
跨函数使用内存
- 之前理解
- 跨函数使用内存
- 内存结构
- 对java创建链表的理解
之前理解
在学习c语言的时候我一般先去记住了一些结论,而没有去理解它为什么要这么做。以下是其中的一种情况
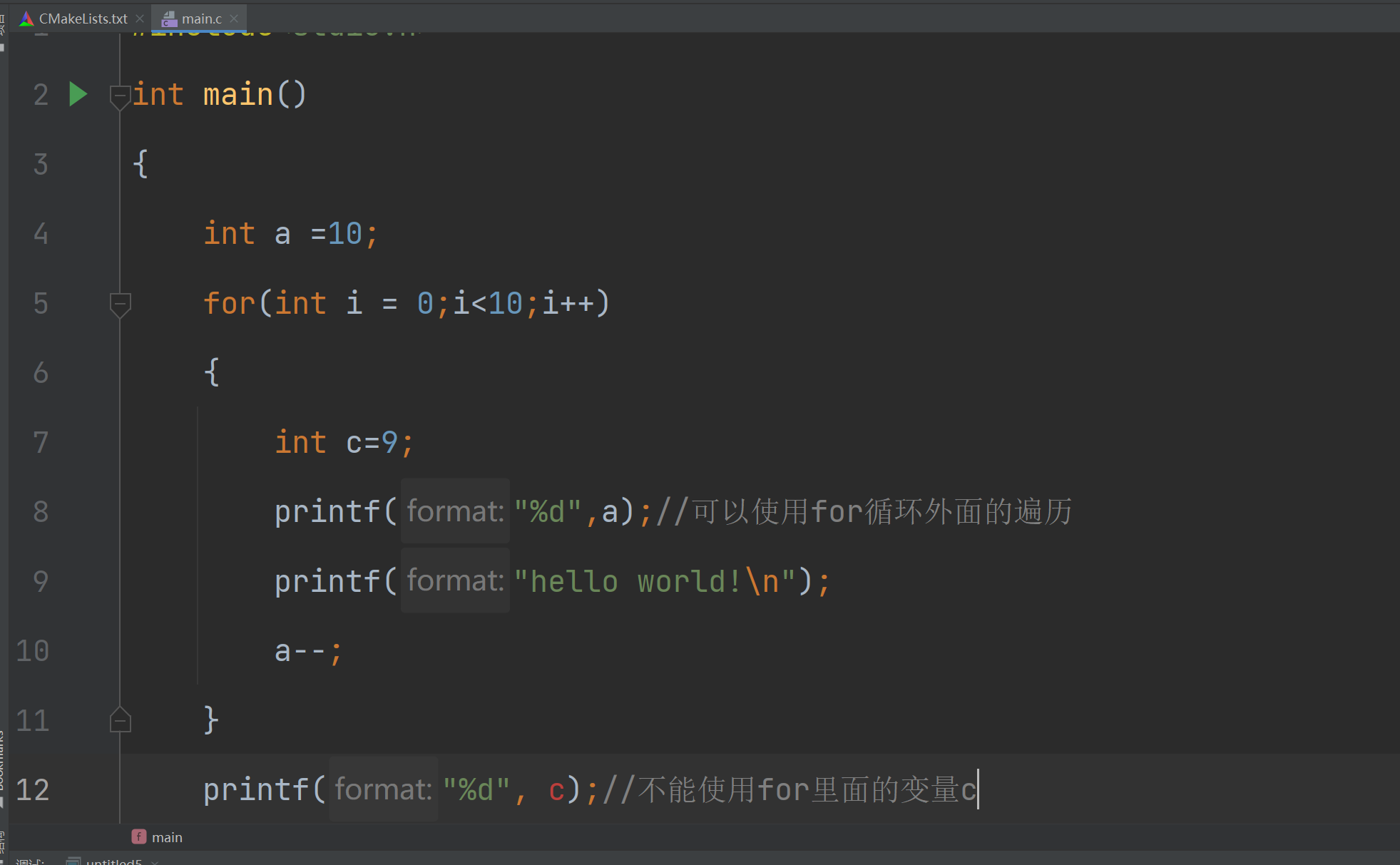
对于为什么会出现上面的情况,在以前我都是硬记的({}可以使用{}外面的但是{}外面的不能使用{}里面的变量)。现在我对这种情况有了一些新的理解
跨函数使用内存
一个基本事实:一个函数在调用完毕后,操作系统会收回该段内存空间,其中的定义局部变量也将消失
#include<stdio.h>
int f();//声明该函数
int main()
{
int i=10;
i=f();
printf("i=%d\n",i);//output:20
}
int f()
{
int j = 20;
return j;
}
当我们f函数调用完成后,其中的局部变量j将 会消失,将不能被使用
此时我们对前面的问题进行理解:不能使用变量c是因为在我们使用c的使用前面的for循环已经调用完成,for循环的内存已经被回收了,里面的局部变量已经消失了。每个{}都是一段独立的局部变量空间,他们之间不能相互访问。其中的main函数也是一个局部变量空间,而for也属于main里面,所有for里面可以访问变量a
内存结构
java和c语言中关于内存的划分不尽相同,但是对于栈区和堆区所存放的内存却都差不多
在java中栈中存储局部变量,或者是引用变量(相当于c中的指针变量),而堆区中存储new出来的对象(c中储存malloc申请的空间)
栈中存储的局部变量,会随着函数的调用被分配内存然后存在,当函数调用完成后将会随之消失
堆中存储的内存,如果是c语言需要手动free释放内存,而java中将会自动回收内存
- 其实栈内存的分配顺序是按照后进先出来的
![]()
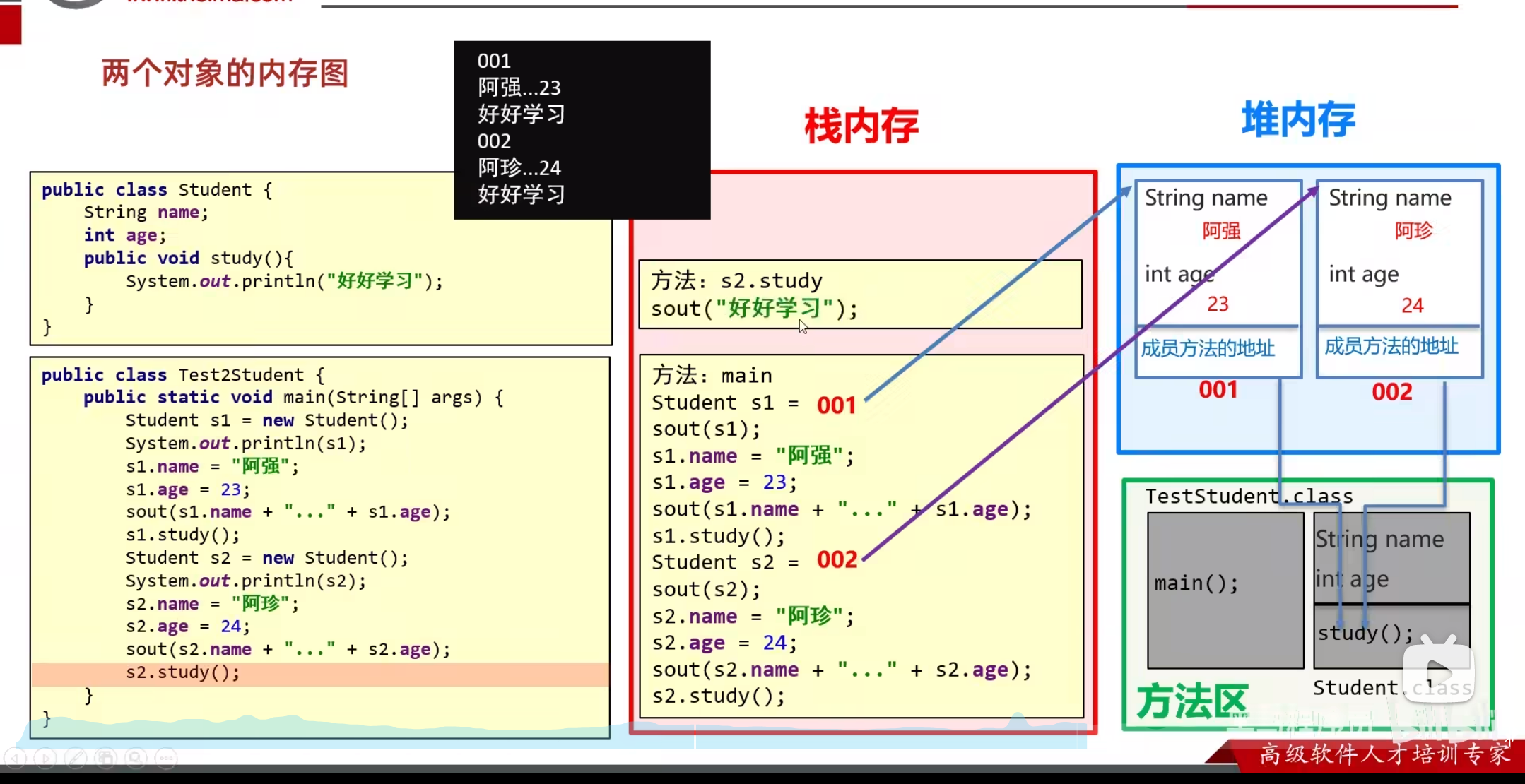
上面的这段代码中main方法先进站,最后出栈。按照后进先出的顺序
对java创建链表的理解
public static void initList(Node head, int n) throws IOException { //p为头节点的地址,n为需要创建的结点数
