机器学习算法原理解析 - 集成
1. 集成学习(Ensemble learning)
基本思想:让机器学习效果更好,如果单个分类器表现的很好,那么为什么不适用多个分类器呢?
通过集成学习可以提高整体的泛化能力,但是这种提高是有条件的:
- (1)分类器之间应该有差异性;
- (2)每个分类器的精度必须大于0.5;
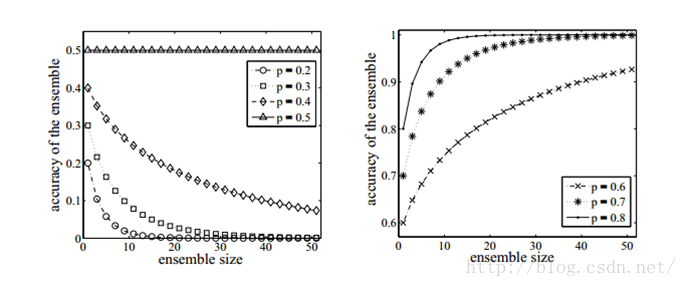
如果使用的分类器没有差异,那么集成起来的分类结果是没有变化的。如下图所示,分类器的精度p<0.5,随着集成规模的增加,分类精度不断下降;如果精度大于p>0.5,那么最终分类精度可以趋向于1.
接下来需要解决的问题是如何获取多个独立的分类器呢?
我们首先想到的是用不同的机器学习算法训练模型,比如决策树、KNN、神经网络、梯度下降、贝叶斯等等,但是这些分类器并不是独立的,它们会犯相同的错误,因为许多分类器是线性模型,它们最终的投票不会改进模型的预测结果。
既然不同的分类器不适用,那么可以尝试将数据分成几部分,每个部分的数据训练一个模型。这样做的优点是不容易出现过拟合,缺点是数据量不足导致训练出来的模型泛化能力较差。
下面介绍三种比较实用的方法Bagging、Boosting和Stacking。
- 分类器间存在强依赖关系,必须串行生成的序列化方法,代表为Boosting;
- 分类器间不存在强依赖关系,可同时生成的并行化方法,代表为Bagging;
1.1 Bagging算法(自举汇聚法)
1.1.1 概述
全称:boostrap aggregation(说白了就是并行训练一堆分类器)
简述:训练多个分类器取平均
![]()
Bagging是通过组合随机生成的训练集而改进分类的集成算法,是并行式集成学习最著名的代表。
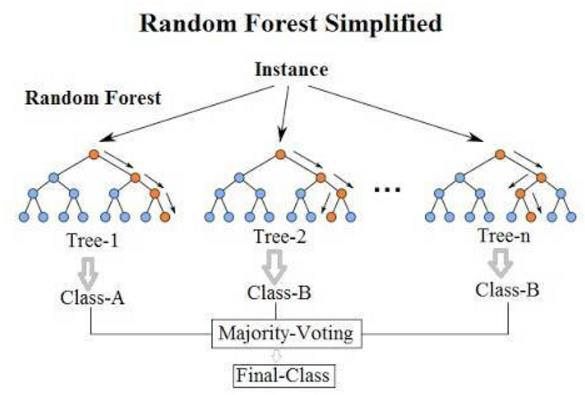
Bagging算法最典型的代表就是随机森林,如下图所示。随机森林,随机指数据采样随机、特征选择随机,森林指:很多个决策树并行放在一起。
Bagging基本流程:
- 采样出T个含m个训练样本的采样集Tree-n(n=1、2、3...n),采用自助采样法:给定包含m个样本的数据集Tree-n(n=1、2、3...n),我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样经过m次随机采样操作,我们得到含有m个样本的采样集,初始样本集有的样本在采样集里面出现多次,有的则从未出现。初始训练集中约有63.2%的样本出现在采样集中。重复操作,得到T个含m个训练样本的采样集Tree-n(n=1、2、3...n);
- 基于每个采样集Tree-n(n=1、2、3...n)训练出一个基学习器Class-n(n=1、2、3、4...n);
- 将这些基学习器进行结合(分类任务使用简单投票,回归任务使用简单平均法)。
1.1.2 随机森林优势
- 它能够处理很高纬度(feature很多)的数据,并且不用做特征选择;
- 在训练完后,它能够给出哪些feature比较重要;
- 容易做成并行化方法,速度比较快;
- 可以进行可视化展示,便于分析。
1.1.3 模型
- KNN模型:KNN就不太适合,因为很难去随机让泛化能力变强!
