

【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode
1.拉取镜像
docker pull elasticsearch:6.5.4
docker pull kibana:6.5.4
2.启动容器
docker run -d --name es1 -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" elasticsearch:6.5.4
docker run -d -p 5601:5601 --name kibana --restart=always --link es1:elasticsearch kibana:6.5.4
如果启动ES仅是测试使用,启用单节点即可。
如果启动ES是要给生产任务使用,需要启动ES集群。ES 6.5.4启动集群文章
3.访问地址
http://192.168.92.130:5601/status

4.安装ik分词器
进入es容器
sudo docker exec -it es1 /bin/bash
进入plugins目录
cd plugins/
此时查看插件目录下,有两个插件的目录

下载对应es版本的ik的压缩包【安装插件的版本需要与es版本一致】
wget http://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
创建ik目录,用于存放解压ik压缩包的文件
mkdir elasticsearch-analysis-ik

解压ik压缩包到指定目录
unzip elasticsearch-analysis-ik-6.5.4.zip -d elasticsearch-analysis-ik
删除源压缩包
rm -f elasticsearch-analysis-ik-6.5.4.zip
exit 退出容器 重启es容器 查看启动日志加载插件信息
exit
docker restart es1
docker logs -f es1

验证ik分词器是否安装成功【analyzer参数值:ik_max_word 如果未安装成功,请求就会报错!】
两种粗细粒度分别为:
ik_max_word
ik_smart
POST http://192.168.92.130:9200/_analyze
请求体:
{ "analyzer":"ik_max_word", "text":"德玛西亚之力在北韩打倒了变形金刚" }
结果:


{ "tokens": [ { "token": "德", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "玛", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR", "position": 1 }, { "token": "西亚", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 }, { "token": "之力", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 3 }, { "token": "在", "start_offset": 6, "end_offset": 7, "type": "CN_CHAR", "position": 4 }, { "token": "北韩", "start_offset": 7, "end_offset": 9, "type": "CN_WORD", "position": 5 }, { "token": "打倒", "start_offset": 9, "end_offset": 11, "type": "CN_WORD", "position": 6 }, { "token": "倒了", "start_offset": 10, "end_offset": 12, "type": "CN_WORD", "position": 7 }, { "token": "变形金刚", "start_offset": 12, "end_offset": 16, "type": "CN_WORD", "position": 8 }, { "token": "变形", "start_offset": 12, "end_offset": 14, "type": "CN_WORD", "position": 9 }, { "token": "金刚", "start_offset": 14, "end_offset": 16, "type": "CN_WORD", "position": 10 } ] }
ik分词器成功安装
附加一个:
查看某个index下某个type中的某条document的某个属性的属性值 分词效果:
格式如下:
你的index/你的type/document的id/_termvectors?fields=${字段名}
http://192.168.92.130:9200/swapping/builder/6/_termvectors?fields=buildName
【注意fields参数对应的是数组】
5.安装pinyin分词器
进入容器
sudo docker exec -it es1 /bin/bash
进入插件目录
cd plugins/
创建目录elasticsearch-analysis-pinyin
mkdir elasticsearch-analysis-pinyin

进入目录elasticsearch-analysis-pinyin,下载pinyin分词器压缩包【注意版本和es版本一致】
cd elasticsearch-analysis-pinyin/
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v6.5.4/elasticsearch-analysis-pinyin-6.5.4.zip
解压压缩包,解压完成删除压缩包
unzip elasticsearch-analysis-pinyin-6.5.4.zip
rm -f elasticsearch-analysis-pinyin-6.5.4.zip

