
字节流的基本流:FileInputStream
-
FileInputStream的基本用法
-
字节输出流的循环读取
-
文件的拷贝
-
文件拷贝的弊端和改进方案
FileInputStream的基本用法
package com;
import java.io.*;
public class ByteStreamDemo1 {
public static void main(String[] args) throws IOException {
/*
演示FileInputStream
需求:读取文件中的数据(暂时不写中文)
实现步骤:
创建对象
读取数据
释放资源
*/
//1.创建对象
FileInputStream fis = new FileInputStream("small\\www.txt");
//2.读取数据
int read = fis.read();
System.out.println((char)read);//将int类型强制转成char
int read1 = fis.read();
System.out.println((char)read1);
int read2 = fis.read();
System.out.println((char)read2);
int read3 = fis.read();
System.out.println((char)read3);
int read4 = fis.read();
System.out.println((char)read4);
//注意该题的前提下只有abcde 5个数据
int read5 = fis.read();
System.out.println(read5);//-1
//3.释放资源
fis.close();
}
}
注意:
- 1.read方法读取数据返回的是这个数据的十进制,如果需要看到字符,我们需要进行强制类型转换
- 2.read方法当读取不到数据的时候会返回-1
FileInputStream读取数据的细节

疑问:为什么FileInputStram关联的文件不存在将会抛出异常,而FileOutputStram关联的文件不存在时,在父级路径正确的情况下将会创建该文件?
数据是革命的本钱,在IO流中数据是最重要的。FileOutStram的作用是向文件中写入数据,在这种情况下数据从内存写入到文件中,数据已经存在了,这种情况下只用创建出一个空文件,然后将数据写入到空文件就可以了
FileInputStream的作用是将文件中的数据读取到内存中,FileInputStram是链接内存和带有数据的文件,如果关联的文件不存在,数据也就不知道了。在这种情况下java不会创建文件,而是直接抛出异常
FileInputStream的循环读取
从前面的示例可以看到只能一个字节一个字节的读取,如果需要读取多个数据,需要写很多遍读取语句,这样太麻烦了,其实可以用read方法结合while进行循环读取
package com;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class ByteStreamDemo3 {
public static void main(String[]args) throws IOException {
/*
字符串输入流的循环读取
*/
//1.定义流的对象并把文件放在流上面
FileInputStream fis = new FileInputStream("small\\www.txt");
//2.进行循环读取
int b;//定义第三方变量接受read的结果
while ((b = fis.read()) != -1){
System.out.println( (char)b);
}
}
}
当read方法读不到数据时,将会返回-1,以此来决定读取数据是否结束
注意:我们必须用第三方变量来储存read方法的返回值,如果在while循环中直接使用fis.read()相对于再次调用了read方法,这将导致有的数据没有在while循环中被操作
文件的拷贝
我们已经了解了FileOutputStram(读出数据)和FileInputStream(写入数据),通过这2个类我们就可以实现对文件的拷贝了
package com;
import java.io.*;
public class ByteStreamDemo1 {
public static void main(String[] args) throws IOException {
//文件拷贝的基本代码
//注意:选择一个比较小的文件,大文件拷贝下一个视频再说
//由于没有mp4文件,我们以txt为例
//1.创建对象
FileOutputStream fos = new FileOutputStream("small\\sss.txt");
FileInputStream fis = new FileInputStream("C:\\Data\\a1.txt");
//2.拷贝
//核心思想:边读边写
//先将文件里面的内容读出来 然后写入到新的文件中
int b;//
while ((b = fis.read())!=-1){
fos.write(b);
}
//3.释放资源
//规则:先开的最后释放
fos.close();
fis.close();
}
}
文件拷贝的弊端和解决方案
这2个流只能对字节进行操作,在上面的操作中拷贝的思想是边读边写,即从源文件中读出一个字节的数据,然后将这个字节的数据写入到目标文件中

当文件过大,我们的拷贝速度将会很缓慢
解决方案就是,一次读取一个字节数组,一次写入一个字节数组
- read方法
read()方法当读取到数据时,返回所读取到的数据的int表示,当没有读取到数据时返回-1 read(byte[])方法当读取到了数据时,返回本次所读取到的数据的字节个数,当没有读取到数据也会返回-1
reaad(byte[])方法里面的参数是字节数组,我们可以根据文件的大小设置一次读取的大小

