LSH局部敏感哈希算法在计算相似度方面的应用
在推荐系统中,计算人与人之间或者物与物之间的相似度是再平常不过的事了,不过由于在实际的业务场景中,往往人或者物的数据量巨大,相似度的计算任务变得异常巨大,时间复杂度为n的平方,对时间和硬件的要求很高,傻傻地把数据直接怼到spark往往无法获得结果。
在一次计算“感兴趣的人”的业务需求中,我就碰到了这样的需求,我是这样做的:利用ALS生成的特征向量,把ALS生成的item向量取出来,通过局部敏感哈希算法(LSH)来计算item向量的相似度,大大降低了计算的时间。
ALS算法
用户对物品没有明确的反馈,需要通过用户的相关行为去推测其对物品的偏好,比如说用户在平台听了一首歌表示对这首歌有一定程度的偏好,用户没有听某首歌也有可能是没有看到它,并不代表用户不喜欢这个item。在实际的业务中,工程师拿到的评分数据矩阵是非常稀疏的,毕竟用户不可能对所有的item都有明确的偏好反馈,所以这个时候就需要一个能预测偏好值的打分方法,从而达到推荐的目的。

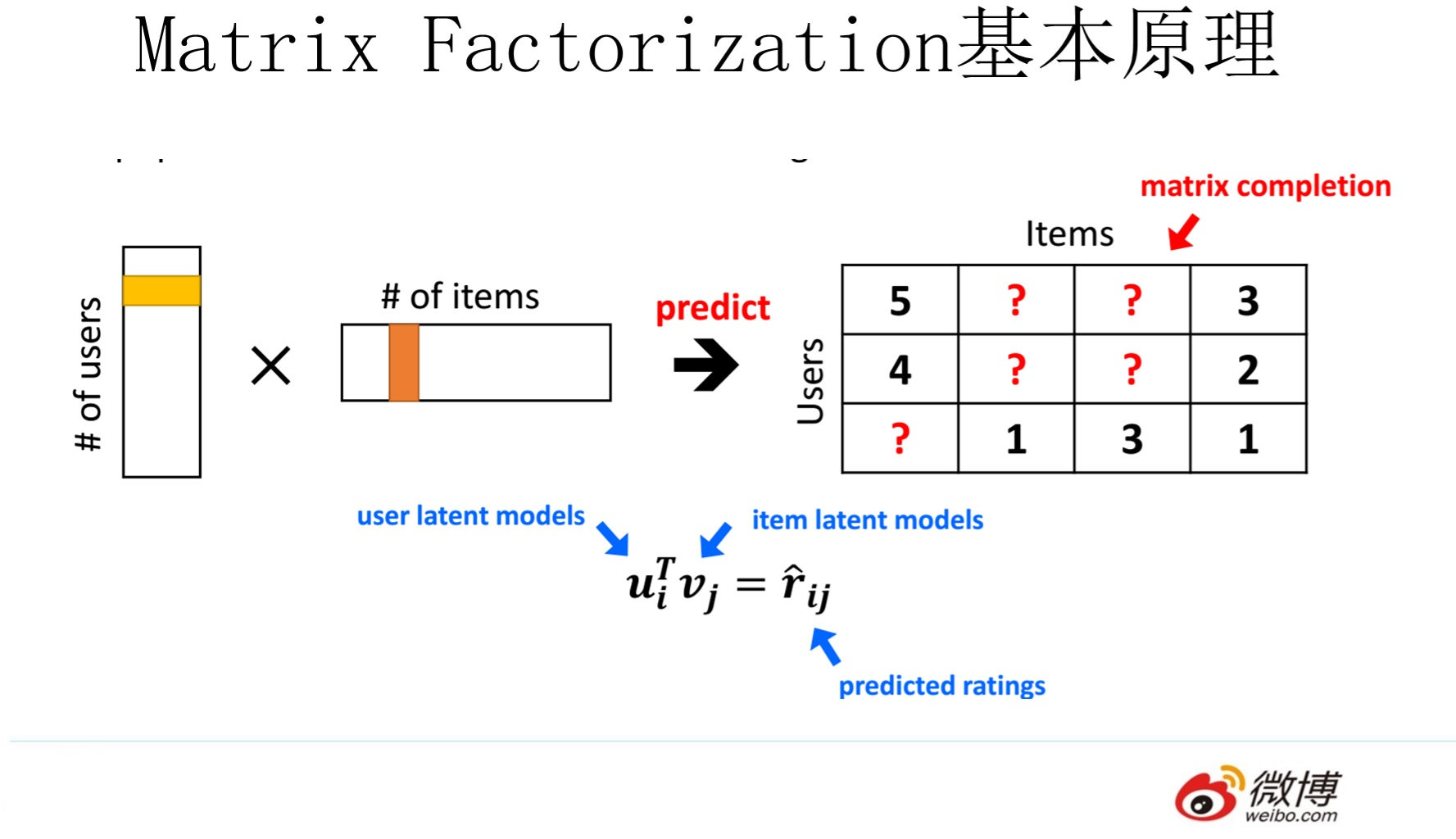
评分矩阵 -> 低维隐含因子矩阵
R -> P, Q
R(m*n) 评分矩阵
P(m*k) 用户对物品隐含特征的偏好矩阵userFactors
Q(k*n) 物品所包含的隐含特征矩阵itemFactors
随机初始化P和Q,先固定P求解Q,然后固定Q求解P,不停地迭代下去,求解的优化方法是最小二乘法,同时在优化的过程中还需要增加正则化系数λ防止出现过拟合,迭代到直到最小二乘法的均方根误差(Root MeanSquared Error,RMSE)达到收敛的标准,交替最小二乘法的名字就是这么得来的。
在 MLlib 中的实现类为org.apache.spark.mllib.recommendation.ALS.scala,其有如下的参数:
numUserBlocks:数据分区个数,是用于并行化计算的分块个数 (设置为-1,为自动配置)。numProductBlocks:数据分区的个数,是用于并行化计算的分块个数 (设置为-1,为自动配置)rank:设定特征矩阵的秩,也就是隐含特征的数量,默认是10,一般隐含特征的数量远远小于m和niterations:是迭代的次数,推荐值:10-20。lambda(spark ml对应参数是RegParam):惩罚函数的因数,是ALS的正则化参数,推荐值:0.01implicitPrefs:设置是否使用隐式反馈alpha:置信度系数,表示根据用户对物品的信任度,对于没有反馈的项赋予较小的权重对于有明确反馈的赋予更大的权重seed:随机数种子
缺点:
- ALS是一个离线的算法
- 无法对新加入的用户推荐,存在冷启动的问题
- 隐式反馈有很大的噪声,很难度量,比如用户由于睡着了,歌曲列表的歌循环了很多次,并不代表他对这些歌曲都有明显的偏好
局部敏感哈希原理
局部敏感哈希的思路是基于一个假设:如果原有的向量在现有的空间内是相似的,那么经过映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。具体的操作是使用一系列的LSH簇(LSH family)将特征向量通过hash function映射变换后,原始的数据会落入到不同的桶(buckets)中,基于原有的假设原来空间相邻的点更有可能会落入到同一个hash桶中,不相邻的点不太可能落入同一个桶中。通过建立了哈希表的这种方式,O(1)的时间复杂度有了可能。
LSH family
- 汉明距离:两个字符串对应位置的不同字符的个数
- 欧式距离
- Jaccard距离
Spark中几种不同的Hash实现方式
决定使用什么LSH family取决于工程师拿到的数据,比如在下文给出的示例代码是关于计算有相似收藏作品喜好的用户,按用户汇总每个用户的收藏作品得到的是一个一个的列表,那么比较两个用户收藏列表的相似性就只能用到Jaccard距离,对应基于Jaccard距离的MinHash估计;如果是计算人与人之间的相似度,给出的数据是身高、体重、年龄等指标,那么就可以用欧式距离来衡量两个人的相似度,对应BucketedRandomProjectionLSH估计。
