字符集和字符编码(Charset & Encoding)
- 字符集和字符编码的概述
- 编码和解码
- ASCII字符集&字符编码
- GBK字符集&字符编码
- Unicode字符集&字符编码
字符集和字符编码的概述
根据我们仅有的基础知识知道:我们的计算机所有的信息都是二进制表示的,即我们的计算机也只能储存二进制的数据。那为什么我们在现实生活中可以看到各种各样字符,并且可以把各种各样的字符储存到计算机里面呢?
由此我们可以做出合理的猜想:在我们的计算机中肯定有一套转换规则,这个规则可以将我们的字符转换成二进制储存到计算机中,在我们需要阅读的时候再次从二进制转换成字符呈现在我们的眼前,在计算机当中确实存在这样一种规则,即字符集和字符编码
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项*本技术。
说白了,字符集就是字符集就是装有字符和其所对应的二进制和其所对应的集码(十进制数据)的一个集合。而字符编码即是一种转换规则,即由我们的字符转换到二进制和计算机的二进制怎样转换成字符的转换规则
编码和解码
编码: 编码可以看成是加密的过程,在我们向计算机中储存字符时,我们的字符经过字符编码规则加密成二进制储存进计算机中
解码:解码可以看成是解密的过程,储存在计算机中的二进制数据,经过字符编码规则解密成字符**
ASCII历史
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是*于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。
ASCII字符集
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 如下图示 ASCII编码表
![]()
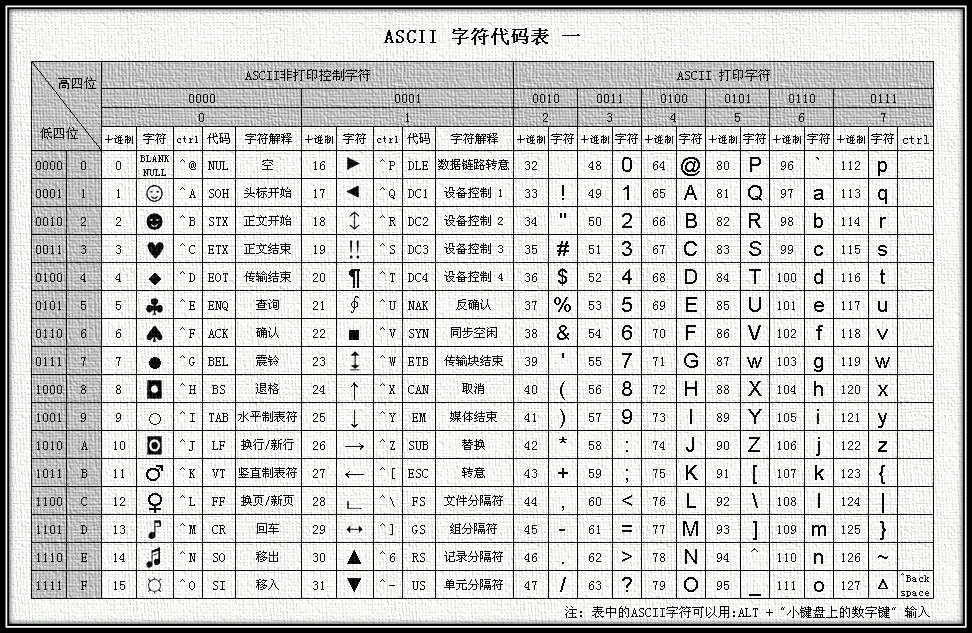
ASCII编码规则

总结来将就是:如果我们要储存字符a,会先找到a在字符集中对应的数字,然后找到数字对应的二进制,然后根据ASCII的编码规则,二进制没有8位会在前面补零,解码的过程与之相反
ASCII的缺陷
**ASCII使用一个字节来储存字符,其中最多可以储存256个字符,这个对于美国等国家已经足够了。但是这对我国汉字来说是远远不够的,那我们该怎么办呢?
**

