
集合(进阶 set系列)
泛型

package com.an.a;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class FanxingTest {
public static void main(String[] args) {
List list =new ArrayList();//不申明泛型,默认用Object接收
list.add("hello");
list.add(12);
list.add(23.4);
Iterator it = list.iterator();//获取迭代器
while (it.hasNext()){//判断该指针所指的位置是否有元素
String str=(String) it.next();//获取该位置的元素并往后移动指针
System.out.println(str);
}
}
}
//ClassCastException: java.lang.Integer cannot be cast to java.lang.String
// at com.an.a.FanxingTest.main(FanxingTest.java:15)
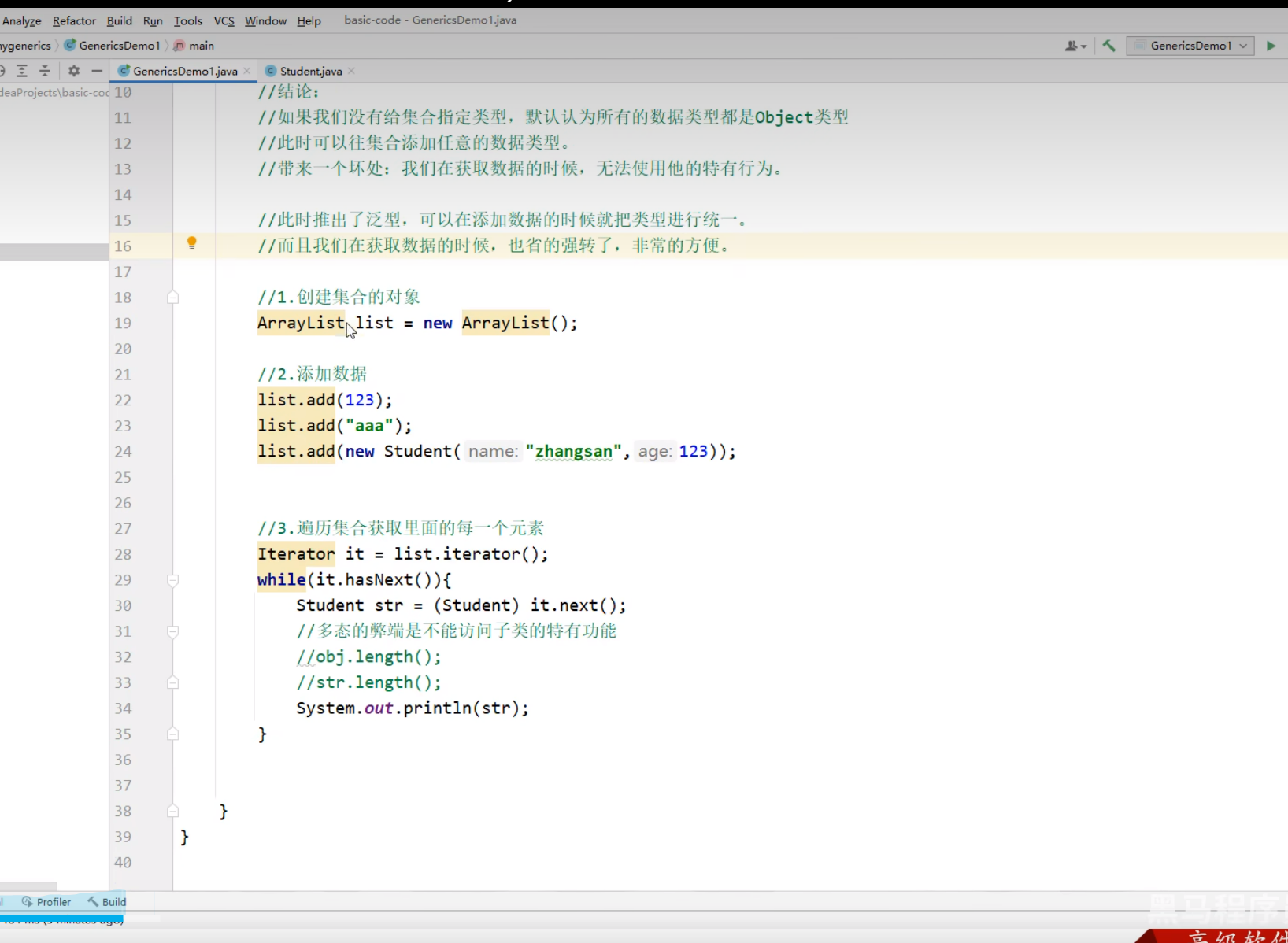
- 当集合不声明泛型将会默认以Object进行接收
- 这样将会导致集合可以接收任意类型的数据,这样将导致数据混乱,不利于使用
- 这样接收将会导致无法使用子类特有的行为
- 如果储存的数据类型和泛型的类型不同将会在编译期间报错
想要使用子类特有的行为必须要向下转型,但是向下转型极有可能导致ClassCastException