- 基于Jaccard距离的MinHash估计
本文的案例是基于Jaccard距离的LSH估计 - 基于欧氏距离的BucketedRandomProjectionLSH估计
参考:SparkMl-BucketedRandomProjectionLSH(欧几里德距离度量-局部敏感哈希) - divenwu的个人空间 - OSCHINA - 中文开源技术交流社区
参考代码:
package com.fiveonevv.app.core
import com.fiveonevv.app.util.TimeUtil
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel, MinHashLSH, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.DataTypes
/**
* @author Li Bin
* @since 2019/9/19 10:00
* @version 感兴趣的人3.0,局部感知哈希算法(LSH)计算获得与用户具有相似收藏喜好、相似关注喜好的用户
*/
object LocalSensitiveHashingFindSimilarPeople {
/**
* @param avWorkSize 收藏的作品总数
* @return 相似收藏作品喜好的用户
*/
def lshToFindSimilarCollection(sparkSession: SparkSession, avWorkSize: Int): DataFrame = {
// 用户收藏作品id列表
val userCollection = sparkSession.sql("""WITH a AS
|(SELECT userid, CAST(avid AS STRING) avid FROM dwd_vvmusic_all.c_works_space_user_av_collect)
|SELECT a.userid userid,
|concat_ws(' ', collect_set(avid)) collection,
|size(collect_set(avid)) collect_cnt FROM a GROUP BY a.userid""".stripMargin)
.where("collection <> '' ")
// 将用户的收藏作品id视为一段文本,转为01向量的形式
val tokenizer = new Tokenizer().setInputCol("collection").setOutputCol("words")
val wordsDf = tokenizer.transform(userCollection)
val vocabSize = 2000000
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(vocabSize) // 词汇表的大小默认是2的18次方(262144),而用户收藏的不同作品数量超过了100W,词汇表必须大于这个数量
.setMinDF(1) // 规定必须出现在词汇表中的词汇的最小个数,默认为1
.fit(wordsDf)
/**
* vectorizedDf返回四列:
* userid
* collection(用户收藏的内容)
* words(用户收藏的内容列表的形式)
* features(转换后的特征)
*/
val vectorizedDf = cvModel.transform(wordsDf)
// 拟合LSH模型
val mh = new MinHashLSH()
.setNumHashTables(3)
.setInputCol("features")
.setOutputCol("hashValues")
val model = mh.fit(vectorizedDf)
// 运行近似相似连接,找到同一个数据集中有相似收藏内容的用户组合
model.approxSimilarityJoin(vectorizedDf,vectorizedDf,0.9).toDF()
