.g.:图像的语义分割),这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。 - 实现上采样常见方法
上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling),其中反池化目前用的比较少。
本文来自博客园,作者:SXQ-BLOG,转载请注明原文链接:https://www.cnblogs.com/sxq-blog/p/16689306.html
分类:
DeepLearning


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· Apache Tomcat RCE漏洞复现(CVE-2025-24813)