
Mysql索引
索引优化速度

首先创建了一个数据库,并创建了一个表,里面有800w条记录
对其中的一条记录进行查询,使用了4.5s
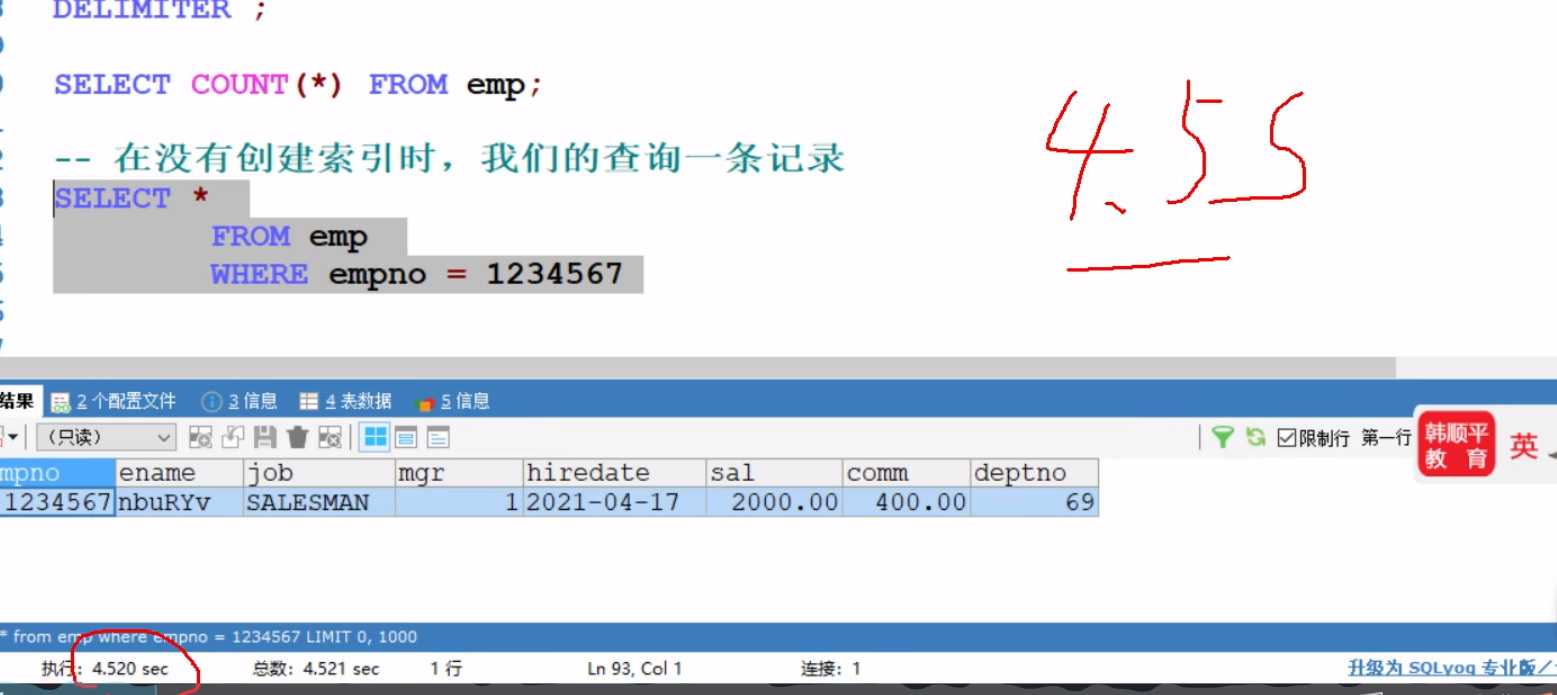
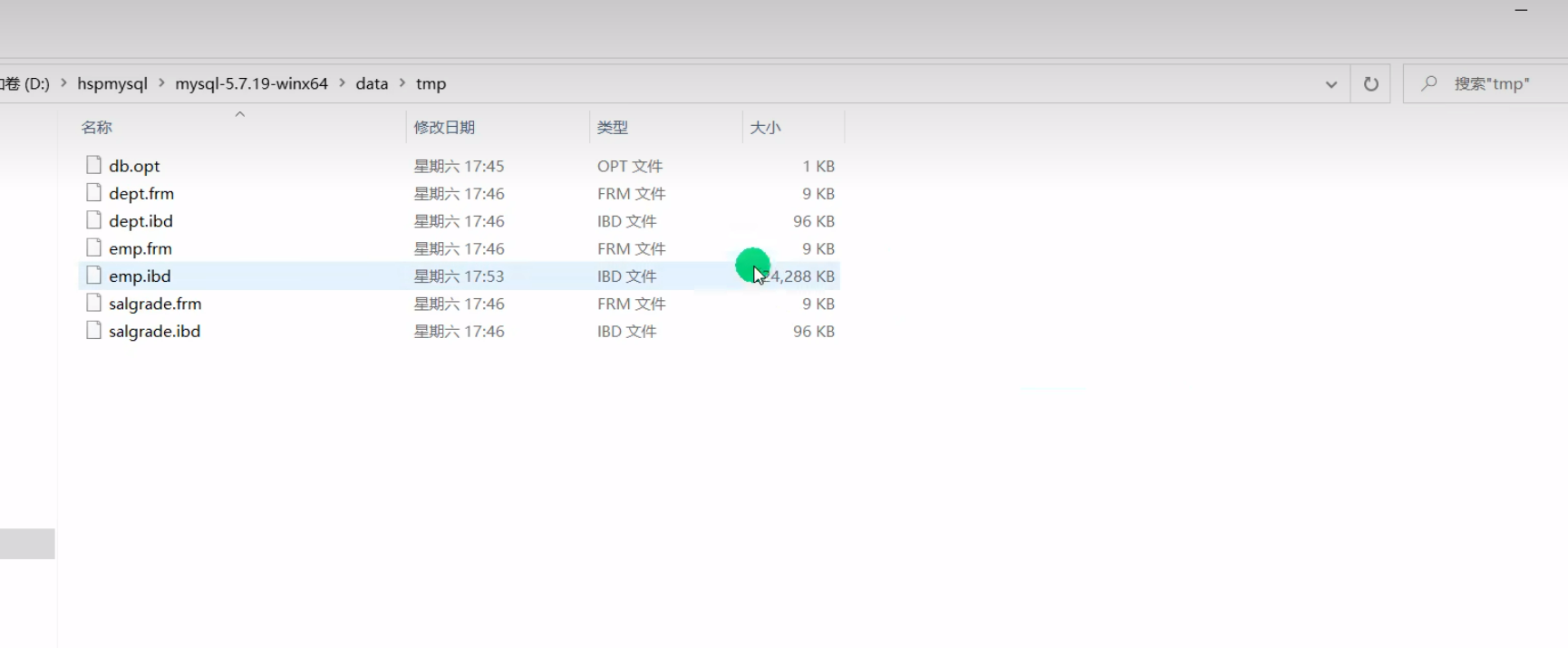
此时存储这个表的文件已经有500M的大小了
添加索引后发现,刚刚存储表的文件变大了,变成了655m
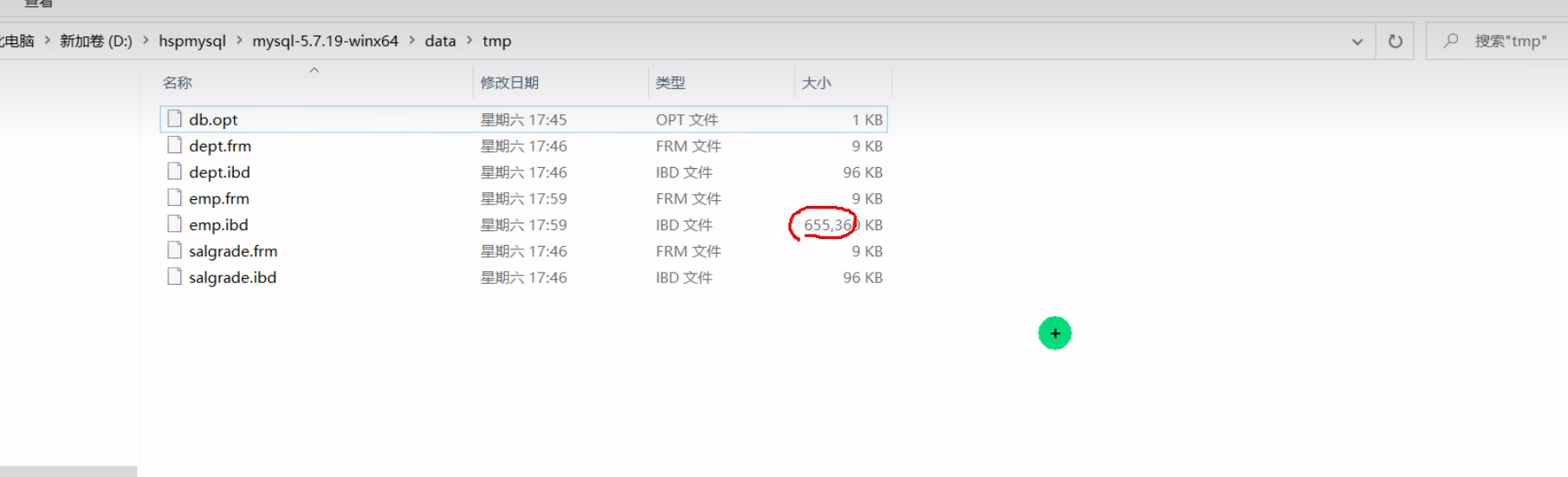