.selectExpr("datasetA.userid userid", "datasetB.userid target_userid", "1-distCol AS distCol")
.where("userid <> target_userid")
}
/**
* 用户的关注人数区间分布广,拿关注人数不足10个的用户和关注人数超过1000的用户计算相似度意义不大,并且需要大量的计算资源。
* 所以折中的方法是可以先按照关注数量对用户分组,比如关注人数在(20,30]的用户之间计算相似程度
* @return 相似关注喜好的用户
* @see 关于词汇表的理解见文章:http://dblab.xmu.edu.cn/blog/1452-2/
*/
def lshToFindSimilarFollow(sparkSession: SparkSession): DataFrame = {
// 用户的关注列表
val userFollow = sparkSession.sql("""WITH a AS
|(SELECT a.userid,CAST(b.target AS STRING) target
|FROM dws_kylin.dim_user_data a,dwd_vvmusic_all.s_social_relation b
|WHERE a.userid=b.userid
|AND a.active_thirty > 2
|AND b.relation_type IN (1,2))
|SELECT a.userid,
|concat_ws(' ', collect_set(target)) targets,
|size(collect_set(target)) follow_cnt FROM a GROUP BY a.userid""".stripMargin)
.where("follow_cnt < 1000") // 个人关注的人数小于1000个
.withColumn("follow_cnt_section", floor(col("follow_cnt") / 10)) // 关注人数区间
val tokenizer = new Tokenizer().setInputCol("targets").setOutputCol("words")
val wordsDf = tokenizer.transform(userFollow)
val isNoneZeroVector = udf({v: Vector => v.numNonzeros > 0}, DataTypes.BooleanType)
val vocabSize = 10000 // 词汇表中仅仅考虑用户出现频率排名前1,000,000的用户
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(vocabSize) // 词汇表的大小默认是2的18次方(262144),而用户收藏的不同作品数量超过了100W,词汇表必须大于这个数量
.setMinDF(10) // 用户必须至少出现在10个用户的关注列表里面,比如词汇表中有“a”,“b”,“c”三个词,且这三个词都在2个文档中出现过
.fit(wordsDf)
val vectorizedDf = cvModel
.transform(wordsDf)
.filter(isNoneZeroVector(col("features")))
.select("userid","features")
// 拟合LSH模型
val mh = new MinHashLSH()
.setNumHashTables(3)
.setInputCol("features")
.setOutputCol("hashValues")
val model = mh.fit(vectorizedDf)
// 运行近似相似连接,找到同一个数据集中有相似关注喜好的用户组合
model.approxSimilarityJoin(vectorizedDf,vectorizedDf,0.01).toDF()
.selectExpr("datasetA.userid userid", "datasetB.userid target_userid", "1-distCol AS distCol")