java的伪泛型
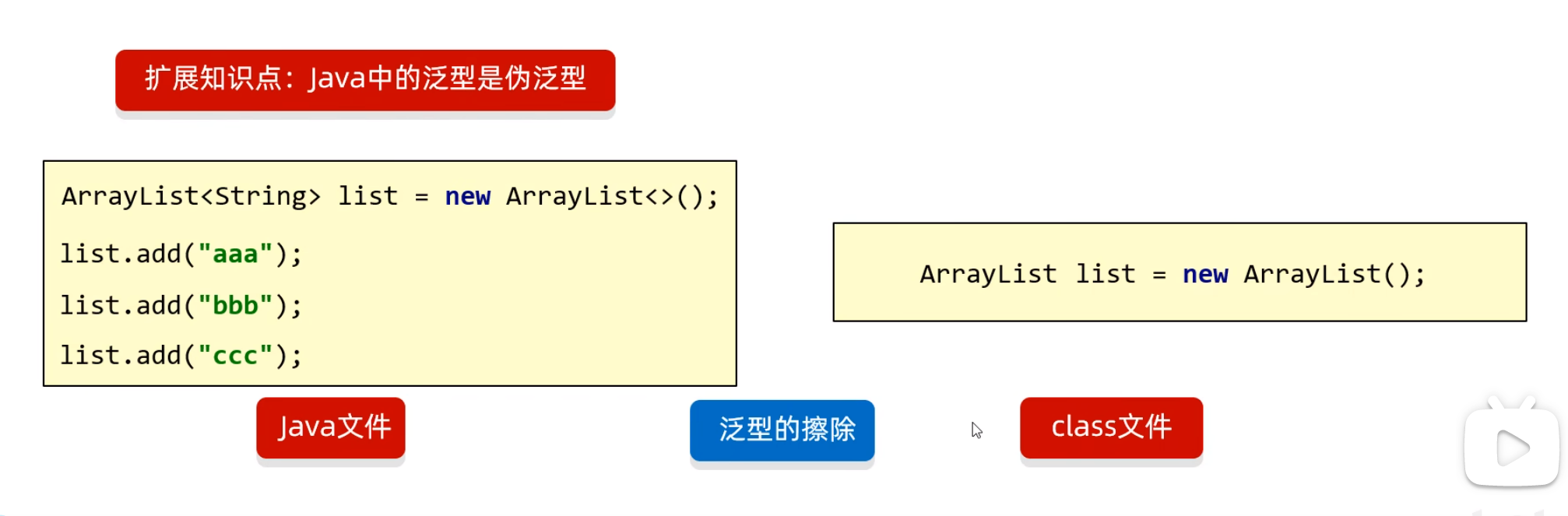

泛型类

(以下所写的泛型类,实际上也是多数集合源码的体现)
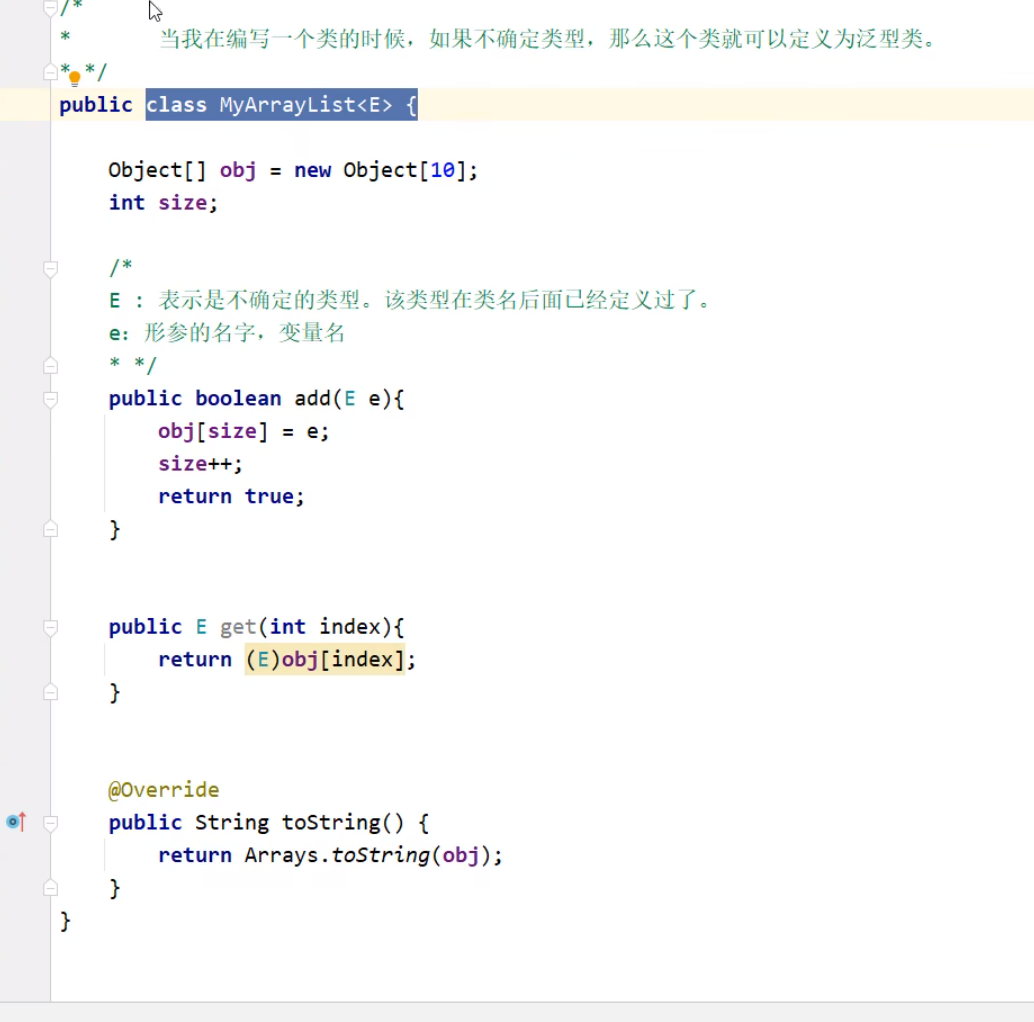
java所采取的是伪泛型机制,在编译期间将会进行泛型擦除,即
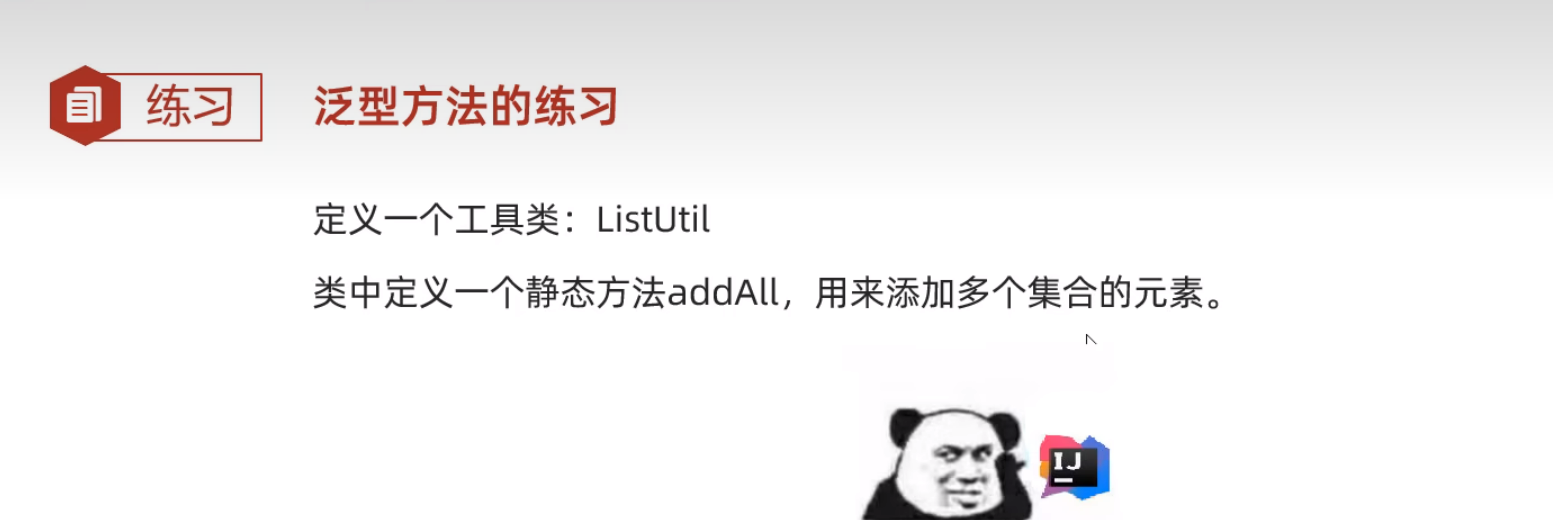
泛型方法


package com.an.a;
import java.util.ArrayList;
//定义工具类,里面定义静态方法addAll可以添加集合多种类型的元素
class ListUtil{
//私有化构造方法
private ListUtil(){};
//addAlll:参数1:集合 参数2:要添加的元素
public static <T> void addAll(ArrayList<T> list,T...t){//变长参数(t表示数组名)
for (int i = 0; i < t.length; i++) {
list.add(t[i]);
}
}
}
public class ListUtilTest {
public static void main(String[] args) {
ArrayList<Integer> list=new ArrayList<>();
ListUtil.addAll(list,2,3,4,5,6,7,87,0);
System.out.println(list);//[2, 3, 4, 5, 6, 7, 87, 0]
}
}
泛型接口

泛型的继承和通配符
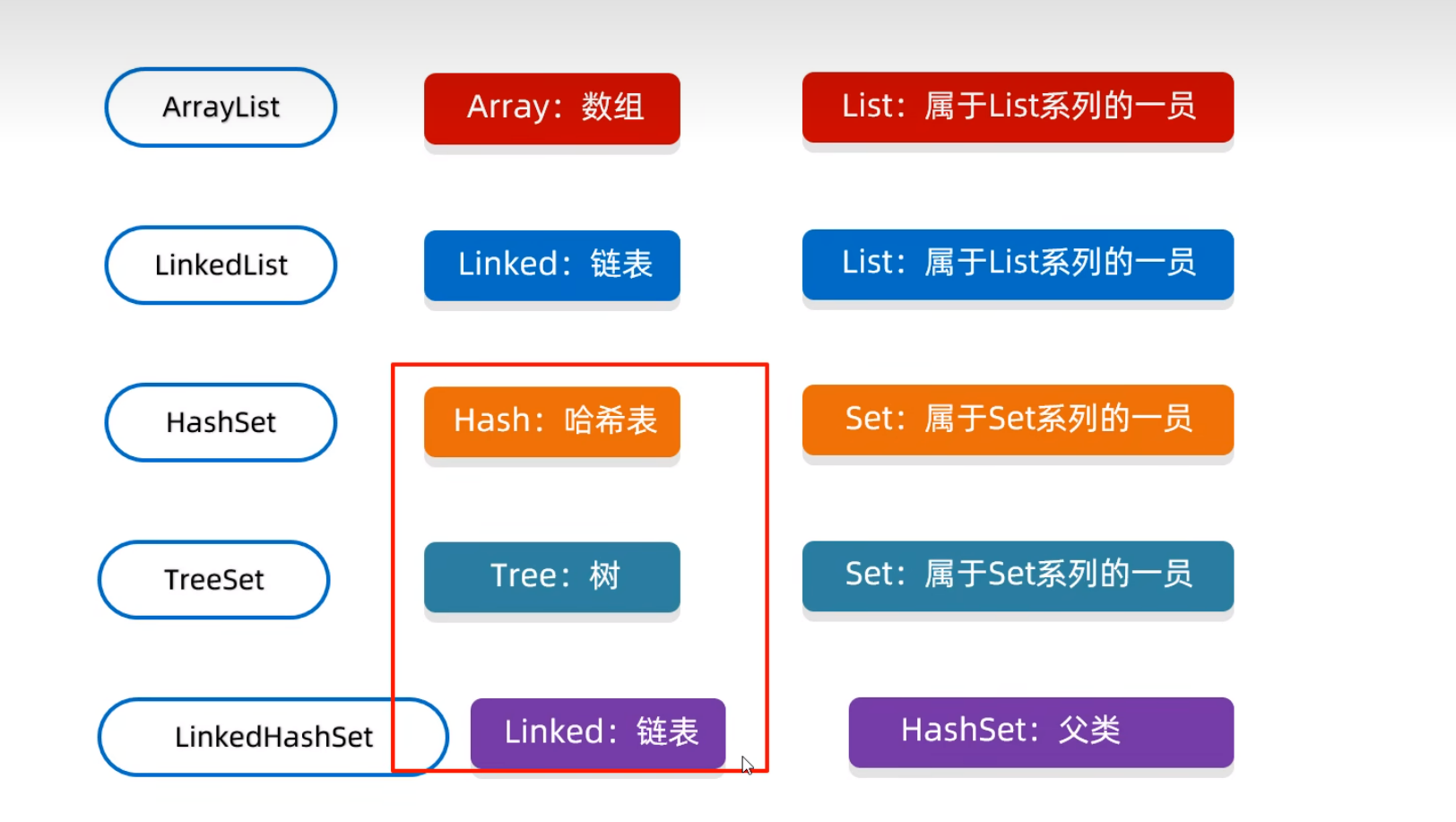
ArrayList
泛型不具备继承性,但是数据具有继承性
package com.an.a;
import java.util.ArrayList;
class Person{
}
class Student extends Person{
}
public class test5 {
public static void main(String[] args) {
ArrayList<Person> list1 =new ArrayList<>();
ArrayList<Student> list2 =new ArrayList<>();
show(list1);
show(list2);
}
public static void show(ArrayList<Person> list){
}
}
此时进行引用传递,发现只有相同类型且相同泛型的对象才能通过引用传递,说明泛型不具备继承性
- 应用场景
如果我们在定义类 方法 接口 的时候,如果类型不确定,就可以定义成泛型类 泛型方法 泛型接口
如果类型不知道,但是知道只能传递某个继承体系,就可以使用泛型通配符
泛型通配符:可以限定类型的范围