read(byte[]bytes)方法可以一次读取一个字节数组,然后把读取的数据返回到这个字节数组中, read(byte[]bytes)方法返回返回此次读取了多少个字节并且方法将每次读取的数据会覆盖原来数组中的数据
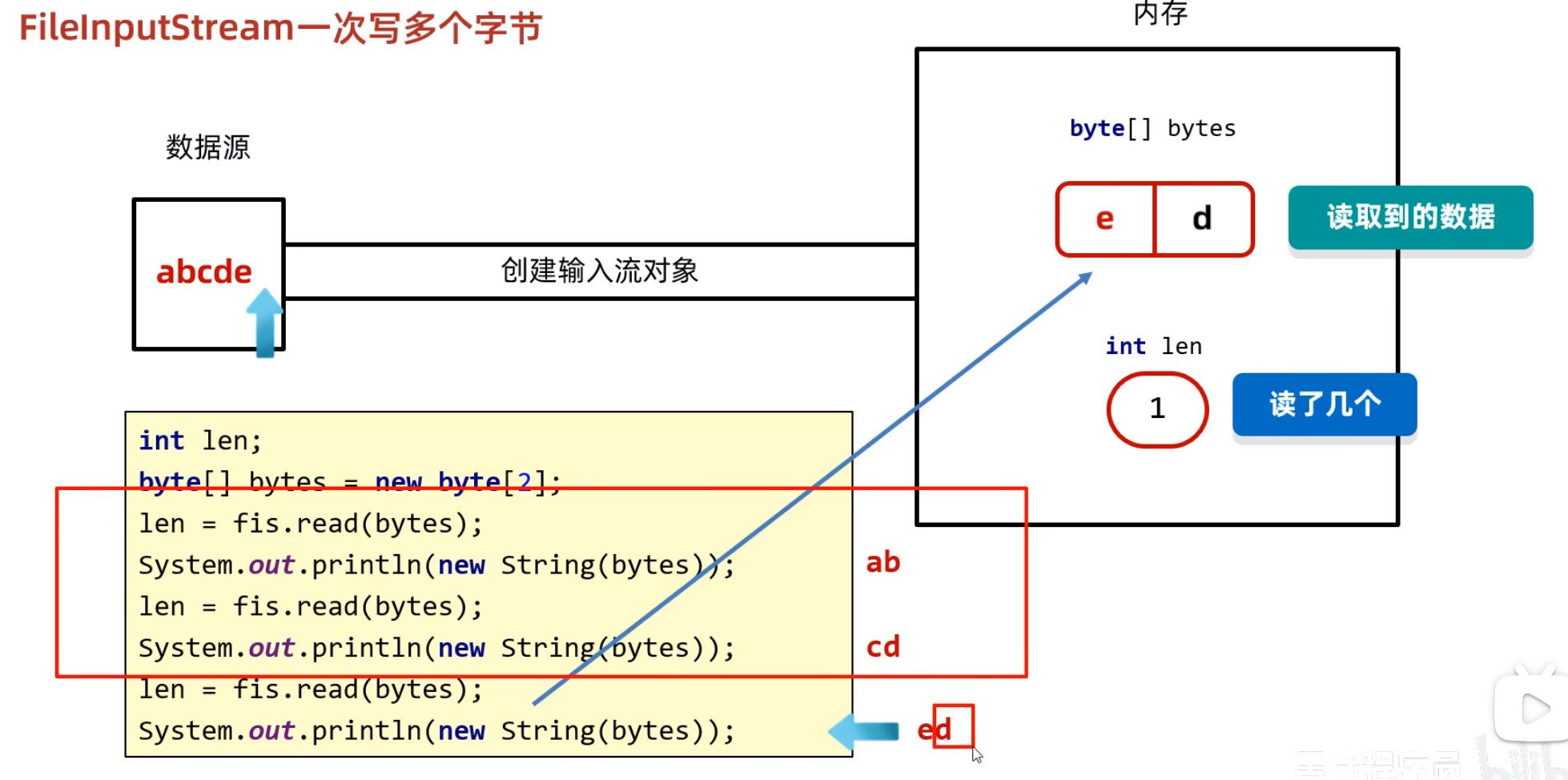
在我们读取数据的过程中,我们不断的用读取到的数据来跟新数组中所记录的数据,这样就会带来一个问题,当最后一次读取到的数据无法将数组装满时,我们的数组中就会有上一次读取的残留数据,如上图所示:
改进方案
我们在把读取到的数据返回时,用到了new String()把字节数组变成字符串,其实还有一个重载的构造方法,可以把一部分字节数组变成字符串

**拷贝文件的改进版**
package com;
import java.io.*;
import java.util.Arrays;
public class ByteStreamDemo3 {
public static void main(String[]args) throws IOException {
//文件的拷贝(提速版)
//将C:\Data\a1.txt下的内容拷贝到small\sss.txt中
//1.定义流的对象
FileInputStream fis = new FileInputStream("C:\\Data\\a1.txt");
FileOutputStream fos = new FileOutputStream("small\\sss.txt");
//2.进行拷贝:边读边写
//定义字节数组
int len;//第三方变量
byte[] bytes = new byte[2];//规定其最多一次读取2个字节
while ((len = fis.read(bytes))!=-1){
fos.write(bytes,0,len);//读取多少即写入多少
}
//3.关闭资源
fos.close();
fis.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号