
数仓建模之数据仓库分层、事实表与维度表、拉链表、星型模型和雪花模型
一、数据仓库分层
数据仓库更多代表的是一种对数据的管理和使用的方式,它是一整套包括了数据建模、ETL(数据抽取、转换、加载)、作用调度等在内的完整的理论体系流程。数据仓库在构建过程中通常都需要进行分层处理。业务不同,分层的技术处理手段也不同。
数据仓库一般为4层:数据缓冲层、数据明细层、数据服务层、数据应用层(数据集市层)。也可以分为更多不同的层,只要能达到流程清晰、方便查数即可
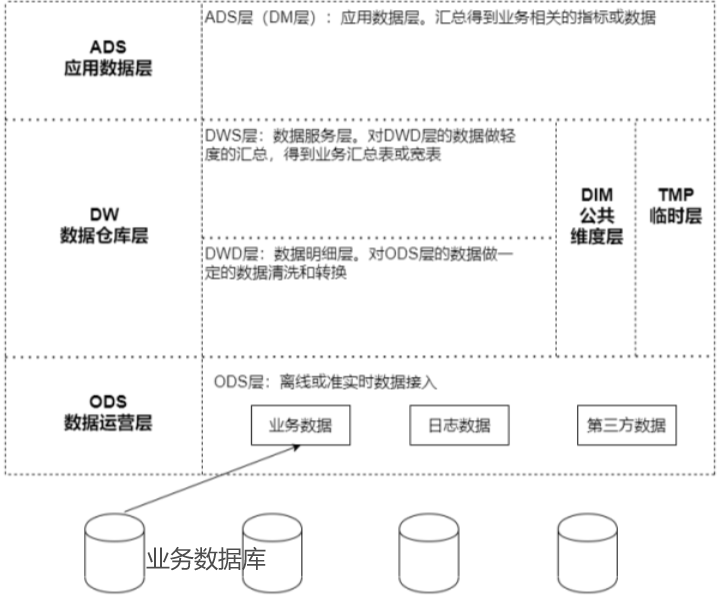
分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控,主要原因有:
1.清晰的数据结构:每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解
2.将复杂的问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的问题,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的地方开始修复。
3.减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
4.屏蔽原始数据的异常:屏蔽业务的影响,不必改一次业务就需要重新接入数据
5.数据血缘的追踪:最终给业务呈现的是一个能直接使用业务表,但是它的来源很多,如果有一张来源表出问题了,借助血缘最终能够快速准确地定位到问题,并清楚它的危害范围。
二、事实表与维度表
2.1事实表
1.在数据仓库中,保存度量值的详细值或存储事实记录的表称为事实表。事实数据表通常包含大量的行。
2.事实数据表的主要特点是包含数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据。事实表的粒度决定了数据仓库中数据的详细程度。
3.常见事实表:订单事实表
4.事实表的特点:表多(各种各样的事实表);数据量大
5.事实表根据数据的粒度可以分为:事务事实表、周期快照事实表、累计快照事实表
常见的事实表有:订单表,销售事实表、库存事实表等。销售事实表包含销售数量、销售单价、销售总额、利润等指标,库存事实表包含库存数量、入库数量、出库数量等指标
2.2维度表
维度表(维表)可以看作是用来分析数据的角度,纬度表中包含事实数据表中事实记录的特性。有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息。
常见的维度表有:日期维表(存储与日期对应的周、月、季度等属性)、地区维表(包含国家、省/州、城市等属性)、商品维表等。
总结:事实表是关注的内容(如:销售额、销售量),维表是观察事务的角度。
三、拉链表
3.1 什么是拉链表?