.where("userid <> target_userid")
.withColumn("rank",row_number().over(Window.partitionBy("userid").orderBy(desc("distCol"))))
.where("rank<=100")
.repartition(10)
}
/**
* 相似的录歌喜好
*
* @note 根据用户最近一个月的录歌记录
*/
def lshToFindSimilarRecord(sparkSession: SparkSession, dt: String): DataFrame = {
val dateBeforeOneMonth = TimeUtil
.getBeforeFormatDay(dt, "yyyyMMdd", 30, "yyyyMMdd")
// 用户的录歌数据
val userRecord = sparkSession.sql(
"""WITH a AS
|(SELECT DISTINCT record_user userid,cast(song_id AS STRING) song_id FROM dws_kylin.fact_w_record_song_daily_data WHERE dt>=""".stripMargin + dateBeforeOneMonth + """)
|SELECT userid,
|concat_ws(' ', collect_set(song_id)) song_ids,size(collect_set(song_id)) record_cnt FROM a GROUP BY a.userid""".stripMargin)
.where("record_cnt > 2") // 录歌数量大于N首
val tokenizer = new Tokenizer().setInputCol("song_ids").setOutputCol("words")
val wordsDf = tokenizer.transform(userRecord)
val vocabSize = 2000000
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(vocabSize)
.setMinDF(1)
.fit(wordsDf)
val vectorizedDf = cvModel.transform(wordsDf)
// 拟合LSH模型
val mh = new MinHashLSH()
.setNumHashTables(3)
.setInputCol("features")
.setOutputCol("hashValues")
val model = mh.fit(vectorizedDf)
model.approxSimilarityJoin(vectorizedDf,vectorizedDf,0.9).toDF()
.selectExpr("datasetA.userid userid", "datasetB.userid target_userid", "distCol")
.where("userid <> target_userid")
}
}
相关资料
- 大规模异常滥用检测:基于局部敏感哈希算法——来自Uber Engineering的实践 - 云+社区 - 腾讯云
- Locality Sensitive Hashing - ML Wiki
- Collaborative Filtering - Spark 2.2.0 Documentation
- ALS - org.apache.spark.mllib.recommendation.ALS
- 广告推荐算法之Item2Item框架 | Tony Wang's blogs
- SparkMl-BucketedRandomProjectionLSH(欧几里德距离度量-局部敏感哈希) - divenwu的个人空间 - OSCHINA - 中文开源技术交流社区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号