索引需要占用磁盘空间
-
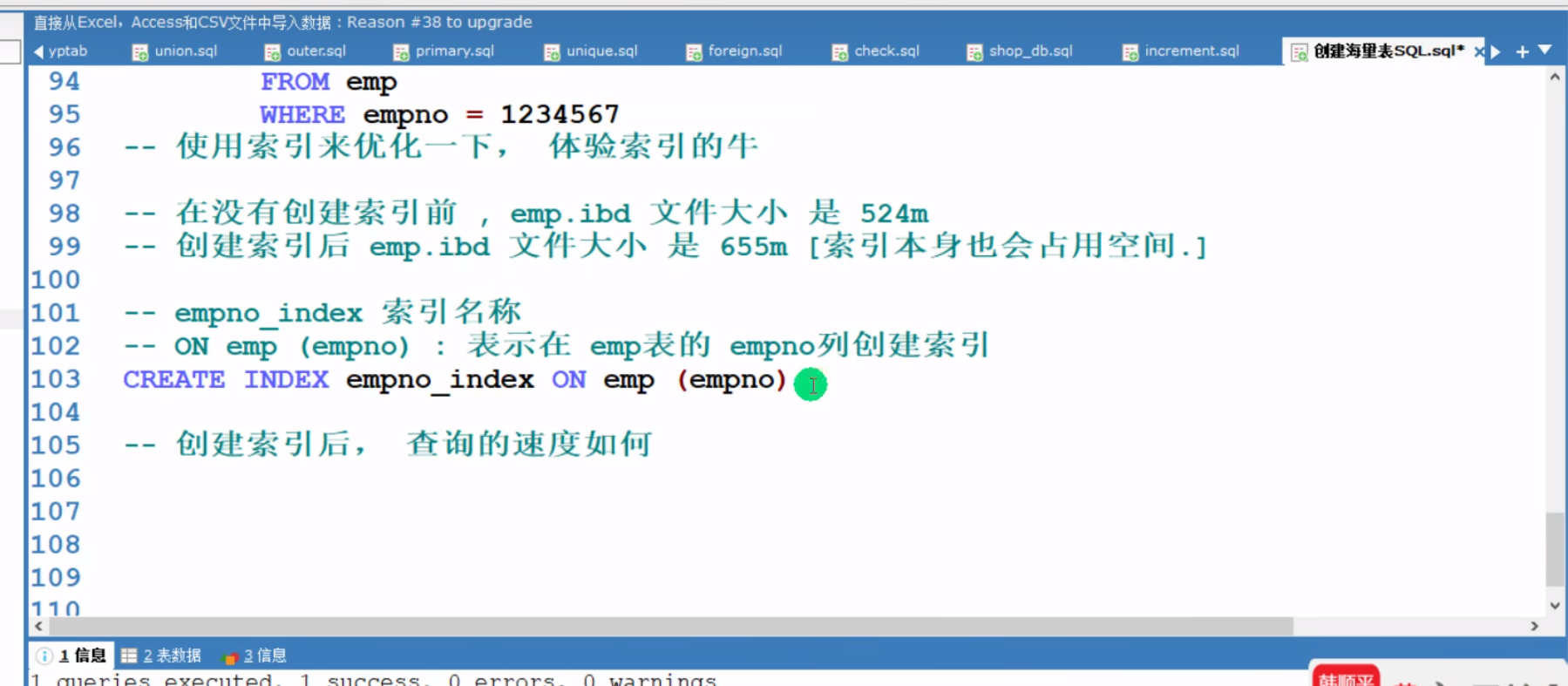
索引创建
![]()
-
使用索引查询
![]()
我们创建索引只对创建索引所对应的列有效,如果使用其他的列进行查询还是很慢。所以我们创建索引并不能解决所有的问题 -
索引占用磁盘空间
-
创建一个索引并不能对所有的列都起作用

索引机制

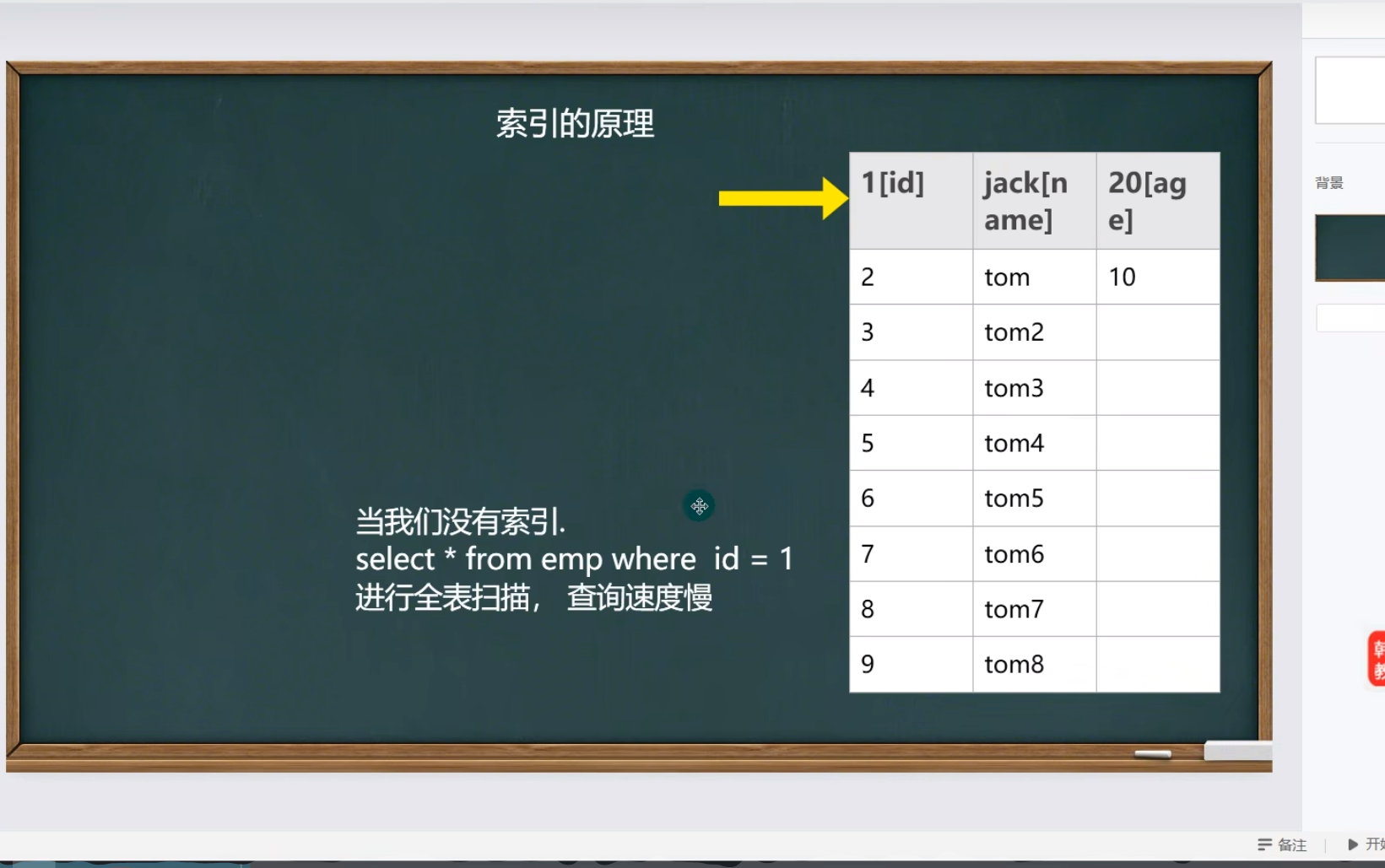