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
我们先看一个示例,这就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。
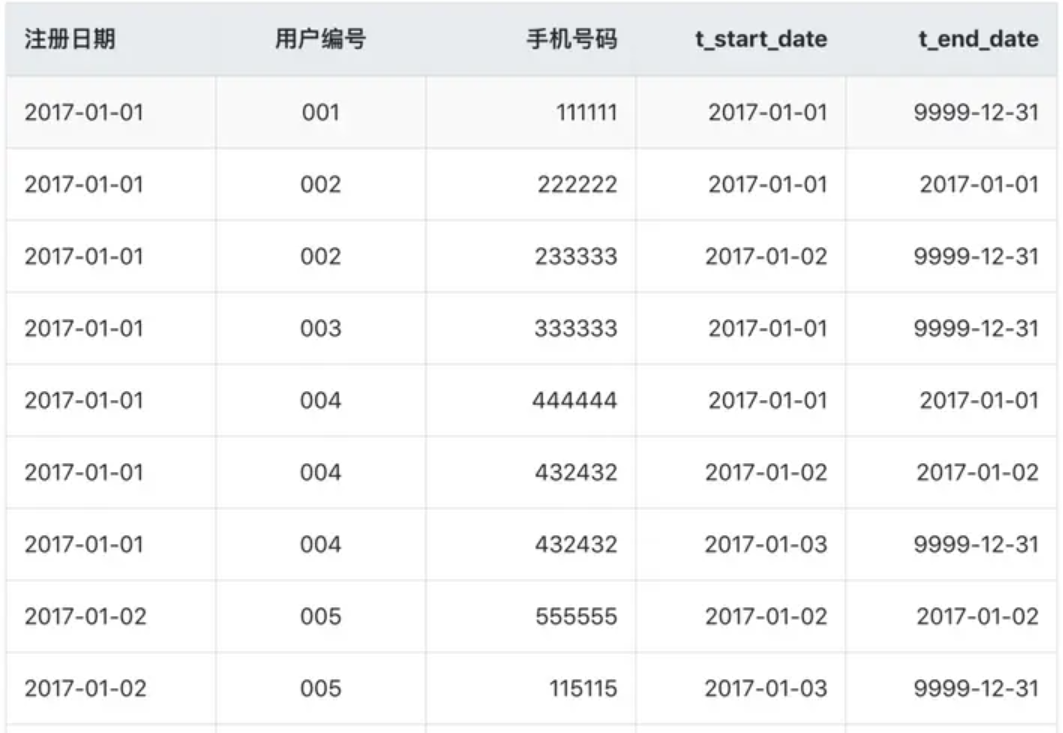
3.2 拉链表的使用场景
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
- 有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
- 表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
- 表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
那么对于这种表我该如何设计呢?下面有几种方案可选:
- 方案一:每天只留最新的一份,比如我们每天用Sqoop抽取最新的一份全量数据到Hive中。
- 方案二:每天保留一份全量的切片数据。
- 方案三:使用拉链表。
3.3 为什么使用拉链表
现在我们对前面提到的三种进行逐个的分析。
方案一
这种方案就不用多说了,实现起来很简单,每天drop掉前一天的数据,重新抽一份最新的。
优点很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
缺点同样明显,没有历史数据,先翻翻旧账只能通过其它方式,比如从流水表里面抽。
方案二
每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点就是存储空间占用量太大太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费,这点我感触还是很深的......
当然我们也可以做一些取舍,比如只保留近一个月的数据?但是,需求是无耻的,数据的生命周期不是我们能完全左右的。
方案三
拉链表在使用上基本兼顾了我们的需求。
首先它在空间上做了一个取舍,虽说不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一。
其实它能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件也获取历史的数据。
所以我们还是很有必要来使用拉链表的。
3.4 拉链表的实现过程
3.4.1 初始化拉链表(首次独立执行)
(1)建立拉链表
drop table if exists dwd_order_info_his;
create external table dwd_order_info_his(
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_info_his/'
tblproperties ("parquet.compression"="snappy");
(2)初始化拉链表
insert overwrite table dwd_order_info_his
select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time,
operate_time,
'2019-02-13',
'9999-99-99'
from ods_order_info oi
where oi.dt='2019-02-13';
3.4.2 制作当日变动数据(包括新增,修改)每日执行
如何获取每日变动数据?
1. 最好表内有创建时间和变动时间(Lucky!)
2. 如果没有,可以利用第三方工具监控比如canal,监控MySQL的实时变化进行记录(麻烦)。
3. 逐行对比前后两天的数据, 检查md5(concat(全部有可能变化的字段))是否相同(low)
4. 要求业务数据库提供变动流水(人品,颜值)
因为dwd_order_info本身导入过来就是新增变动明细的表,所以不用处理
3.4.3 先合并变动信息,再追加新增信息,插入到临时表中
首先建立临时表
drop table if exists dwd_order_info_his_tmp;
create table dwd_order_info_his_tmp(
