
索引的底层实现(B 树)
一、B 树
1、B-Tree介绍
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
定义
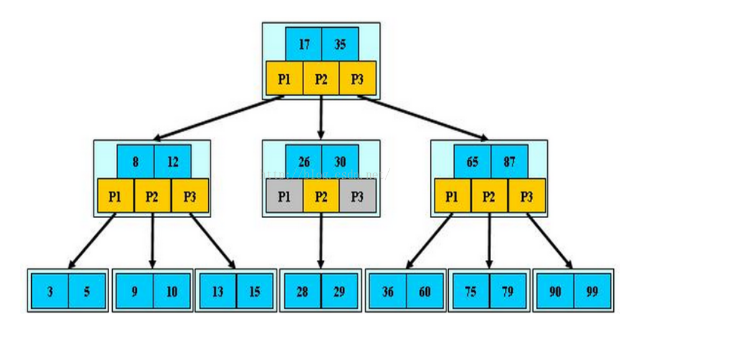
B-Tree是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
特性
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
2、B+Tree介绍
定义
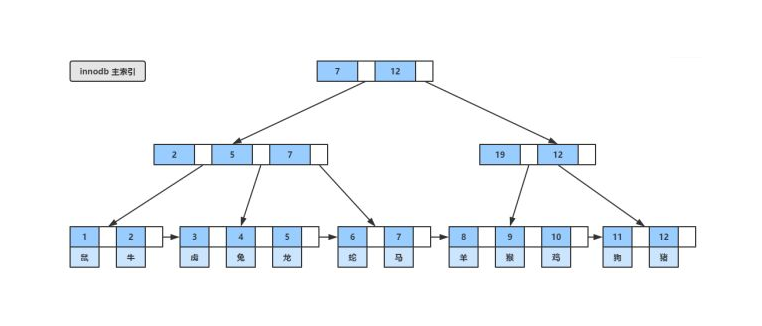
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
特性
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
3、B树与B+树区别
这都是由于B+树和B具有这不同的存储结构所造成的区别,以一个m阶树为例。
关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径
二、索引底层实现
1、MyISAM 索引实现
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录
的地址。
主索引与辅助索引的区别(对某列建立索引):
在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复
主索引(聚集索引)也就是表的主键,是建表时指定的,并且是唯一的
辅助索引(非聚集索引)是对表有其他需要可以添加创建的
下图是 MyISAM 索引的原理图: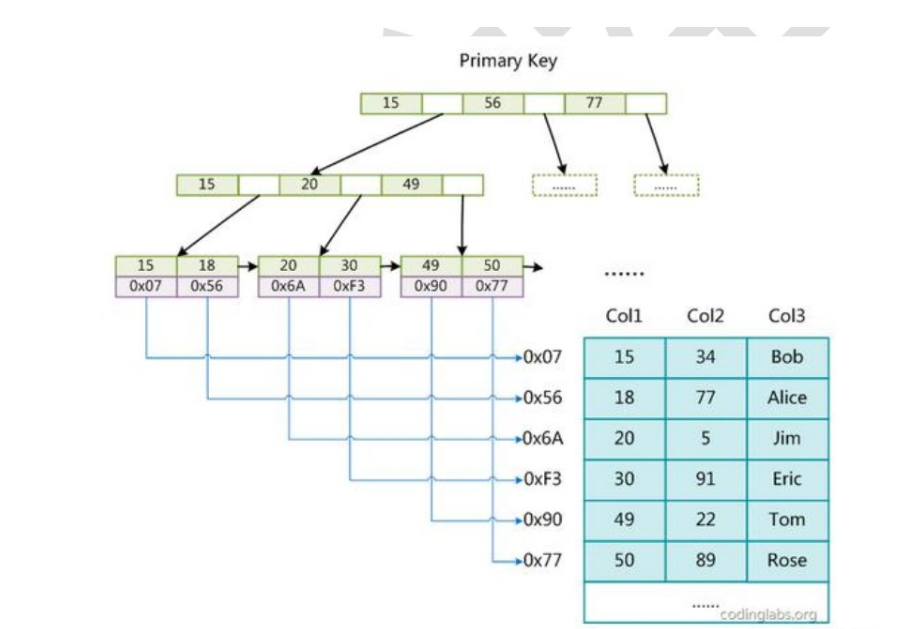
索引过程:
MyISAM 中索引检索的算法为首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值,然后以 data 域的值为地址,读取相应数据记录。
2、 InnoDB索引实现
1、InnoDB 的数据文件本身就是索引文件。从上文知道,MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
而在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形
2、第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
3、主键过长导致:
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。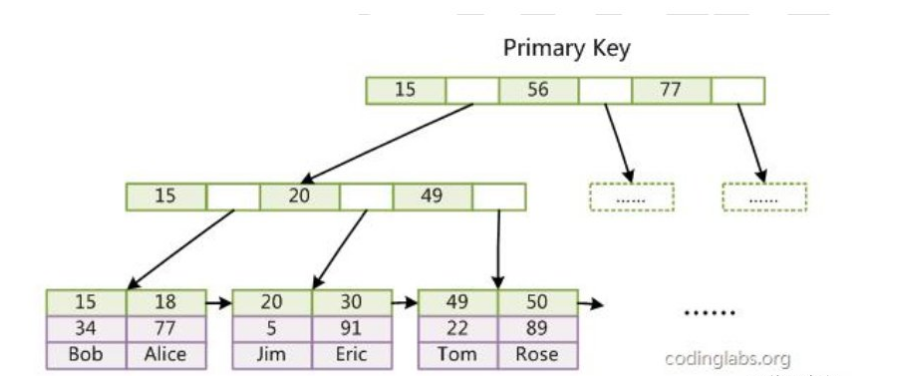

 浙公网安备 33010602011771号
浙公网安备 33010602011771号