- 树模型:理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。
1.2 Boosting算法(提升法)
简述:从弱学习期开始加强,通过加权来进行训练
![]()
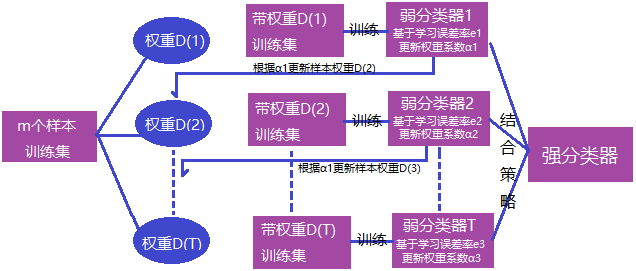
Boosting算法是一种可将弱学习算法提升成强学习器的算法。基本思想:不同的训练集是通过调整每个样本对应的权重实现的,不同的权重对应不同的样本分布,而这个权重为分类器不断增加对错分样本的重视程度。
Boosting算法的工作机制类似:
- 首先赋予每个训练样本相同的初始化权重,在此训练样本分布下训练出一个弱分类器;
- 利用该弱分类器的表现对每个训练样本的权重进行调整,分类错误的样本认为是分类困难样本,权重增加,反之权重降低,得到一个新的样本分布;
- 基于调整后的新样本分布下再训练一个新的弱分类器,并且更新样本权重,重复以上过程T次,得到T个弱分类器,最终将这T个弱分类器进行加权结合。
Boosting算法原理图:
Boosting算法典型代表:AdaBoost、Xgboost。AdaBoost算法特点如下:
- 每次迭代改变的是训练样本的分布,而不是重复采样;
- 样本分布的改变取决于样本是否被正确分类,是分类正确的样本权值低,还是分类错误的样本权值高(通常是边界附近的样本);
- 最终的结果是弱分类器(基分类器)的加权组合,权值表示该弱分类器的性能;
下面我们举一个简单的例子来看看AdaBoost的实现过程:
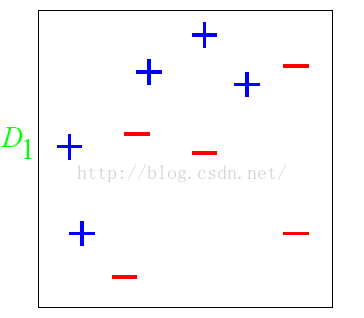
图中,“+”和“-”分别表示两种类别,在这个过程中,使用水平或者垂直的直线作为分类器。
第一步:根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1,其中画圈的样本表示被分错的,在右边的图中,比较大的“+”表示对该样本做了加权;

图中的ε1=0.3,表示的是错误率;α1=0.42,表示该分类器的权重,α1=1/2*ln(1- ε1/ ε1)
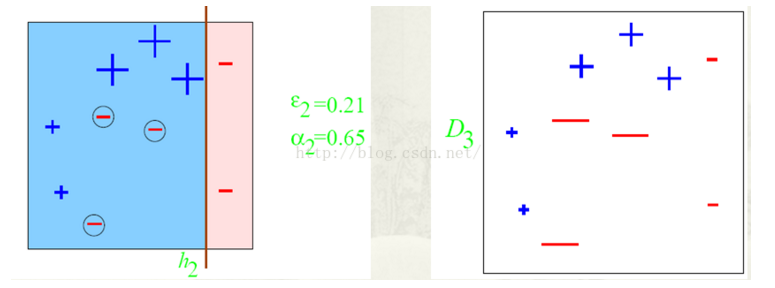
第二步:根据分类正确率,得到一个新的样本分布D3,一个子分类器h2;
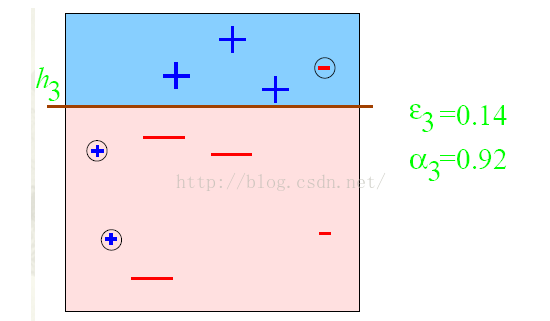
第三步:得到一个子分类器h3;
第四步:整合所有的子分类器;
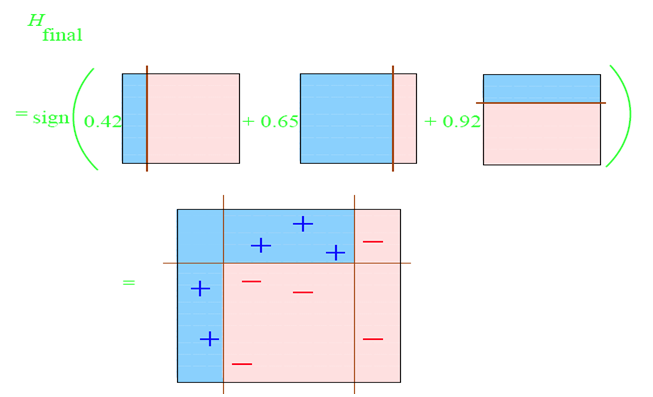
因此,可以得到整合的结果,从结果中看,即使简单的分类器,组合起来也能获得很好的分类效果。
AdaBoost算法的两个特性:(1)训练错误率的上界,随着迭代次数的增加,会逐渐下降;(2)即使训练次数很多,也不会出现过拟合现象
AdaBoost的算法流程如下:
步骤1. 首先,初始化数据的权值分布,每一个训练样本最开始时都被赋予相同的权值:1/N