当我们查询时,将会一条一条记录进行比对,直到比对到表尾,因为他不能确定表的后面还有没有符合条件的记录
索引优化原理
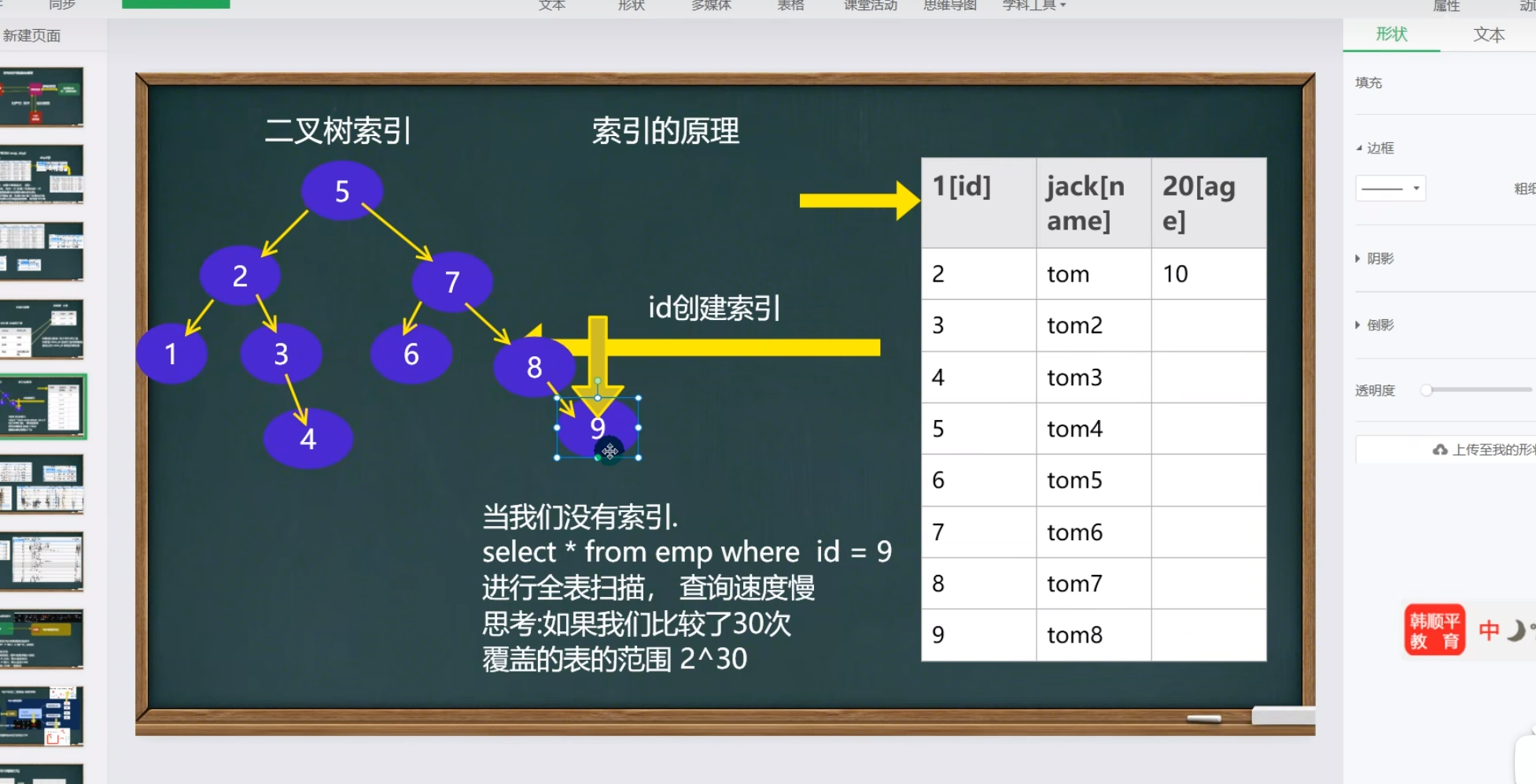
通过创建一个索引二叉树来优化查询,头节点左子树的值偶读小于左子树,右子树的值都大于头节点
这个索引的数据结构可能是二叉树,也可能是其他的数据结构
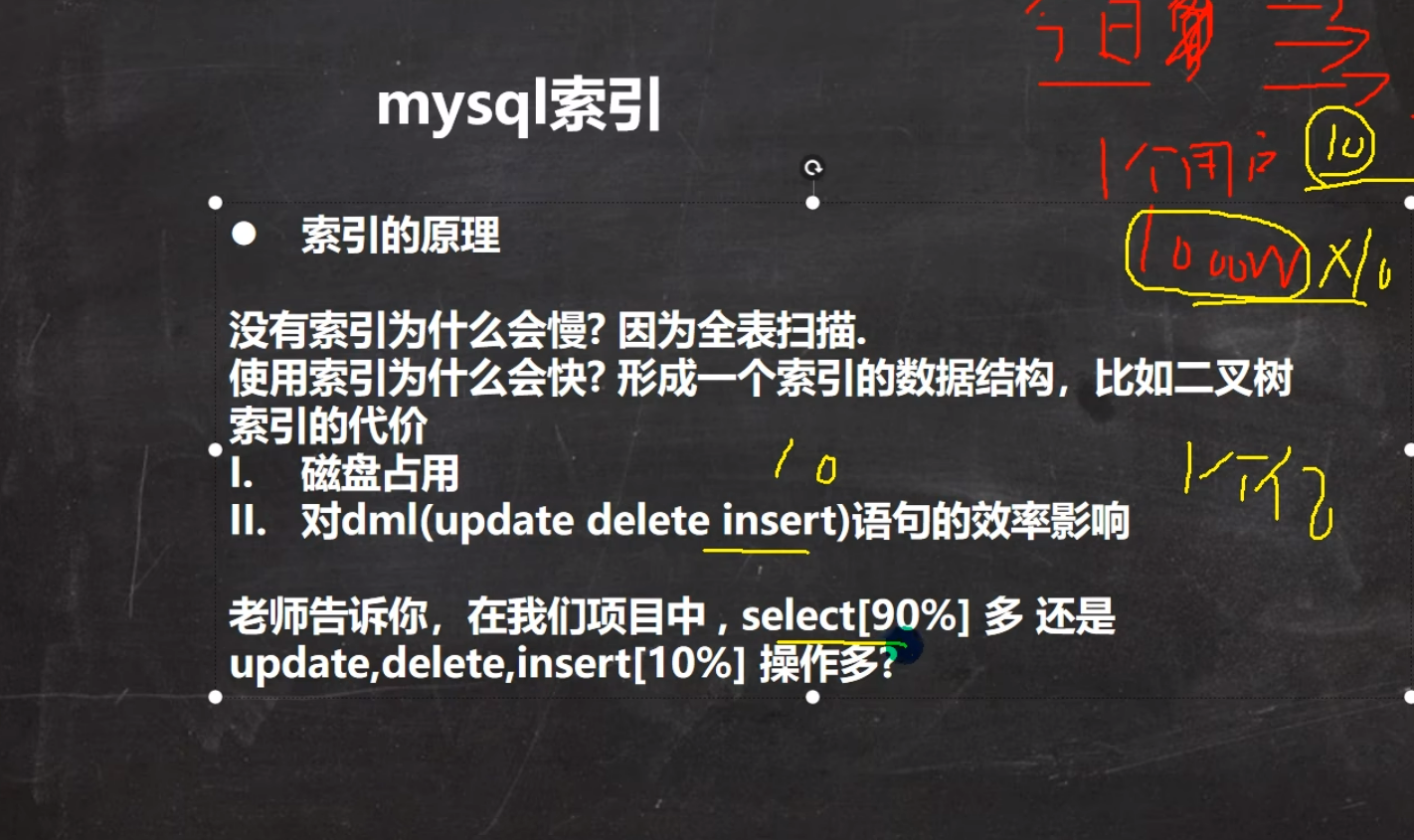