- 综合练习(以后完善)
![]()
public
Vector在java1.2的时候已经被淘汰
ArrayList: Array底层的数据结构:数组 List:属于List的一员
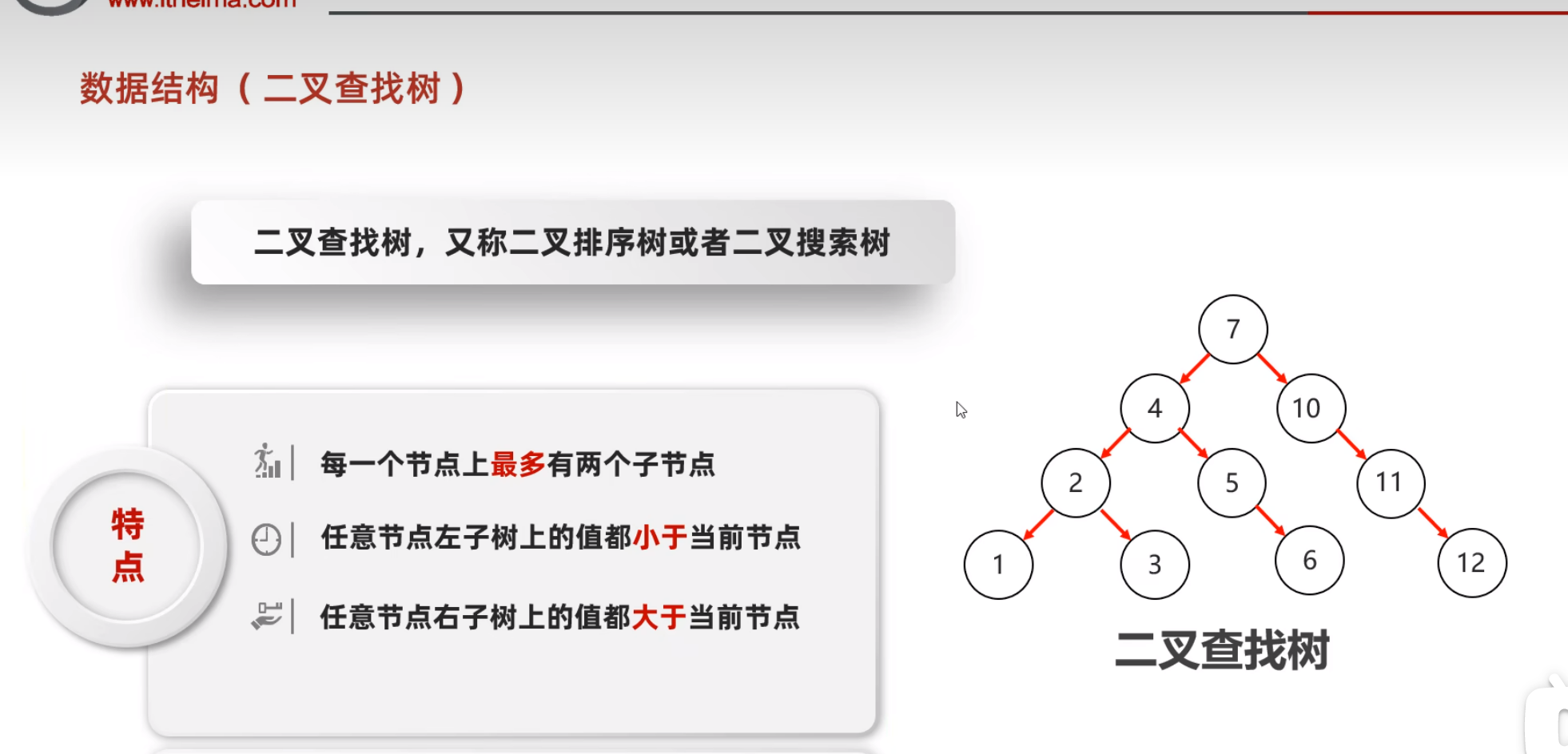
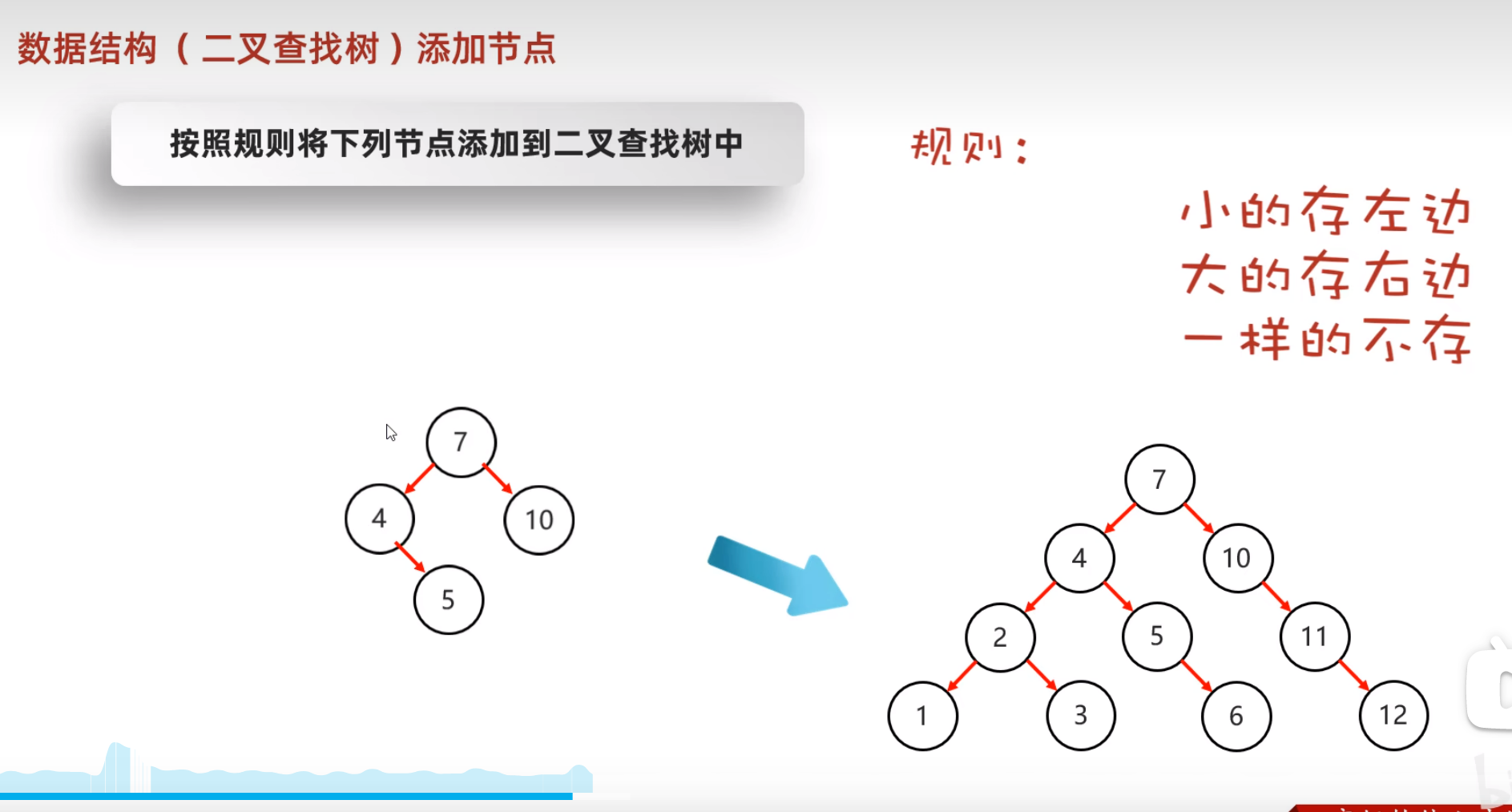
查找和储存时的规律一样,依次和根节点进行比较
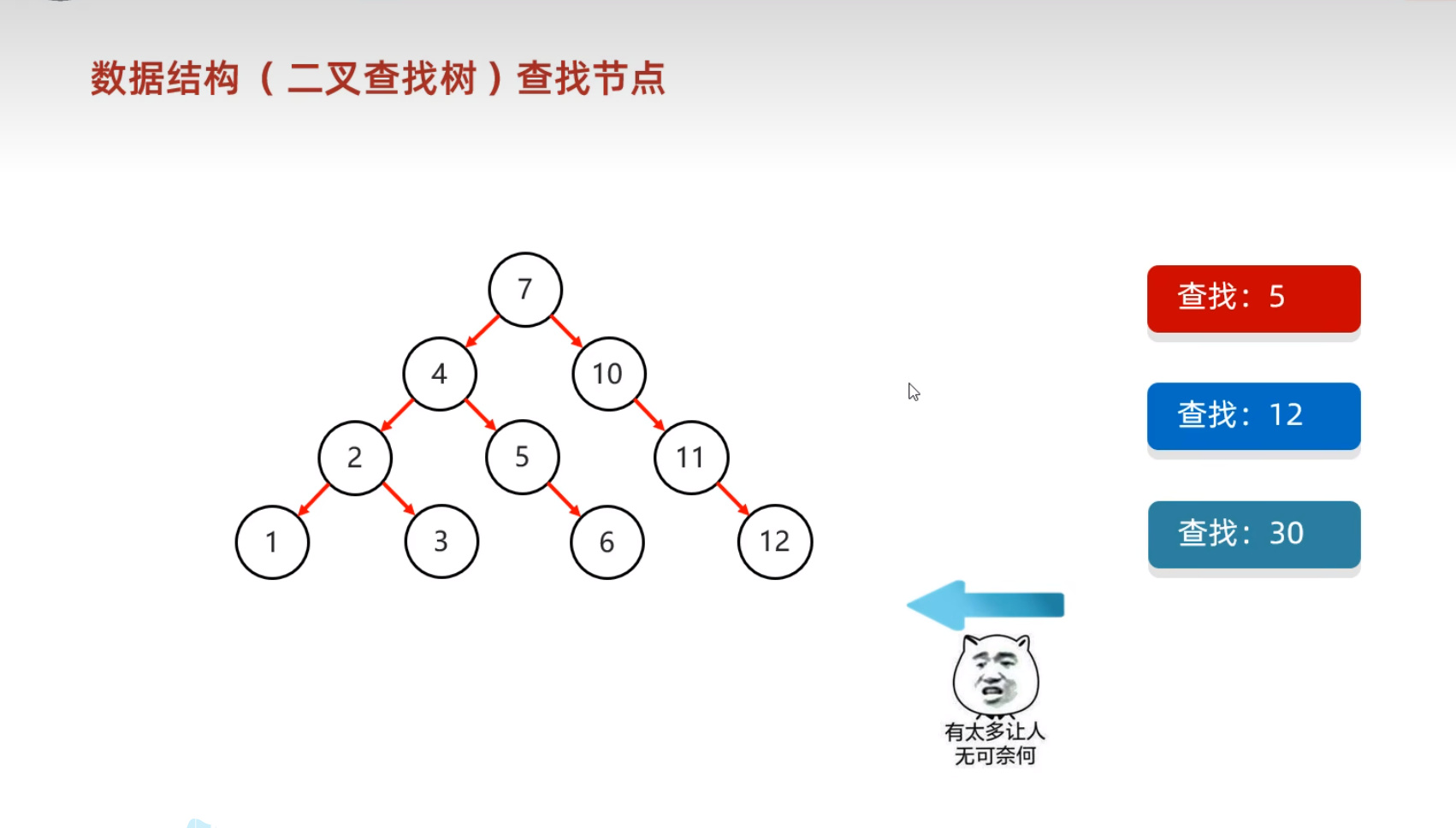
- 二叉树的遍历方式
![]()
![]()
![]()
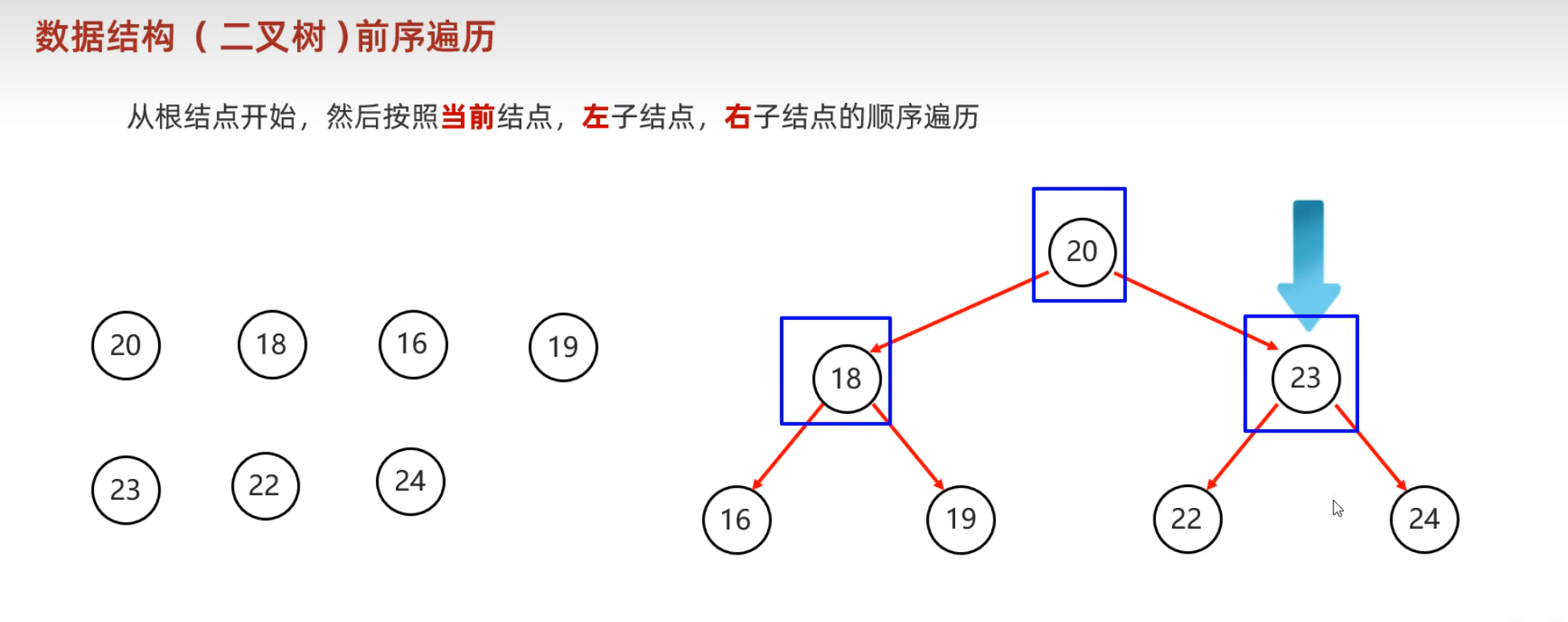