Scanner sc = new Scanner(System.in);
Node q = head;//用于后面的连接结点
String name;
int age;
String number;
for (int i = 0; i < n; i++) {
System.out.printf("请输入第%d个节点的姓名:\n", i + 1);
name = sc.nextLine();
System.out.printf("请输入第%d个节点的年龄:\n", i + 1);
age = sc.nextInt();
sc.nextLine();//接收多余的回车
String tempNumber;//临时接收电话号码
while (true){
System.out.printf("请输入第%d个节点的电话号码:\n", i + 1);
tempNumber = sc.nextLine();
if(isUniqueNumber(head,tempNumber)){//电话号码有重复
System.out.println("电话号码输入重复,请重新输入!");
}else {
break;
}
}
number = tempNumber;
//创建新结点
Reporter reporter = new Reporter(name, age, number);
Node node = new Node(reporter, null);
list.add(node);//将结点添加到集合中
serializeNode(list);//将该集合写入文件中
//连接结点
Node p = node;
q.setNext(p);//让第一个结点的引用指向第二个结点
q = p;//q移动到下一个结点
count++;//结点的数量+1
}
}
上面的这段代码是使用java实现对一个链表结点的连接
我之前一值没有想过:为什么运行了这个方法之后就一定可以得到一个链表,局部变量{}的内容在方法结束后不是将会消失吗
确实将会消失,但是java中对于结点的创建使用的是new,这将会为结点分配堆内存,在函数结束后堆内存将不会消失

 浙公网安备 33010602011771号
浙公网安备 33010602011771号