索引对删除修改插入语句的效率会有影响
我们的表中插入了索引,当我们对表中的数据进行改变时,势必将会得到我们的索引数据结构改变,将会重新维护这个索引数据结构,将会有速度影响
** 索引可以加速查询,但是也会对我们的删除插入和修改语句带啦效率影响,为什么还有使用?**
因为在显示生活中查询语句的使用量是远远大于删除修改和插入语句的,使用索引利大于弊
- 问题总结
![]()
创建索引
mysql自带的全文索引不好用,在java开发中不会去直接使用mysql自带的全文所以
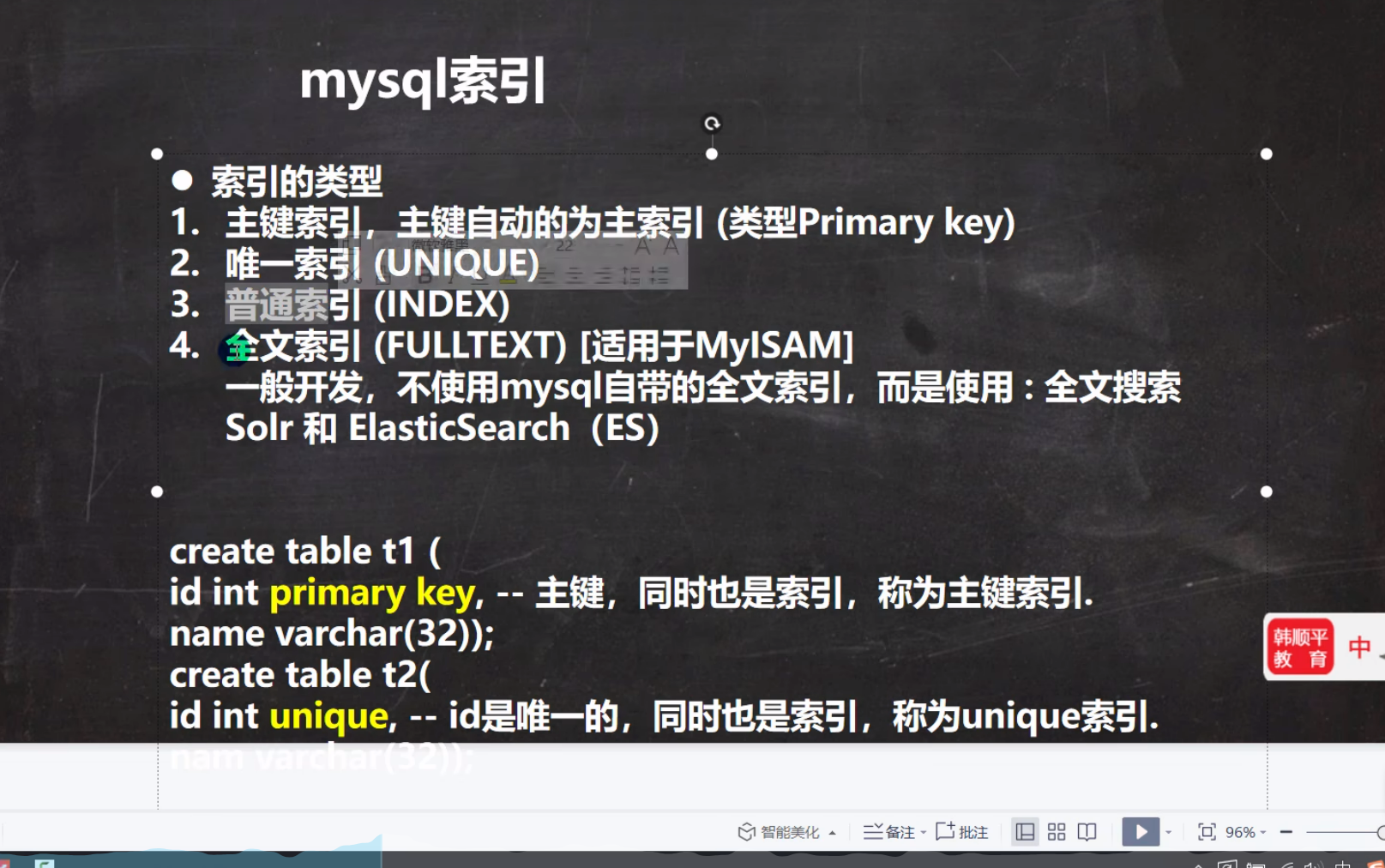


我们的主键和unique约束自带主键索引和唯一索引
-- 演示mysql索引的使用
-- 1 创建一个表
CREATE TABLE t27(
id INT,
`name` VARCHAR(32))
-- 2.查询表中是否有索引
SHOW INDEXES FROM t27-- 将会显示没有索引
-- 添加索引