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链临时表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_info_his_tmp/'
tblproperties ("parquet.compression"="snappy");
导入数据到临时表
insert overwrite table dwd_order_info_his_tmp
select * from
(
select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time,
operate_time,
'2019-02-14' start_date,
'9999-99-99' end_date
from dwd_order_info where dt='2019-02-14'
union all
select oh.id,
oh.total_amount,
oh.order_status,
oh.user_id,
oh.payment_way,
oh.out_trade_no,
oh.create_time,
oh.operate_time,
oh.start_date,
if(oi.id is null, oh.end_date, date_add(oi.dt,-1)) end_date
from
dwd_order_info_his oh
left join
(
select
*
from dwd_order_info
where dt='2019-02-14'
) oi
on oh.id=oi.id and oh.end_date='9999-99-99'
)his
order by his.id, start_date;
3.4.4 把临时表覆盖给拉链表
导入数据
insert overwrite table dwd_order_info_his
select * from dwd_order_info_his_tmp;
查询当前所有有效的记录
select * from dwd_order_info_his where end_date = '9999-99-99'
查询2019-02-14的历史快照
select * from dwd_order_info_his where start_date <= '2019-02-14' and end_date >= '2019-02-14'。(此处要好好理解,是拉链表比较重要的一块)
四、星型模型和雪花模型
星型模型
1.星型模是一种多维的数据关系,它由一个事实表和一组维表组成;
2.事实表在中心,周围围绕地连接着维表;
3.事实表中包含了大量数据,没有数据冗余;
4.维表是逆规范化的,包含一定的数据冗余;
5.星型模型不考虑维表正规化的因素,设计、实现容易,但是存在数据冗余,所以在查询统计时只需要做少量的表连接,查询效率高;
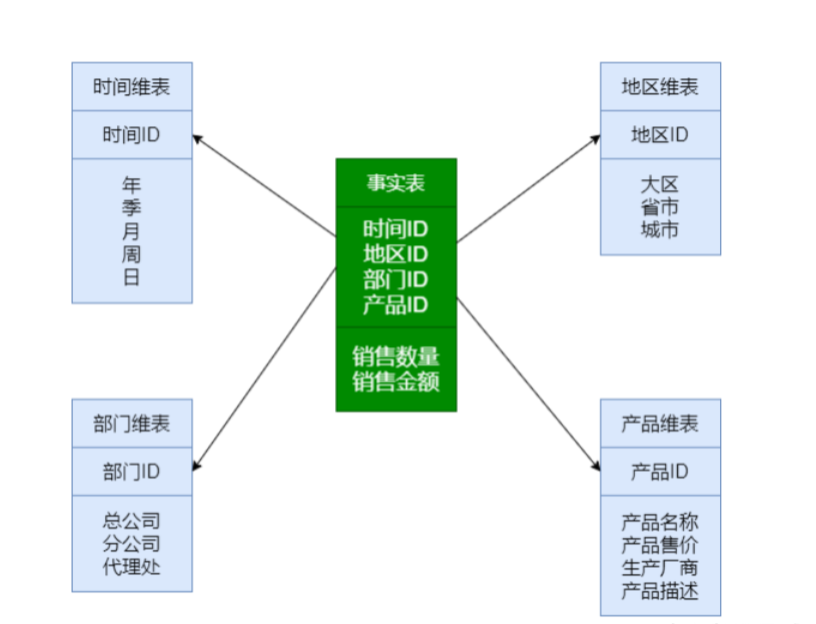
雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表
特点:雪花型结构去除了数据冗余。
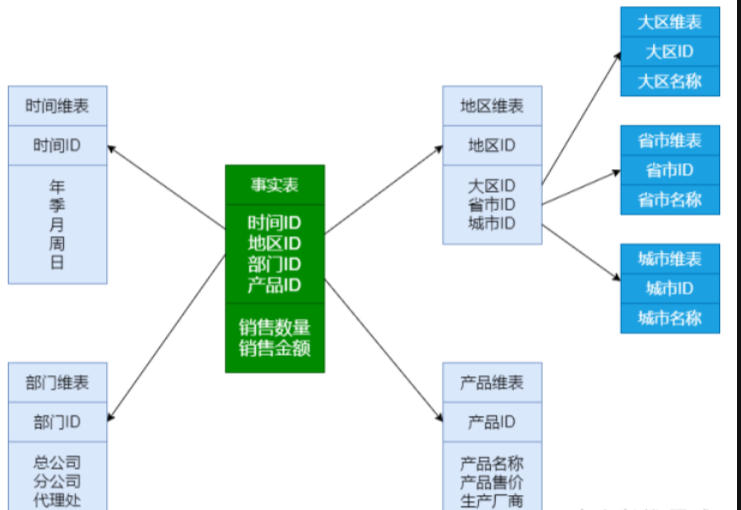
五、星型模型VS雪花型模型
星型模型和雪花模型的对比,可以从以下四个角度来对比。
1、查询性能角度来看
在OLTP-DW环节,由于雪花型要做多个表联接,性能会低于星型架构;但从DW-OLAP环节,由于雪花型架构更有利于度量值的聚合,因此性能要高于星型架构。
2、模型复杂度角度
星型架构更简单方便处理
3、层次结构角度
雪花型架构更加贴近OLTP系统的结构,比较符合业务逻辑,层次比较清晰。
4、存储角度
雪花型架构具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型架构会产生数据冗余。
六、总结
根据项目经验,一般建议使用星型模型。因为在实际项目中,往往最关注的是查询性能问题,至于磁盘空间一般都不是问题。当然,在维度表数据量极大,需要节省存储空间的情况下,或者是业务逻辑比较复杂、必须要体现清晰的层次概念情况下,可以使用雪花型模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号