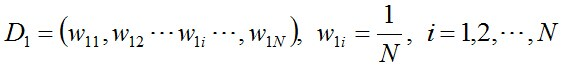
步骤2. 进行多轮迭代,用m=1,2,...M表示迭代的第多少轮
(a) 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阀值来设计基本分类器):
![]()
(b) 计算Gm(x)在训练数据集上的分类误差率
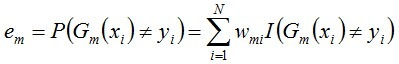
由上述式子可知,Gm(x)在训练数据集上的分类误差率em就是被Gm(x)误分类样本的权值之和。
(c) 计算Gm(x)的系数,am表示Gm(x)在最终分类器中重要程度(目的:得到基本分类器在最终分类器中所占的比重):
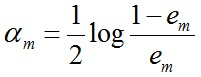
由上述式子可知,em<=1/2时,am>=0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
(d) 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
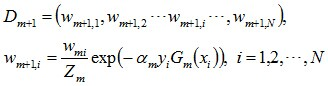
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦”于那些较难分的样本上。其中yi={+1,-1},Zm是规范化因子,使得Dm+1成为一个概率分布。
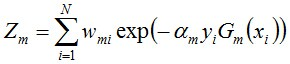
步骤3. 组合各个弱分类器
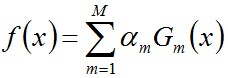
从而得到最终分类器,如下:
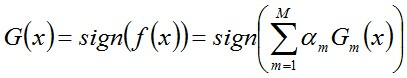
注:从偏差-方差分解的角度来看,Boosting主要关注降低偏差,因此Boosting能基于泛化能力相当弱的学习器构建出很强的集成。
1.3 Stacking算法(了解即可)
简述:聚合多个分类或回归模型(可以分阶段来做)
堆叠:很暴力,拿来一堆直接上(各种分类器都来了),可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练

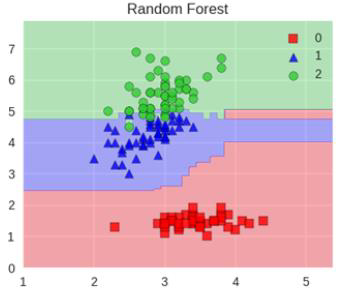
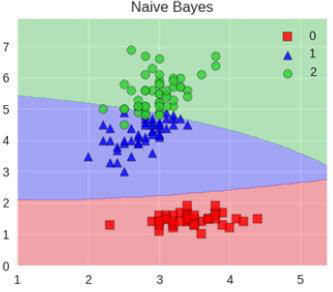
堆叠在一起确实能使得准确率提升,但是速度是个问题。
参考资料:
https://www.cnblogs.com/sddai/p/7647731.html
https://www.cnblogs.com/rgly/p/6519744.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号