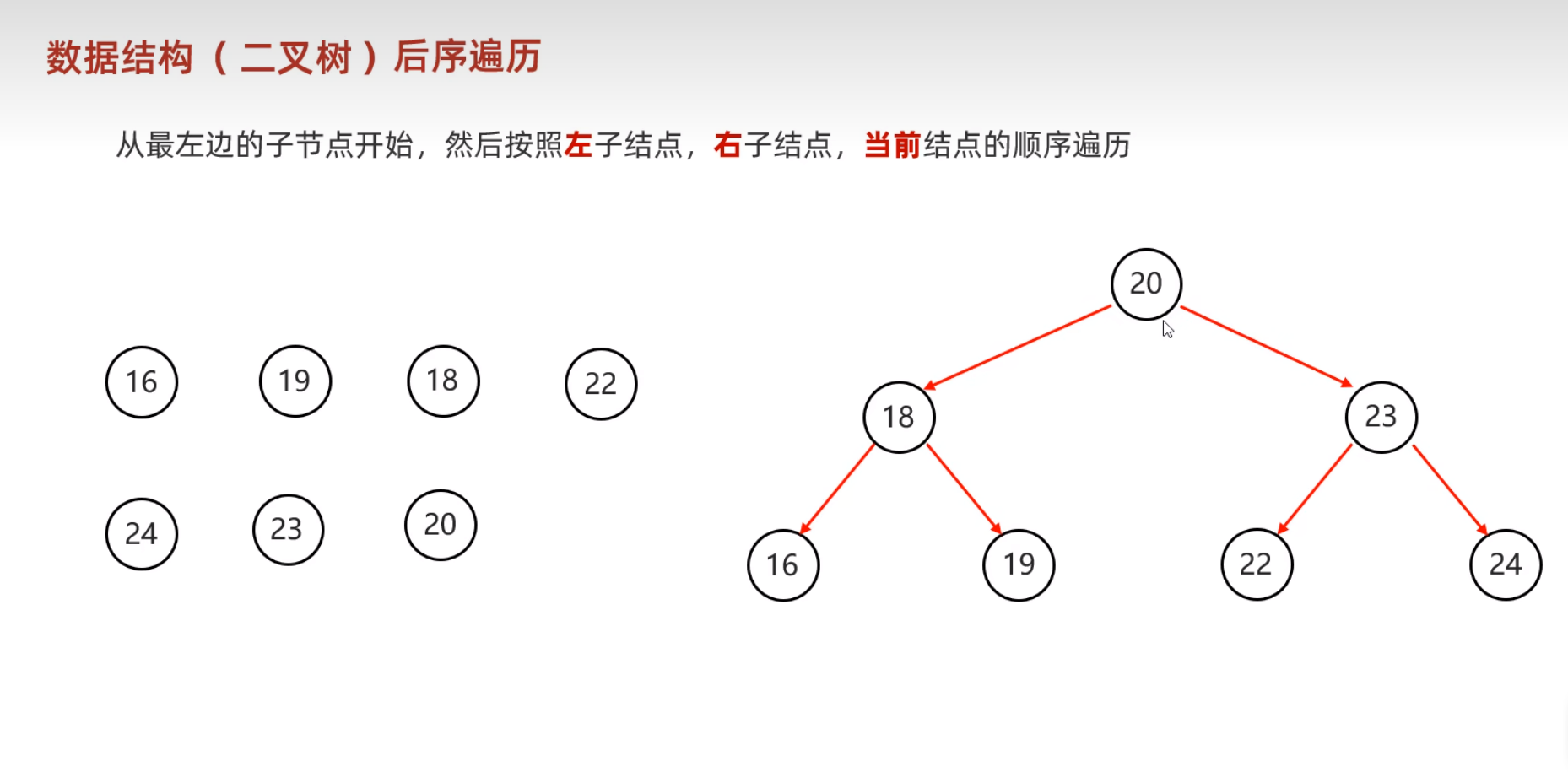
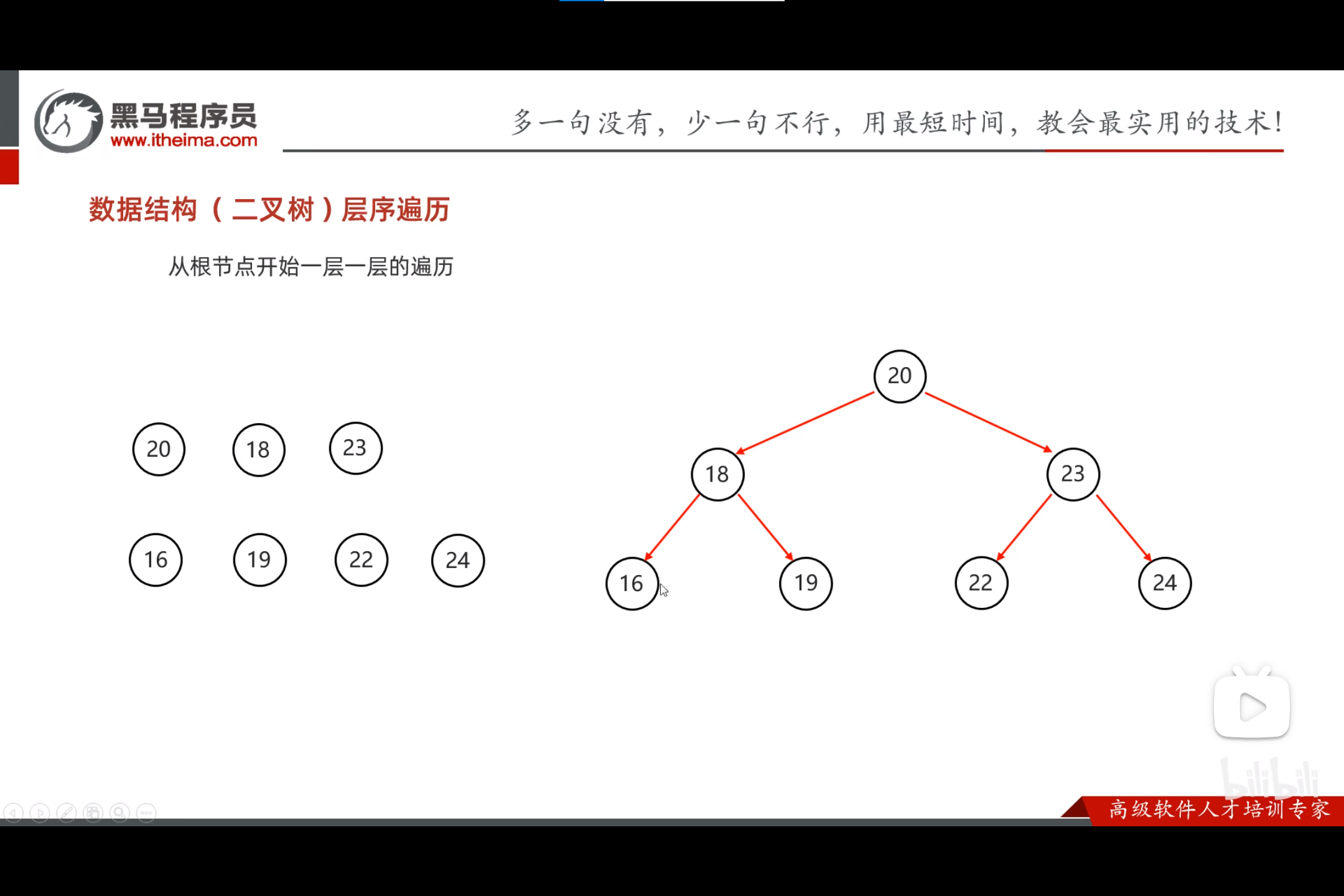

