


【Spring】三级缓存解决循环依赖问题
参考地址:
Spring循环依赖:https://zhuanlan.zhihu.com/p/700890658
Spring三级缓存解决循环依赖的问题:https://blog.csdn.net/Trong_/article/details/134063622
==================================================================
1.什么是循环依赖?

1>说白是一个或多个对象实例之间存在直接或间接的依赖关系,这种依赖关系构成了构成一个环形调用。 2>循环依赖,发生在属性赋值阶段。 3>循环依赖发生在被显式依赖的情况下,即 ①属性注入依赖 ②构造函数注入依赖 ③Setter方法注入依赖 注意: @DependsOn注解的使用,只是指明Bean的初始化顺序,业务上存在先后装载顺序,但并不是显式的依赖关系,因此@DependsOn注解并不造成循环依赖。
第一种情况:自己依赖自己的直接依赖
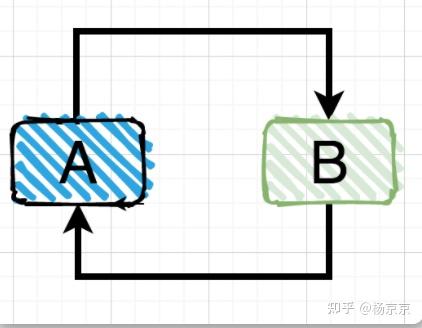
第二种情况:两个对象之间的直接依赖
第三种情况:多个对象之间的间接依赖
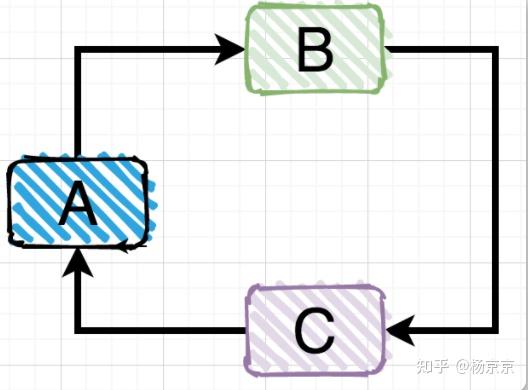
前面两种情况的直接循环依赖比较直观,非常好识别,但是第三种间接循环依赖的情况有时候因为业务代码调用层级很深,不容易识别出来。
2.Spring支持解决哪些循环依赖
2.1 Spring 初始化Bean的底层过程
Spring创建Bean的过程以及Bean的声明周期,详细可见 【面试 Spring】基础普及 https://www.cnblogs.com/sxdcgaq8080/diary/2024/12/17/18612056
我们可知,Spring生命周期分为四个: 实例化 ->属性赋值 ->初始化 ->销毁。
而Spring容器要完成Bean的加载,也基本按照这个步骤进行:
1.Spring容器启动 ->
2.从XML或Configuration加载Bean的定义 ->
3.实例化Bean ->
4.装配Bean的属性 (即依赖注入环节)->
5.对Bean做BeanPostProcess前置动作(AOP before) ->
6.对Bean做 @PostConstruct 、Initialization接口afterPropertiesSet() 、XML的init-method等初始化方法的执行 ->
7.对Bean做BeanPostProcess后置动作 (AOP after)->
8.完成对Bean的最终初始化动作。
......
好,那循环依赖在什么环节发生?