退出容器,重启es,查看日志
exit
docker restart es1
docker logs -f es1

验证pinyin分词器是否安装成功

结果:
{ "tokens": [ { "token": "de", "start_offset": 0, "end_offset": 0, "type": "word", "position": 0 }, { "token": "dmxyzlzbhddlbxjg", "start_offset": 0, "end_offset": 0, "type": "word", "position": 0 }, { "token": "ma", "start_offset": 0, "end_offset": 0, "type": "word", "position": 1 }, { "token": "xi", "start_offset": 0, "end_offset": 0, "type": "word", "position": 2 }, { "token": "ya", "start_offset": 0, "end_offset": 0, "type": "word", "position": 3 }, { "token": "zhi", "start_offset": 0, "end_offset": 0, "type": "word", "position": 4 }, { "token": "li", "start_offset": 0, "end_offset": 0, "type": "word", "position": 5 }, { "token": "zai", "start_offset": 0, "end_offset": 0, "type": "word", "position": 6 }, { "token": "bei", "start_offset": 0, "end_offset": 0, "type": "word", "position": 7 }, { "token": "han", "start_offset": 0, "end_offset": 0, "type": "word", "position": 8 }, { "token": "da", "start_offset": 0, "end_offset": 0, "type": "word", "position": 9 }, { "token": "dao", "start_offset": 0, "end_offset": 0, "type": "word", "position": 10 }, { "token": "le", "start_offset": 0, "end_offset": 0, "type": "word", "position": 11 }, { "token": "bian", "start_offset": 0, "end_offset": 0, "type": "word", "position": 12 }, { "token": "xing", "start_offset": 0, "end_offset": 0, "type": "word", "position": 13 }, { "token": "jin", "start_offset": 0, "end_offset": 0, "type": "word", "position": 14 }, { "token": "gang", "start_offset": 0, "end_offset": 0, "type": "word", "position": 15 } ] }
证明pinyin插件安装成功
6.繁简体转化分词器
进入es容器
sudo docker exec -it es1 /bin/bash
进入plugins目录
cd plugins/
创建繁简体转化目录
mkdir elasticsearch-analysis-stconvert
进入目录
cd elasticsearch-analysis-stconvert/
下载插件压缩包
wget https://github.com/medcl/elasticsearch-analysis-stconvert/releases/download/v6.5.4/elasticsearch-analysis-stconvert-6.5.4.zip
解压压缩包
unzip elasticsearch-analysis-stconvert-6.5.4.zip
解压完成后,移除原压缩包
rm -f elasticsearch-analysis-stconvert-6.5.4.zip
退出容器
exit
重启es
docker restart es1
查看日志

检验繁简体转化是否安装成功
URL:POST
http://192.168.92.130:9200/_analyze
请求体:
{ "analyzer":"stconvert", "text" : "国际电视台" }
请求结果:
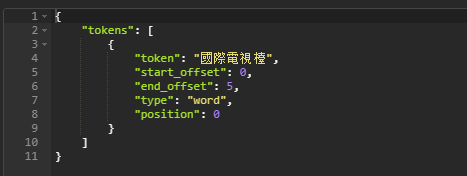
繁简体转化安装成功
7.安装启动logstash
docker拉取logstash
docker pull logstash:6.5.4
启动logstash
docker run -d -p 5044:5044 -p 9600:9600 --restart=always --name logstash logstash:6.5.4
查看日志
docker logs -f logstash
查看日志可以看出,虽然启动成功,但是并未连接上es,

这就需要修改logstash中的对接配置
进入logstash容器内
docker exec -it logstash /bin/bash
进入config目录
cd /usr/share/logstash/config/
修改logstash.yml文件中的es.url
vi logstash.yml
修改url为自己的es所在IP:port