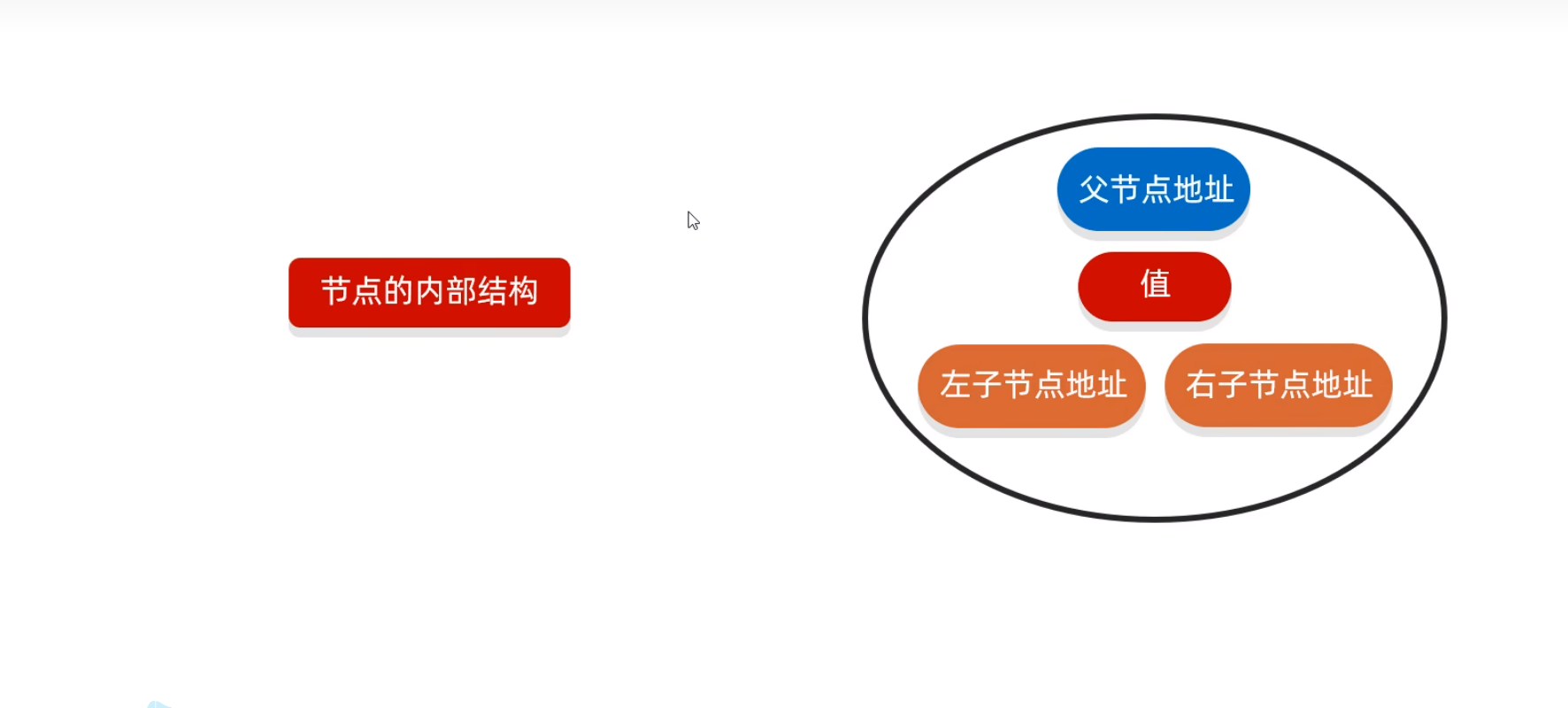
二叉查找树的弊端
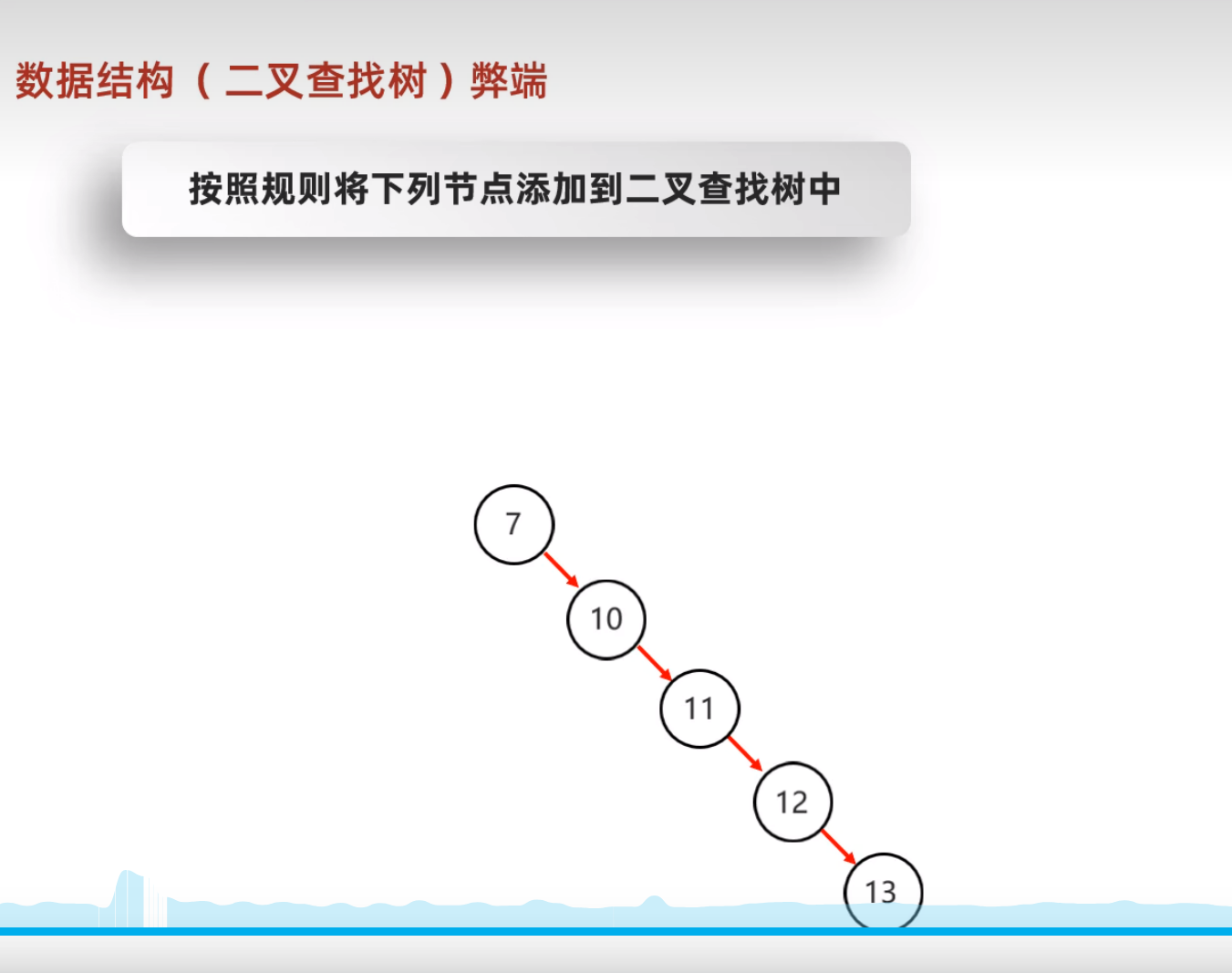
如果添加的数据使得根节点的左右子树极其不对称,将会导致查询效率太低
平衡二叉树
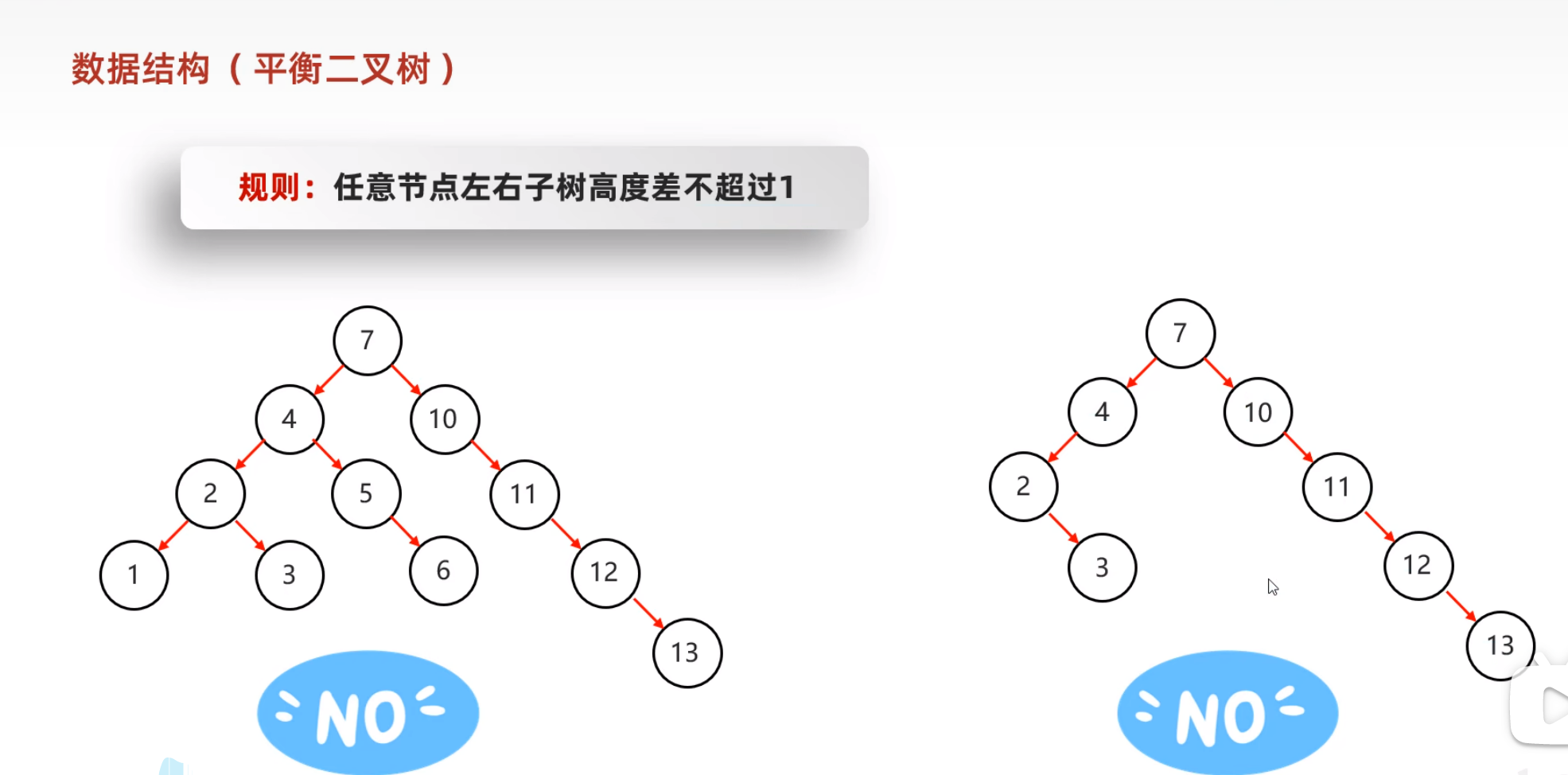
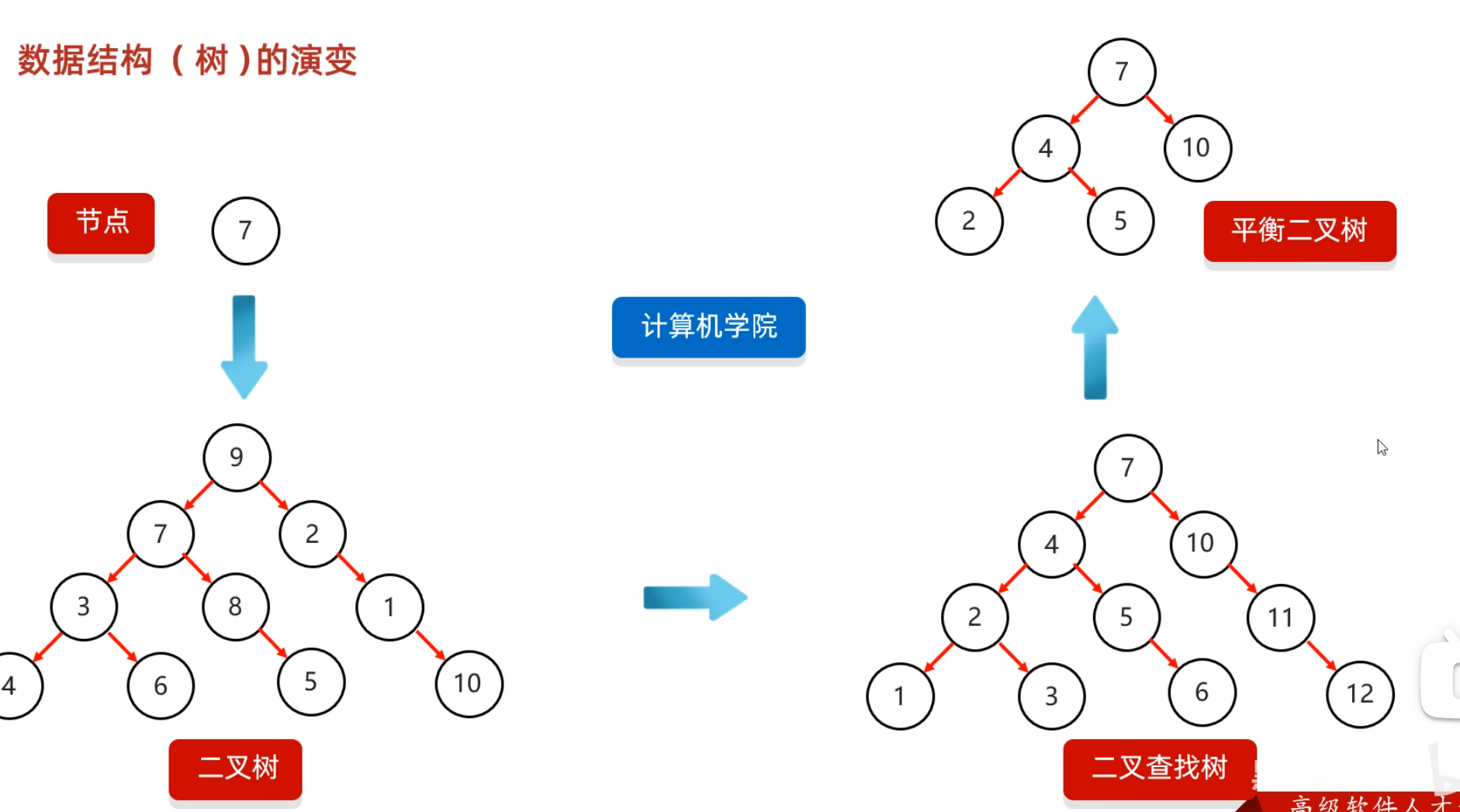
平衡二叉树保持平衡的旋转机制
Set系列集合