就是发生在依赖注入的环节 即 装配Bean的属性(属性赋值)阶段。
2.2 形成循环依赖的成因
构造函数循环依赖
在使用构造函数注入Bean时,如果两个Bean之间相互依赖,就可能会形成构造函数循环依赖,例如:
@Component
public class A {
private B b;
public A(B b) {
this.b = b;
}}
==============
@Component
public class B {
private A a;
public B(A a) {
this.a = a;
}}
上述代码,A、B的构造函数分别需要创建对方,A依赖B,B依赖A,它们之间形成了一个循环依赖。
当Spring容器启动时,它会尝试先实例化A,但是在实例化A的时候需要先实例化B,而实例化B的时候需要先实例化A,这样就形成了一个循环依赖的死循环,从而导致应用程序无法正常启动。
属性循环依赖
在使用属性注入Bean时,如果两个Bean之间相互依赖,就可能会形成属性循环依赖。例如:
@Component
public class A {
@Autowired
private B b;
}
=============
@Component
public class B {
@Autowired
private A a;
}
类似的,同样Spring在实例化A时会注入B,而注入B时又需要注入A,形成循环依赖
2.3 Spring可以解决那些注入的循环依赖
如上面的过程中,可以确认的是 1>Spring支持解决的循环依赖,只针对单例(Singleton)的Bean。 原型(Prototype 即多例业务域)的Bean出现循环依赖,Spring会直接抛出异常。 2>Spring不支持 A\B初始化顺序上,A依赖B需要构造函数注入才能完成实例化的方式。 而Spring支持 A\B 循环依赖通过Setter/属性 注入的方式。
1>Spring仅支持解决单例的Bean的循环依赖,不支持原型/多例作用域的Bean的循环依赖
①Spring可以通过 三级缓存 设计,解决 单例模式Bean的循环依赖问题 ②Spring无法解决多例/原型(Propotype)作用域Bean的循环依赖问题 原因在于: 多例模式的Bean的创建,是区别于 单例Bean的创建过程。 三级缓存针对单例Bean解决循环依赖,主要这样做: 1>A实例化阶段,将 A_BeanFactory放入三级缓存 2>A属性注入阶段,发现依赖B,此时B未创建,所以去实例化B 3>B实例化阶段,将B_BeanFactory放入三级缓存 4>B属性注入阶段,三级B删除,放入二级B,发现依赖A,从三级缓存 一级\二级\三级依次找下去,发现三级中的A 5>使用A_BeanFactory对B完成属性注入,同时A也从三级中删掉,放入了二级缓存 6>B完成属性注入后,删除二级B,将完成初始化的B放入一级缓存 7>接着A继续进行属性赋值,从 一级\二级\三级依次找B,从一级中找到B,完成属性注入 8>删除二级A,放入一级A,AB至此都完成了初始化。 可以看出,单例的Bean是在 其生命周期 不同阶段,加入三级缓存,才有了可操作的空间。 而多例的Bean,是每次请求容器getBean()都会去创建新的Bean,那这个过程中多例的Bean又依赖了其他多例的Bean,就会导致被依赖的多例的Bean也加入创建过程,这样就形成了 无限递归的 多例创建过程,最终导致栈溢出(StockOverflowError) 或 内存溢出(OutOfMemoryError).
2>Spring支持的单例Bean下循环依赖时的注入方式

从上面一节,我们可以知道,Spring使用三级缓存解决 单例Bean的依赖注入,是利用了Spring管理Bean的生命周期过程,才有了可操作的空间。 1.实例化阶段 只创建Bean 2.属性赋值解决 才解决依赖注入 3.初始化前后 AOP切面增强逻辑 因此,以 A和B循环依赖为例, 先实例化A,在实例化B的先后顺序来讲, 如果AB均采用构造器注入,就无法给三级缓存操作空间,即第一步A实例化就无法成功。 如果A对B采用构造器注入,B对A采用Setter注入,那同理第一步A实例化就无法成功。 因为实例化一个对象,需要通过执行它的构造函数。 而其他依赖注入方式,无论属性注入还是 setter注入 都是可以在 通过实例化阶段后的第二阶段再调用,因此给了三级缓存可操作的空间。
3.Spring解决循环依赖的方案--三级缓存
3.1 三级缓存示意图
