Spark源码剖析 - 计算引擎
本章导读
RDD作为Spark对各种数据计算模型的统一抽象,被用于迭代计算过程以及任务输出结果的缓存读写。在所有MapReduce框架中,shuffle是连接map任务和reduce任务的桥梁。map任务的中间输出要作为reduce任务的输入,就必须经过shuffle,shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量。相比于Hadoop的MapReduce,我们可以看到Spark提供多种计算结果处理的方式,对shuffle过程进行了优化。
本章将继续以word count为例讲解。
1. 迭代计算
MapPartitionsRDD的iterator方法实际是父类RDD的iterator方法,见如下代码。如果分区任务初次执行,此时还没有缓存,所以会调用computeOrCheckpoint方法。
这里需要说一下iterator方法的容错处理过程:如果某个分区任务执行失败,但是其他分区任务执行成功,可以利用DAG重新调度。失败的分区任务将从检查点恢复状态,而那些执行成功的分区任务由于其执行结果已经缓存到存储体系,所以调用CacheManager的getOrCompute方法获取即可,不需要再次执行。

这里我们主要分析computeOrReadCheckpoint方法。computeOrReadCheckpoint在存在检查点时直接获取中间结果,否则需要调用compute继续计算,代码如下:

MapPartitionsRDD的compute方法实现如下:

MapPartitionsRDD的compute方法首先调用firstParent找到其父RDD,本例中MapPartitionsRDD的父RDD为RDD。
经过RDD管道中对iterator和computeOrReadCheckpoint的层层调用,最终到达HadoopRDD。查看此时的线程栈更直观,如图所示:

HadoopRDD的compute方法用来创建NextIterator的匿名内部类,然后将其封装为InterruptibleIterator,见代码如下:
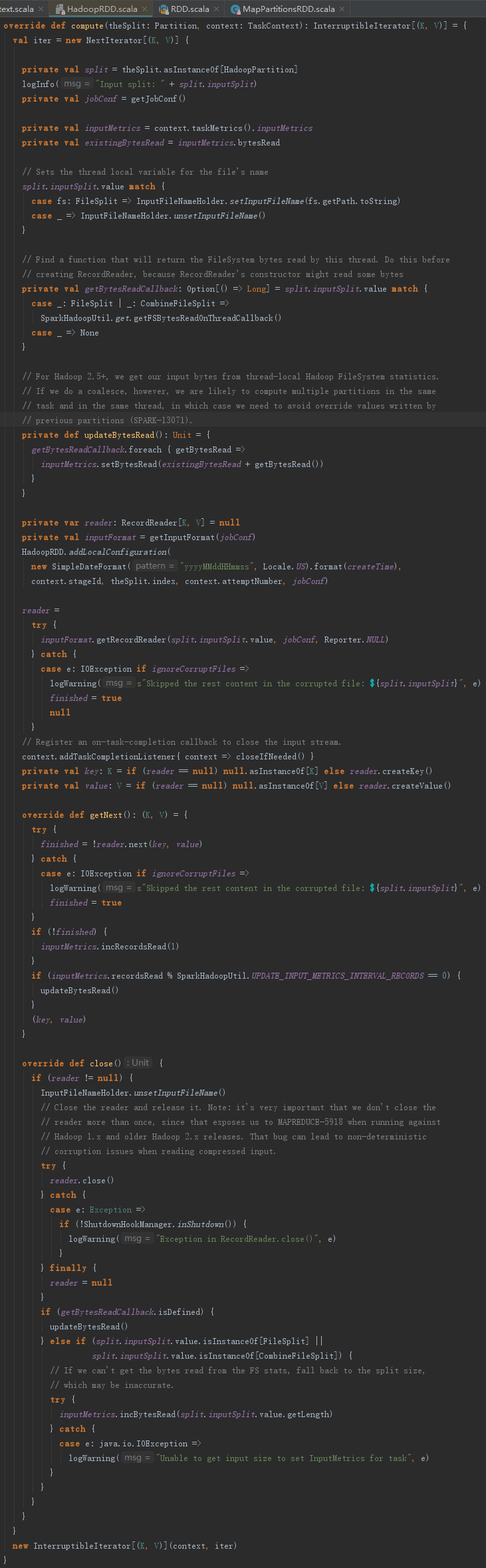
构造NextIterator的过程如下:
1) 从broadcast中获取jobConf,此处的jobConf是hadoopConfiguration。
2) 创建InputMetrics用于计算字节读取的测量信息,然后在RecordReader正式读取数据之前创建bytesReadCallback。byteReadCallback用于获取当前线程从文件系统读取的字节数。
3) 获取inputFormat,此处的inputFormat是TextInputFormat。
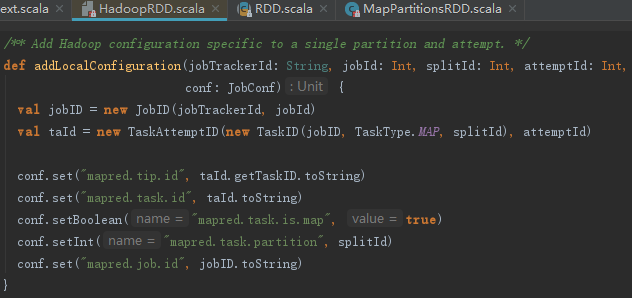
4) 使用addLocalConfiguration给JobConf添加Hadoop任务相关配置。addLocalConfiguration的实现见如下代码:
5) 创建RecordReader,调用reader.createKey()和reader.createValue()得到的是LongWritable和Text。NextIterator的getNext实际是代理了RecordReader的next方法并且每读取一些记录后使用bytesReadCallback更新InputMetrics的bytesRead字段。
6) 将NextIterator封装为InterruptibleIterator。
InterruptibleIterator只是对NextIterator的代理,见代码如下:
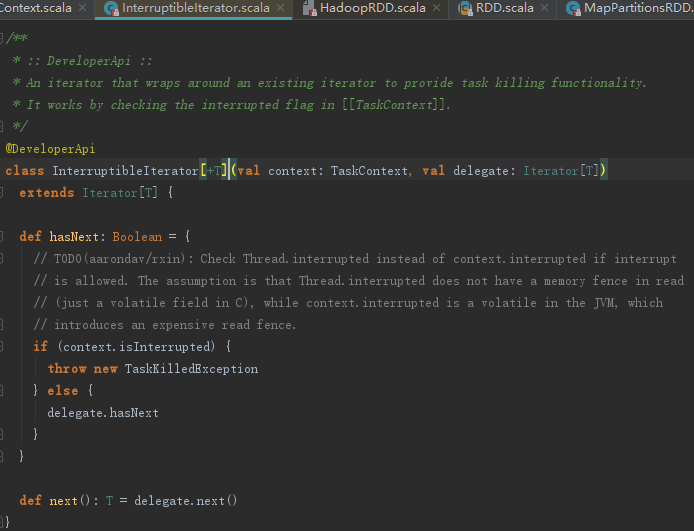
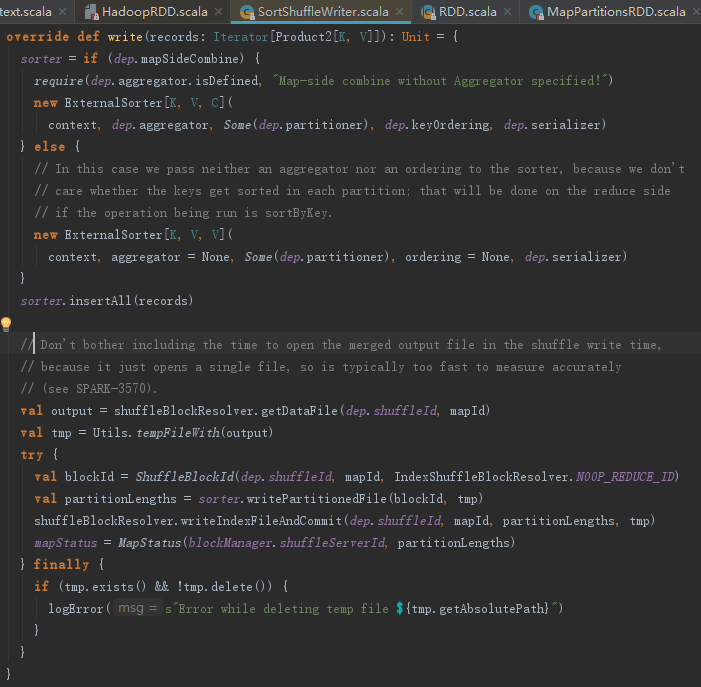
根据5.5.3节的内容,我们知道整个rdd.iterator调用结束,最后返回InterruptibleIterator对象后,会调用SortShuffleWriter的write方法,其功能如下:
1) 创建ExternalSorter,然后调用insertAll将计算结果写入缓存。
2) 调用shuffleBlockManager.getDataFile方法获取当前任务要输出的文件路径。
3) 调用shuffleBlockManager.consolidateId创建blockId。
4) 调用ExternalSorter的writePartitionedFile将中间结果持久化。
5) 调用shuffleBlockManager.writeIndexFile方法创建索引文件。
6) 创建MapStatus。
2. 什么是shuffle
shuffle是所有MapReduce计算框架所必须经过的阶段,shuffle用于打通map任务的输出与reduce任务的输入,map任务的中间输出结果按照key值哈希后分配给某一个reduce任务,这个过程如图所示:

在具体分析源码之前,我们先看看Spark早期版本的shuffle是怎样的,如图所示:
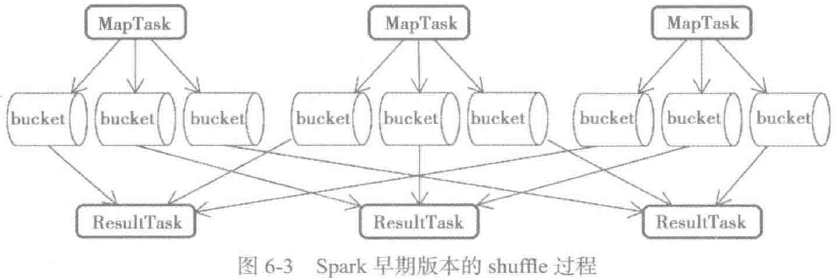
这里对图6-3做一些解释:
1) map任务会为每一个reduce任务创建一个bucket。假设有M个map任务,R个reduce任务,则map阶段一共会创建M x R 个bucket;
2) map任务会将产生的中间结果按照partition写入不同 的bucket中;
3) reduce任务从本地或者远端的map任务所在的BlockManager获取相应的bucket作为输入。
Spark早期的shuffle过程存在以下问题:
1) map任务的中间结果首先存入内存,然后才写入磁盘。这对于内存的开销很大,当一个节点上map任务的输出结果集很大时,很容易导致内存紧张,进而发生内存溢出(out of memory , OOM);
2) 每个map任务都会输出R(reduce任务数量)个bucket。假如M等于1000,R也等于1000,那么共计生成100万个bucket,在bucket本身不大,但是shuffle很频繁的情况下,磁盘I/O将称为性能瓶颈。
熟悉Hadoop的读者应该知道,Hadoop MapReduce的shuffle过程存在以下问题:
1) reduce任务获取到map任务的中间输出后,会对这些数据在磁盘上进行merge sort,虽然不怎么占用内存,但是却产生了更多的磁盘I/O;
2) 当数据量很小,但是map任务和reduce任务数目很多时,会产生很多网络I/O。
为了解决以上Hadoop MapReduce和早期Spark在shuffle过程中的性能问题,目前Spark的shuffle已经做了多种性能优化,主要解决方法包括:
1) 将map任务给每个partition的reduce任务输出的bucket合并到同一个文件中,这解决了bucket数量很多,但是本身数据体积不大时,造成shuffle很频繁,磁盘I/O成为性能瓶颈的问题;
2) map任务逐条输出计算结果,而不是一次性输出到内存,并使用AppendOnlyMap缓存及其聚合算法对中间结果进行聚合,这大大减小了中间结果所占的内存大小;
3) 对SizeTrackingAppendOnlyMap和SizeTrackingPairBuffer等缓存进行溢出判断,当超出myMemoryThreshold的大小时,将数据写入磁盘,防止内存溢出;
4) reduce任务对拉取到的map任务中间结果逐条读取,而不是一次性读入内存,并在内存中进行聚合和排序(其本质上也使用了AppendOnlyMap缓存),这也大大减小了数据占用的内存;
5) reduce任务将要拉取的Block按照BlockManager地址划分,然后将同一BlockMananger地址中的Block累积为少量网络请求,减少网络I/O。
3. map端计算结果缓存处理
在详细介绍map端对中间计算结果的细节之前,先理解两个概念:
- bypassMergeThreshold:传递到reduce端再做合并(merge)操作的阀值。如果partition的数量小于bypassMergeThreshold的值,则不需要在Executor执行聚合和排序操作,只需要将各个partition直接写到Executor的存储文件,最后在reduce端再做串联。通过配置spark.shuffle.sort.bypassMergeThreshold可以修改bypassMergeThreshold的大小,在分区数量小的时候提升计算引擎的性能。bypassMergeThreshold的默认值是200。
- bypassMergeSort:标记是否传递到reduce端再做合并和排序,即是否直接将各个partition直接写到Executor的存储文件。当没有定义aggregator、ordering函数,并且partition的数量小于等于bypassMergeThreshold时,bypassMergeSort为true。如果bypassMergeSort为true,map中间结果将直接输出到磁盘,此时不会占用太多内存,避免了内存撑爆问题。
map端计算结果缓存有三种处理方式(见如下代码):
- map端对计算结果在缓存中执行聚合和排序。
- map不使用缓存,也不执行聚合和排序,直接调用spillToPartitionFiles将各个partition直接写到自己的存储文件(即bypassMergeSort为true的情况),最后由reduce端对计算结果执行合并和排序。