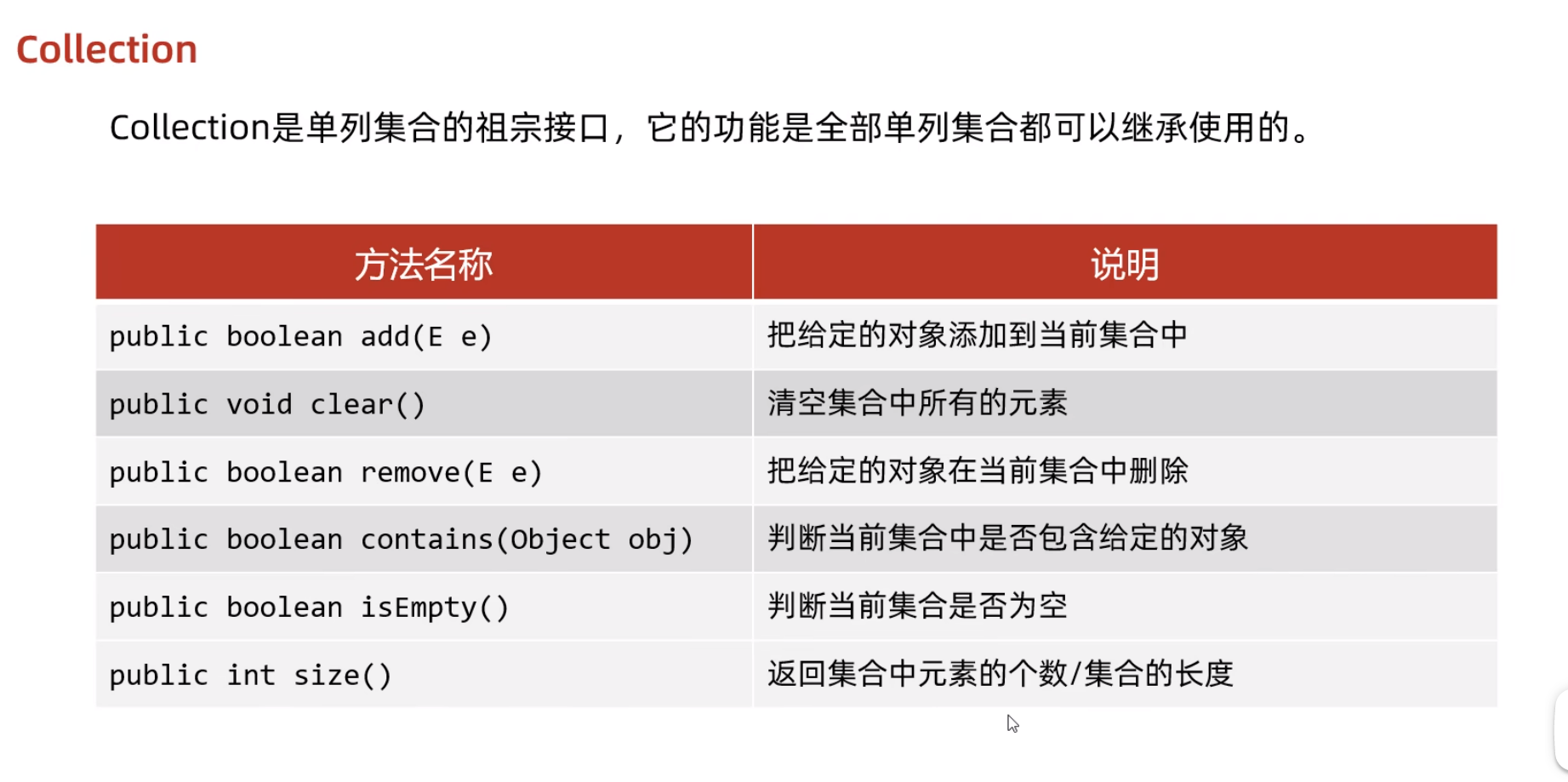
- 回顾Collection的方法
![]()
由于set系列的集合没有索引,所以set里面的方法和collection里面的方法基本相同
package com.an.a;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
//测试set里面的一些方法的使用
public class SetTest {
public static void main(String[] args) {
/*
利用Set系列的集合,添加字符串并使用多种方式遍历
1.迭代器
2.增强for
*/
//1.创建一个Set的集合并添加元素:去重
Set<String> s=new HashSet<>();//Set为接口,使用多态实例化
//2.添加元素:当该元素为第一次添加将会添加成功 返回true
//当该元素为第二次添加将会添加失败 返回false
boolean a = s.add("hello");
boolean b = s.add("hello");
System.out.println(a);//true
System.out.println(b);//false
System.out.println("--------------------------------");
//2.打印集合:无序
Set<String>s2=new HashSet<>();
s2.add("张三");
s2.add("李四");
s2.add("王五");
System.out.println(s2);//[李四, 张三, 王五]:存和取的顺序不一样
//3.没有索引
//4.遍历
//迭代器遍历
Iterator<String> it = s2.iterator();//获取迭代器
while(it.hasNext()){
System.out.println(it.next());
}
//增强for遍历
for (String s1 : s2) {
System.out.println(s1);
}
}
}