GBK字符集&字符编码
GBK储存英文
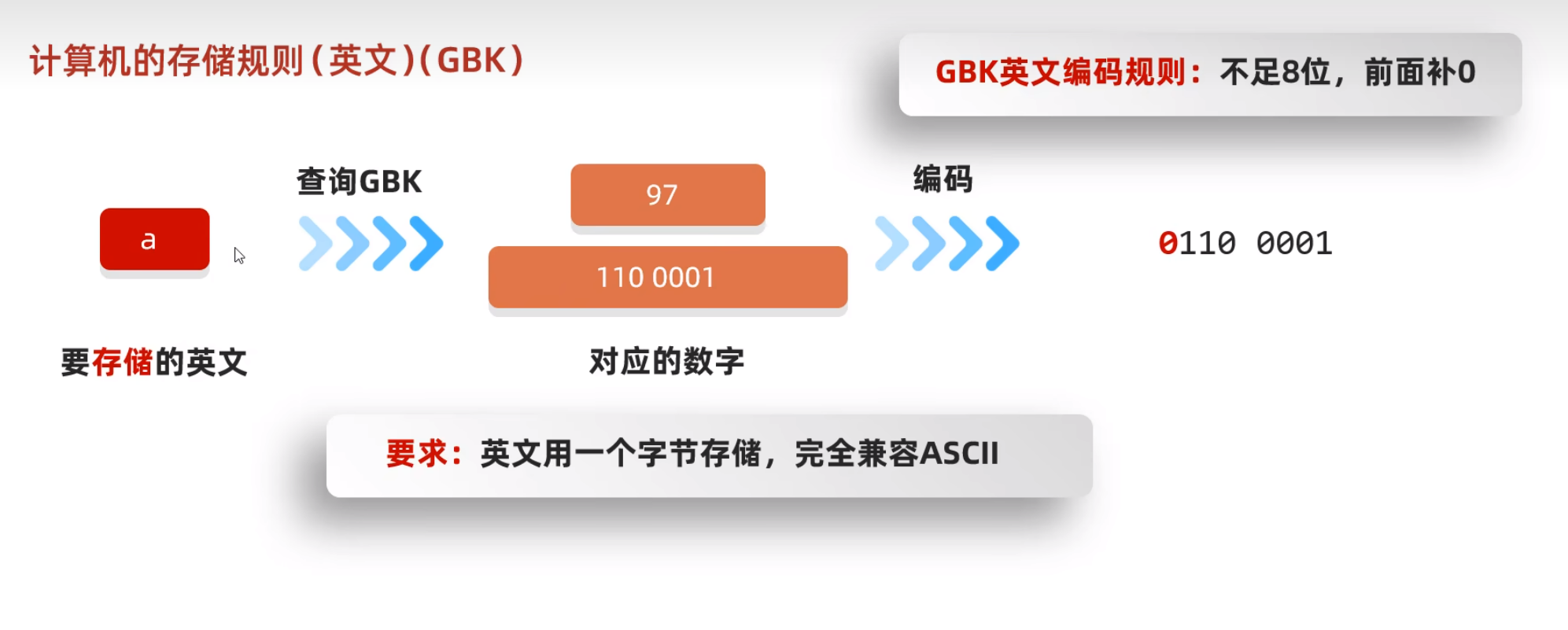
总结来讲就是:GBK完全兼容ASCII,储存规则和ASCII一摸一样
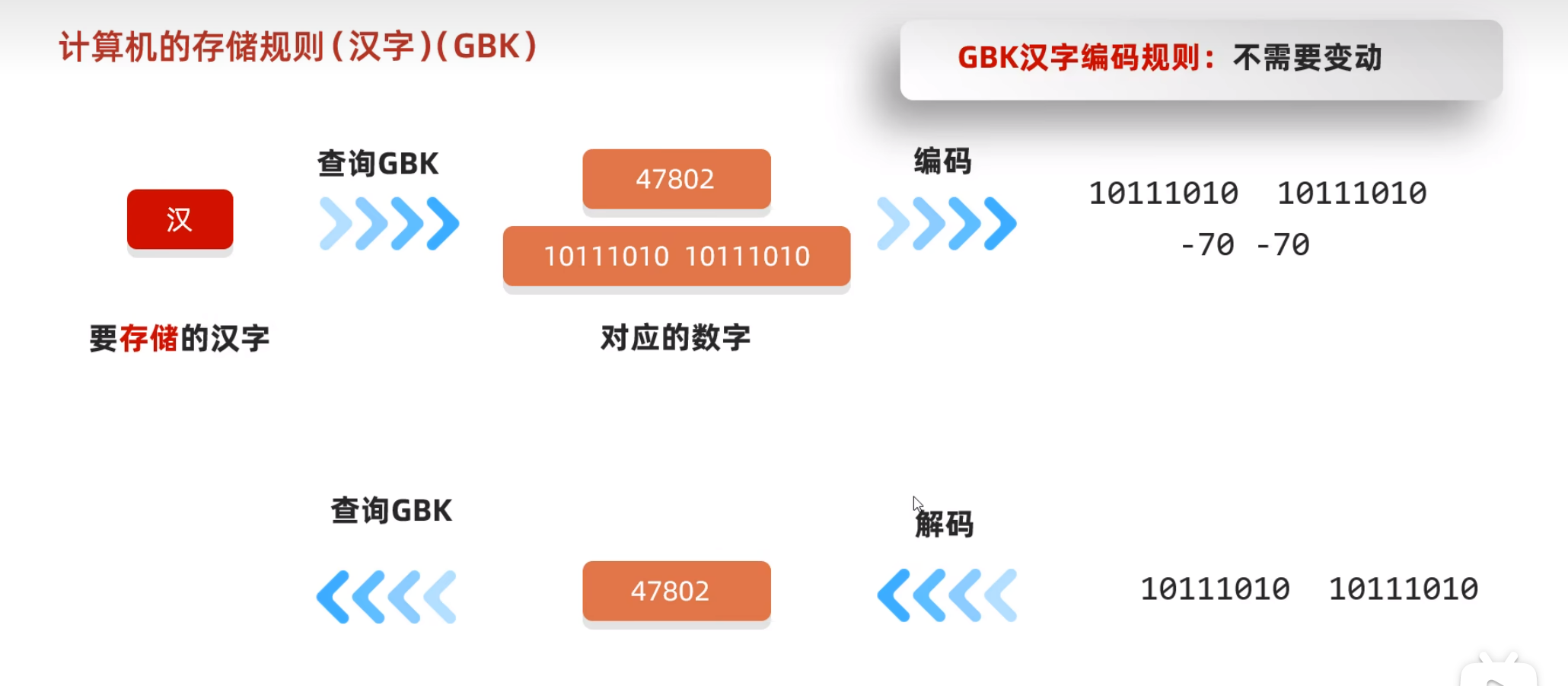
GBK储存汉字