退出容器,重启logstash
exit
docker restart logstash
查看日志可以看到启动成功并且es连接池中刚刚配置的连接地址已经连接成功

回到kibana,查看ELK状态以及运转情况
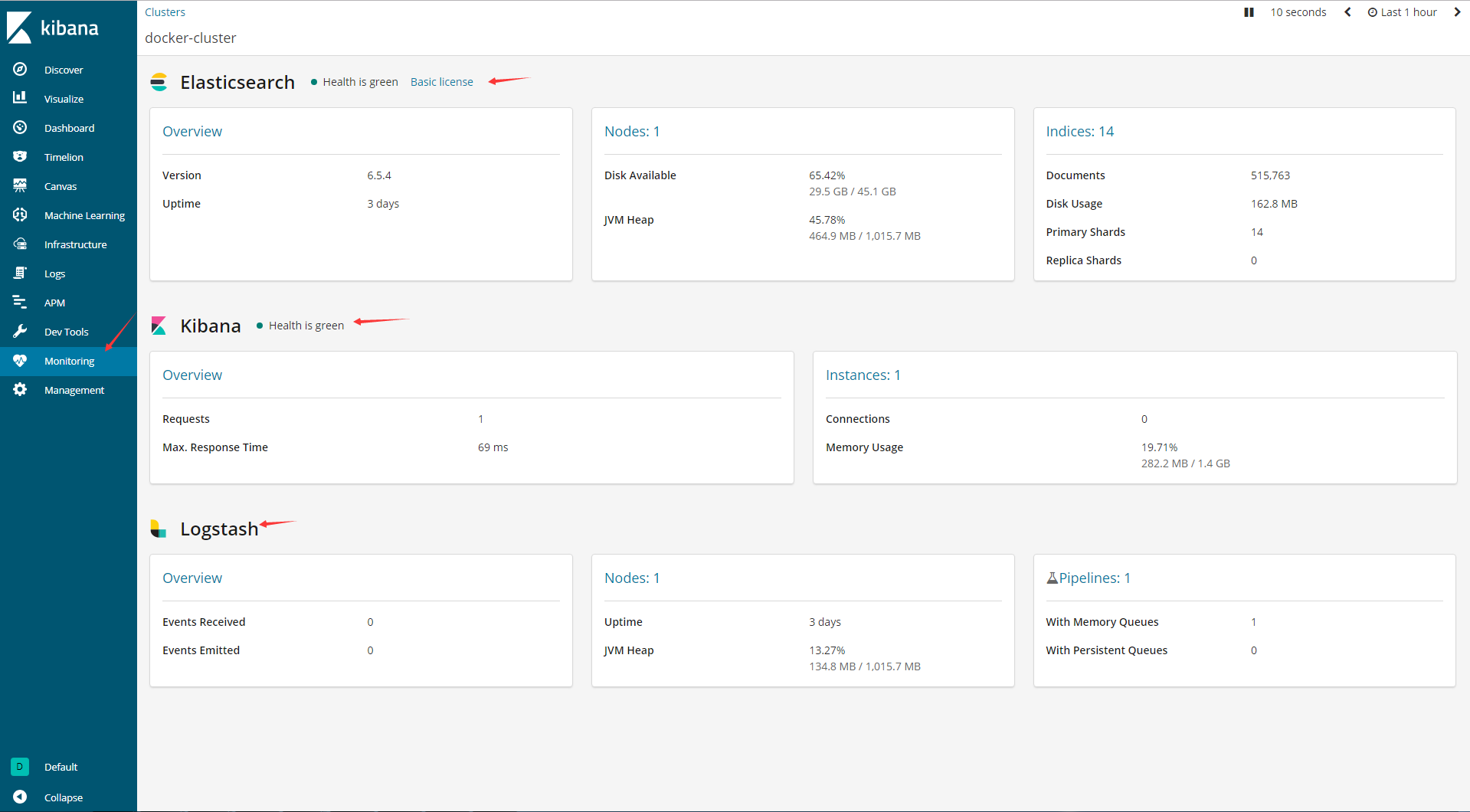
OK,ELK搭建完成!!!
=================================================附录=============================================================================
一、ELK概念描述
看到这里,有很多地方都是迷迷糊糊的吧。
这里简单一说:
ELK是一整套的分布式日志分析平台的解决方案。
在ELK【都是开源软件】中,
E代表 es,用于存储日志信息【就是一个开源可持久化的分布式全文搜索引擎】
L代表logstash,用于收集日志信息【开源数据收集引擎】
K代表kibana,用于展示日志信息【开源的分析和可视化平台】
二、关于logstash插件的知识
这里就要了解一些logstash的知识 logstash插件详解
而对于logstash的收集功能,其实是由它的一个一个插件完成的。而主体的三个插件配置就是input--->filter--->output,如下图所示。

其中input和output是必须的,而filter是非必须的。
input插件配置,是指定数据的输入源,配置标明要收集的数据是从什么地方来的。一个 pipeline是可以指定多个input插件的。
input可以是stdin、file、kafka
filter插件配置,是对原始数据进行类型转化、删除字段、格式化数据的。不是必须的配置。
filter可以是date、grok、dissect、mutate、json、geoip、ruby
output插件配置,是将数据输出到指定位置。
output可以是stdout、file、elasticsearch
====================================================================================================