HashSet
HashSet的方法和Collection的方法一样
HashSet的底层实现原理

哈希值:对象的整数表现形式




哈希值特点演示
package Test;
import java.util.Objects;
//Hash值是根据hashCode方法计算出来的整数
//hashCode是定义在Object中的方法,如果没有被从写,默认以对象的地址值进行计算
//哈希值是对象的整数表现形式
class Person{
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Person{name = " + name + ", age = " + age + "}";
}
}
public class HashTest {
public static void main(String[] args) {
//哈希值的特点
/*
1.如果没有重写hashCode,不同对象计算的哈希值是不同的
2.如果重写了hashCode,不同对象只要属性相同,计算出的哈希值就是一样的
3.在小部分情况下,不同属性或者不同地址计算出来的哈希值也有可能相同(哈希碰撞)
*/
//创建对象
Person pr1=new Person("张三",23);
Person pr2=new Person("张三",23);
//以地址值进行计算,相同的对象不同的地址哈希值不同
System.out.println(pr1.hashCode());//460141958
System.out.println(pr2.hashCode());//1163157884
//当我们覆写hashCode方法使其按照属性值计算哈希值
//覆写hashCode只要属性值相同即使地址不同哈希值也是相同的
System.out.println(pr1.hashCode());//24022543
System.out.println(pr2.hashCode());//24022543
//3.在少部分的情况下属性值不同或者地址值不同哈希值有可能相同
//字符串已经覆写了hashCode方法,使其按照字符串来计算哈希值
System.out.println("abc".hashCode());//96354
System.out.println("acD".hashCode());//96354
}
}
HashSet类是根据对象的哈希值来判断,是否是同一个对象的
package Test;
import java.util.HashSet;
import java.util.Objects;
class Stduent{
private String name;
private int age;
public Stduent() {
}
public Stduent(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Stduent stduent = (Stduent) o;
return age == stduent.age && Objects.equals(name, stduent.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Stduent{name = " + name + ", age = " + age + "}";
}
}
public class HashSetTest {
public static void main(String[] args) {
Stduent st1=new Stduent("张三",23);
Stduent st2=new Stduent("李四",24);
Stduent st3=new Stduent("王五",25);
Stduent st4=new Stduent("张三",23);
HashSet<Stduent> ha=new HashSet<>();
//添加元素到集合中
//1.当没有重写hashCode,不同对象的哈希值都不同
//2.当重写hashCode,通过属性决定哈希值
System.out.println(ha.add(st1));//true
System.out.println(ha.add(st2));//true
System.out.println(ha.add(st3));//true
System.out.println(ha.add(st4));//true false(覆写hashCode将会通过属性确定哈希值,然后对对象去重)
}
}
LinkedHashSet
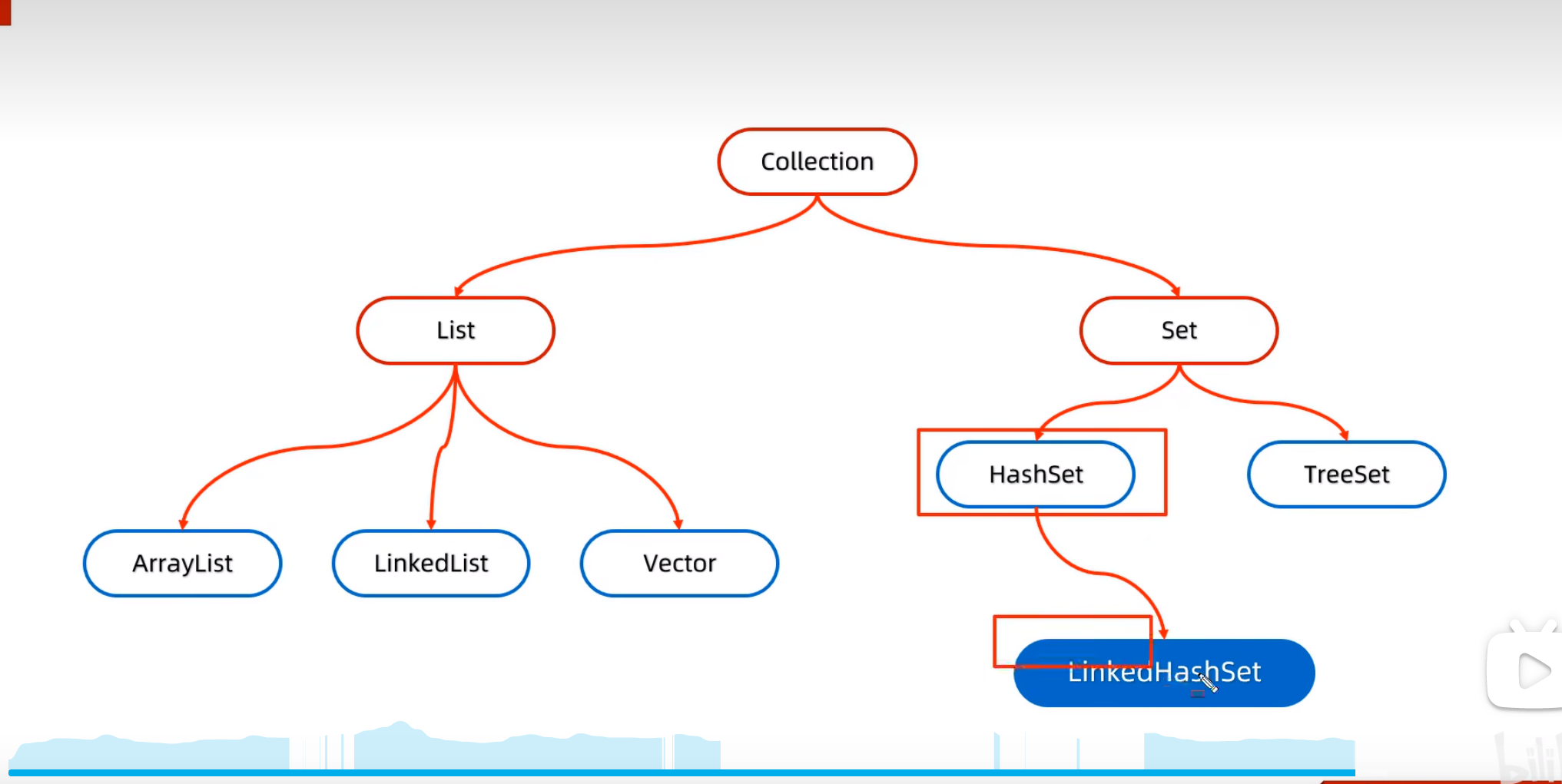
LindedHashSet底层原理

