

Python RabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
python安装RabbitMQ模块
pip install pika
最简单的队列通信
发送端:
#!/usr/bin/env python # -*- coding: UTF-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.231'))
channel = connection.channel()#声明一个管道(管道内发消息)channel.queue_declare(queue='sxl')#声明queue队列channel.basic_publish(exchange='',
routing_key='sxl',#routing_key 就是queue名
body='Hello World!'
) print(" [x] Sent 'Hello World!'") connection.close()
接收端:
#!/usr/bin/env python # -*- coding: UTF-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.231'))
channel = connection.channel() channel.queue_declare(queue='sxl') def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume(callback,#如果收到消息,就调用callback函数处理消息
queue='sxl',
no_ack=False
) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()#开始收消息
消息持久化
如果消息在传输过程中rabbitMQ服务器宕机了,会发现之前的消息队列就不存在了,这时我们就要用到消息持久化,消息持久化会让队列不随着服务器宕机而消失,会永久的保存下去
发送端:
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.231')) channel = connection.channel() #声明一个管道(管道内发消息) channel.queue_declare(queue='sxl',durable=True) #队列持久化 channel.basic_publish(exchange='', routing_key='sxl', #routing_key 就是queue名 body='Hello World!', properties=pika.BasicProperties( delivery_mode = 2 #消息持久化 ) ) print("Sent 'Hello,World!'") connection.close() #关闭
接收端:
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika,time connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.231')) channel = connection.channel() channel.queue_declare(queue='sxl',durable=True) def callback(ch,method,properties,body): print("Received %r"%body)
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue="sxl",
no_ack=False ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
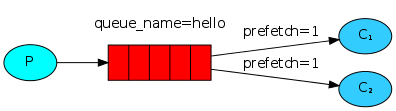
带消息持久化+公平分发


#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #声明一个管道(管道内发消息) channel.queue_declare(queue='lzl',durable=True) #队列持久化 channel.basic_publish(exchange='', routing_key='lzl', #routing_key 就是queue名 body='Hello World!', properties=pika.BasicProperties( delivery_mode = 2 #消息持久化 ) ) print("Sent 'Hello,World!'") connection.close() #关闭 pubulish.py
#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #声明一个管道(管道内发消息) channel.queue_declare(queue='lzl',durable=True) #队列持久化 channel.basic_publish(exchange='', routing_key='lzl', #routing_key 就是queue名 body='Hello World!', properties=pika.BasicProperties( delivery_mode = 2 #消息持久化 ) ) print("Sent 'Hello,World!'") connection.close() #关闭 pubulish.py
Publish\Subscribe(消息发布\订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
An exchange is a very simple thing. On one side it receives messages from producers and the other side it pushes them to queues. The exchange must know exactly what to do with a message it receives. Should it be appended to a particular queue? Should it be appended to many queues? Or should it get discarded. The rules for that are defined by the exchange type.
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
headers: 通过headers 来决定把消息发给哪些queue
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
fanout接收所有广播:
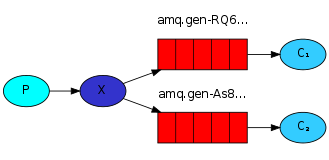
消息publisher
#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') message = "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', #广播不用声明queue body=message) print(" [x] Sent %r" % message) connection.close() publish.py
消息subscriber
#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字, # exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_name = result.method.queue channel.queue_bind(exchange='logs', # 绑定转发器,收转发器上面的数据 queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() consume.py
有选择的接收消息 direct:
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列
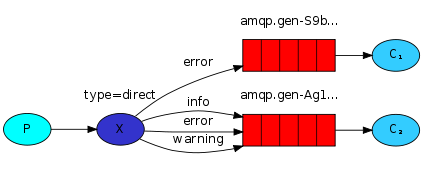
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close() publish.py
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() consume.py
更细致的消息过滤 topic:
Although using the direct exchange improved our system, it still has limitations - it can't do routing based on multiple criteria.
In our logging system we might want to subscribe to not only logs based on severity, but also based on the source which emitted the log. You might know this concept from the syslog unix tool, which routes logs based on both severity (info/warn/crit...) and facility (auth/cron/kern...).
That would give us a lot of flexibility - we may want to listen to just critical errors coming from 'cron' but also all logs from 'kern'

import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close() publish.py
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() consume.py
RPC(Remote procedure call )双向通信
To illustrate how an RPC service could be used we're going to create a simple client class. It's going to expose a method named call which sends an RPC request and blocks until the answer is received:
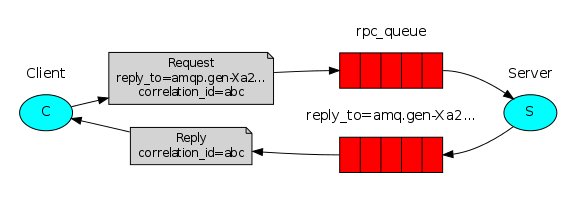
#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika import uuid,time class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, #只要收到消息就执行on_response no_ack=True, #不用ack确认 queue=self.callback_queue) def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: #验证码核对 self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) print(self.corr_id) self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, #发送返回信息的队列name correlation_id=self.corr_id, #发送uuid 相当于验证码 ), body=str(n)) while self.response is None: self.connection.process_data_events() #非阻塞版的start_consuming print("no messages") time.sleep(0.5) #测试 return int(self.response) fibonacci_rpc = FibonacciRpcClient() #实例化 print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(30) #执行call方法 print(" [.] Got %r" % response)
#!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n - 1) + fib(n - 2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to, #回信息队列名 properties=pika.BasicProperties(correlation_id= props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) #channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