// 一级缓存 private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); // 二级缓存 private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); // 三级缓存 private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);

3.2 三级缓存解决Spring中单例Bean的循环依赖问题
三级缓存,从一级、二级、三级依次查找的使用顺序。 1>实例化A,将A_ObjectFactory放入三级缓存,表示A已经开始了实例化。 objectFactory.getObject()内部最终调用getEarlyBeanReference()方法 2>实例化完A,开始对A进行属性赋值阶段(即依赖注入),发现A依赖B 3>从三级缓存依次查找,未找到B 4>实例化B,将B_ObjectFactory放入三级缓存,表示B开始了实例化。 5>实例化完B,开始对B进行属性赋值阶段,发现B依赖A 6>从三级缓存依次查找,在三级缓存找到A 7>将A_ObjectFactory从三级缓存取出,判断A是否被AOP切面代理, 如果A被代理,则objectFactory.getObject()内部最终调用getEarlyBeanReference()方法,返回A的代理对象A_proxy,放入二级缓存 如果A未被代理,则直接返回真实A对象,放入二级缓存 虽然此时A还未完全完成属性赋值和初始化,但真实A 或代理对象A_proxy 已经足以完成对B的依赖注入了 8>B完成属性赋值后,完成初始化动作,放入一级缓存,清理二级、三级缓存中的B 9>从二级缓存拿出A或A_proxy,从三级缓存依次查找B,找到B完成对A的属性赋值,完成A的属性赋值和初始化,A放入一级缓存,二级、三级缓存清理 10>完成单例的A和B循环依赖的初始化。
4. 答疑解惑
4.1 为什么一定要用三级缓存,使用二级缓存是否可以解决循环依赖?
没有AOP需要生成代理对象的复杂场景,二级缓存或许可以解决循环依赖的问题。
因为解决循环依赖的核心,是在Spring容器创建Bean的多阶生命周期中找可操作空间。
而在Spring 生命周期下, 在初始化前夕才知道有没有一个或多个BeanPostProcessor的before切面需要去执行,如果有此时就需要的是代理对象,而不是真实Bean对象。
如果仅用二级缓存,
一开始实例化阶段放入二级缓存的是真实的Bean,此时取出真实Bean不是代理Bean就无法执行AOP切面,就会出错;
那如果一开始实例化阶段放入的是代理的Bean,那就与Spring生命周期管理产生了冲突。
所以说,在Spring管理Bean的生命周期下,单例Bean还是需要三级缓存结构来实现。
4.2 为什么要把A从三级缓存拿出后放入二级缓存,还要把三级缓存中的A_BeanFactory清除掉?
第三级缓存存在 是考虑 AOP代理
第二级缓存存在 是考虑 性能
还是A和B,循环依赖的场景。
B从三级缓存找到A_ObjectFactory的时候,A就要判断是否后续需要AOP代理
如果需要,就通过A_ObjectFactory.getBean(),生成代理对象A_proxy,放入二级缓存;
如果不需要,则通过A_ObjectFactory.getBean(),得到真是对象A_Bean,放入二级缓存;
并且都会将三级缓存中A_ObjectFactory清除。
清除掉的原因,就是既然首次扫描到A时,已经确定了A将是什么形态了,就不需要之后再扫描到A时,仍然还从三级缓存获取A_ObjectFactory,去getBean()了,要知道反射的性能那是比较差的。
故而,在首次之后,就把A从三级缓存提升到二级,就是出于性能考虑。
4.3 Spring中出现循环依赖怎么解决
如果项目启动,仍发现爆出 循环依赖的异常。 说明就不是Spring三层缓存架构可以解决 的 单例Bean 允许的注入方式的依赖情况了。 就需要具体分析: 1>如果是多例Bean产生的 循环依赖,可以尝试修改作用域为 单例Singleton 2>如果是构造函数注入的循环依赖,可以尝试修改为 Setter注入 或者 属性注入。 3>最终 可以使用@Lazy注解 解决上面的两种情况等特殊的循环依赖,使项目成功启动 它的原理,是使用@Lazy引入了一个第三方的 代理Bean,打破了循环依赖,形成了延迟加载的效果。 那真正去加载 依赖Bean的时候,是在A中,通过B的代理对象去调用B的方法的时候,此时才会真正去加载B。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2017-12-27 【jar】JDK将单个的java文件打包为jar包,并引用到项目中使用【MD5加密】