treeSet

默认将集合内的元素按从小到大进行排序
package Test;
import java.util.*;
//利用hashTree储存整数并进行排序
public class HashTreeTest {
public static void main(String[] args) {
TreeSet<Integer> hs=new TreeSet<>();
hs.add(3);
hs.add(1);
hs.add(2);
hs.add(5);
hs.add(4);
System.out.println(hs);//[1, 2, 3, 4, 5]
//迭代器遍历
final Iterator<Integer> it = hs.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//增强for遍历
for (Integer h : hs) {
System.out.println(h);
}
}
}

对于字符串的ascii码比较,第一个和第一个字符相比,第二个和第二个字符相比,直到比较出来了大小关系,然后后面的将不会再比较
treeSet的第一种排序规则
我们前面排序的,集合里面储存的数据所属的类,都是java官方写好的类,下面我们将使用自己写的类进行排序
按照之前一样的进行处理
package Test;
import java.util.*;
class Student1{
private String name;
private int age;
public Student1() {
}
public Student1(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student1{name = " + name + ", age = " + age + "}";
}
}
public class HashTreeTest {
public static void main(String[] args) {
TreeSet<Student1> ts = new TreeSet<>();
Student1 s1 = new Student1("zhangsan",23);
Student1 s2 = new Student1("lisi",24);
Student1 s3 = new Student1("wangwu",25);
//添加数据
ts.add(s1);
ts.add(s2);
ts.add(s3);
System.out.println(ts);
}
}
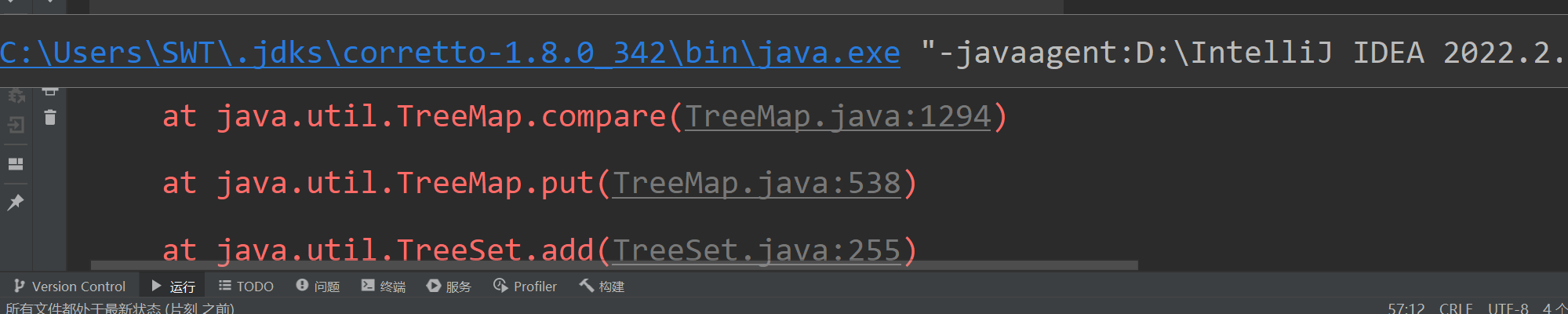
此代码将会出现异常ClassCastException,可以知道是因为我们没有实现Comprable接口(和使用sort方法的情况一样),
这是因为我们没有为我们的Student1类定义比较规则,而Integer String等类在内步已经实现了该接口,即已经指明了比较规则
package Test;
import java.util.*;
class Student1 implements Comparable<Student1>{
private String name;
private int age;
public Student1() {
}
public Student1(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student1{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Student1 o) {
return this.getAge()-o.getAge();
}
}
public class HashTreeTest {
public static void main(String[] args) {
TreeSet<Student1> ts = new TreeSet<>();
Student1 s1 = new Student1("zhangsan",23);
Student1 s2 = new Student1("lisi",24);
Student1 s3 = new Student1("wangwu",25);
//添加数据
ts.add(s1);
ts.add(s2);
ts.add(s3);
System.out.println(ts);
//[Student1{name = zhangsan, age = 23}, Student1{name = lisi, age = 24}, Student1{name = wangwu, age = 25}]
}
}
可以发现此时已经按照年龄进行了排序
结合红黑树的特性,然后调用compareTo进行具体的排序的具体过程以后具体整理
TreeSet的第二种比较方式


当默认比较规则不能满足我们的需求,就可以使用自定义的第二种排序规制
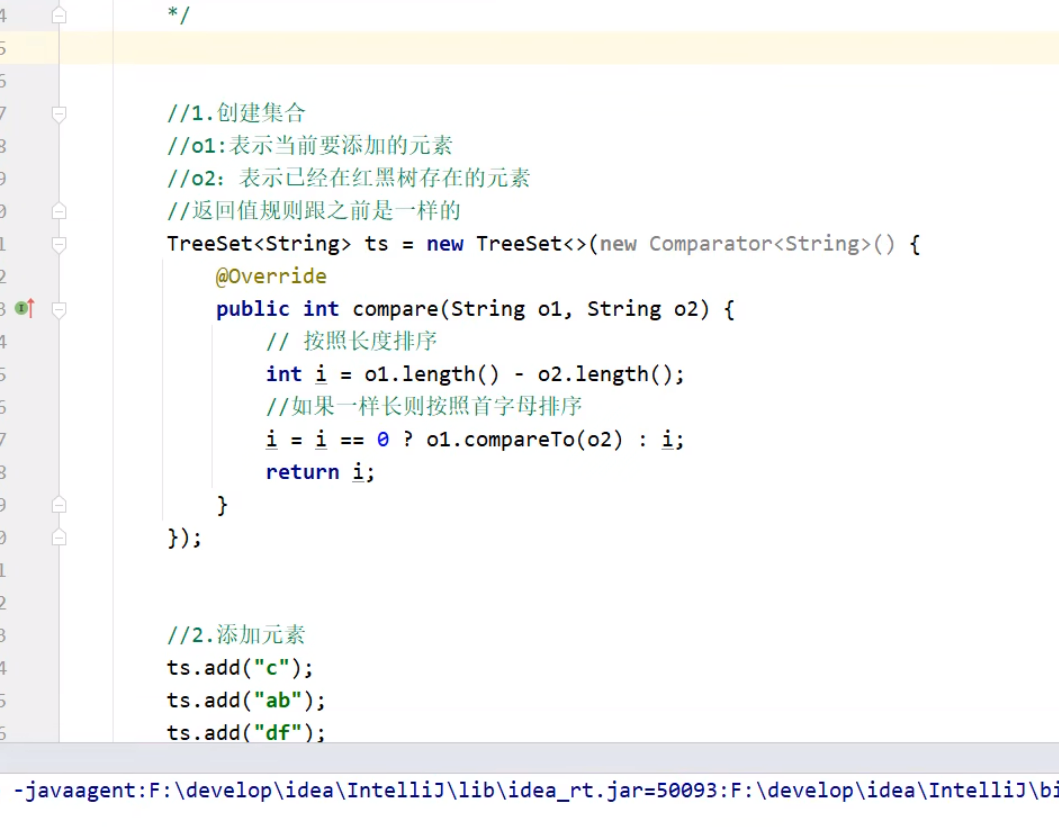
- 综合练习
![]()
![]()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号