-- 1.添加唯一索引
CREATE UNIQUE INDEX id_index ON t27(id)-- 在t27表的id列创建唯一索引
-- 2.添加普通索引方式1
CREATE INDEX id_index ON t27(id)
-- 如何选择
-- 如果某列的值是不会重复的,则优先选择使用unique索引,否则使用普通索引
-- 添加普通索引方式2
ALTER TABLE t27 ADD INDEX id_index(id)
-- 添加主键索引
ALTER TABLE t27 PRIMARY KEY id_index(id)
删除和查询索引
-- 删除索引
DROP INDEX id_index ON t25
-- 删除主键索引
ALTER TABLE t25 DROP PRIMARY KEY
-- 修改索引
-- 先删除,再添加新的索引
-- 查询索引(有几个索引将会显示几个索引)
-- 方式1
SHOW INDEX FROM t25
-- 方式2
SHOW INDEXES FROM t25
-- 方式3
SHOW KEYS FROM t25
-- 方式4
DESC t25-- key列显示的值就是索引,但是没有前面3种方式显示的那么详细
- 课后练习题
![]()
![]()


创建索引的规则
如果我们建立索引的列频繁的修改,就会导致我们频繁的对二叉树索引进行唯一,速度就会有明显的影响了
创建索引的规则


 浙公网安备 33010602011771号
浙公网安备 33010602011771号