为什么规则高字节必须以1开头?
用于区分中文和英文。因为英文以0开头并且是一个字节储存,而汉字是以1开头2个字节储存,当计算机读取时以1开头将会知道是中文然后一下读取2个字节,当以0开头将知道是英文一下读取一个字节。

读取和写入过程示范
伟大的创想--------------Unicode
这之后很多国家都推出了符合本国语言的字符集,每种语言都有自己的字符集和编码,这样就很混乱了。穷则独善其身,达则兼济天下。一部分计算机专家就开发出了一个新的字符集,企图把世界上绝大多数语言都包含进来,也就是UNICODE

Unicode英文编码规则

总结一句:也全面兼容ASCII,编码规则完全一样
中文UTF-8编码规则

UTF-8使用1-4个字节来编码世界上的所有文字,汉字是用3个字节来编码的
UTF-8中文编码规则说明
中文是使用3个字节进行编码的,三个字节上都有一些固定位 分别为: 1110(固定前4位)10(固定前2位)10(固定前2位)
我们在储存汉字时,会先查询Unicode表找到数字,然后找到对应的二进制,然后将这些二进制顺次放到这些固定的字节后面空缺的位上面然后把得到的三个字节的二进制进行储存


 浙公网安备 33010602011771号
浙公网安备 33010602011771号