- map端对计算结果简单缓存。
我们先来分析两种需要缓存的方式。
3.1 map端计算结果缓存聚合
一个任务的分区数量通常很多,如果只是简单地将数据存储到Executor上。在执行reduce任务时会存在大量的网络I/O操作,这时网络I/O将成为系统性能的瓶颈,reduce任务读取map任务的计算结果变慢,导致其他想要分配到被这些map任务占用的节点的任务不得不等待或者降低本地化选择分配到更远的节点上。对于更远节点的I/O本身会更慢,因此还会导致更多的任务得不到分配或者无法高效本地化。经过这样的恶性循环,整个集群将变得迟钝,新的任务长时间得不到执行或者执行变慢。
通过在map端对计算结果在缓存中执行聚合和排序,能够节省I/O操作,进而提升系统性能。这种情况下,必须要定义聚合器(aggregator)函数,以便于对计算结果按照按照partitionID和key聚合后进行排序。
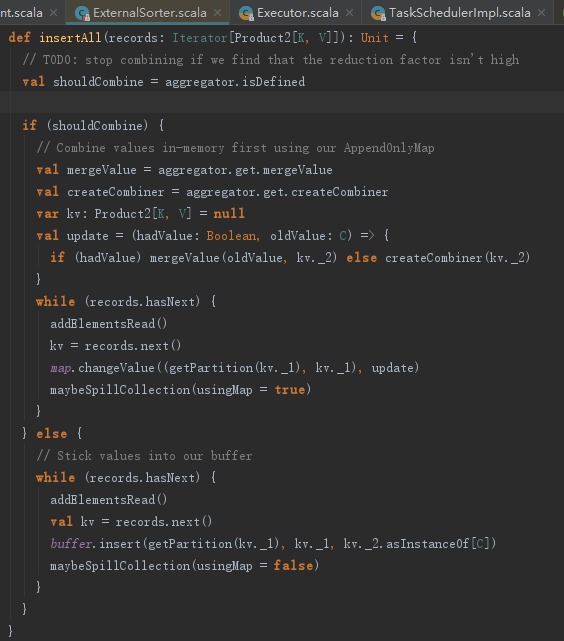
ExternalSorter的insertAll方法中,如果定义了aggregator,则shouldCombine为true。此分支执行过程如下:
1) 由于设置了聚合函数aggregator,则从聚合函数获取mergeValue(word count例子中为Function2)、createCombiner(word count例子中为PairFunction)等函数。
2) 定义update偏函数,此函数用于操作mergeValue和createCombiner。
3) 迭代之前创建的iterator,每读取一条Product2[K, V],将每行字符串按照空格划分,并且给每个文本设置1,比如(#,1)、(Apache,1)、(Spark,1)...。
4) 以(分区索引,Produce2[K,V]._1)为参数调用SizeTrackingAppendOnlyMap的changeValue函数,与update函数配合,按照key值叠加value。
5) 调用mapbeSpillCollection方法,来处理SizeTrackingAppendOnlyMap溢出(当SizeTrackingAppendOnlyMap的大小超过myMemoryThreshold时,将集合中的数据写入磁盘并新建SizeTrackingAppendOnlyMap)。这样做是为了防止内存溢出,解决了Spark早期版本shuffle的内存撑爆问题。

SizeTrackingAppendOnlyMap的changeValue方法的处理包括三步:
1) 调用父类AppendOnlyMap的changeValue函数,应用缓存聚合算法。
2) 调用继承特质SizeTracker的afterUpdate函数,增加对AppendOnlyMap大小的采样。
3) 返回第1)步计算的结果。
1. AppendOnlyMap的缓存聚合算法
SizeTrackingAppendOnlyMap的父类AppendOnlyMap的changeValue函数用于回调update函数进行聚合操作。其实现可以说明,AppendOnlyMap支持null值的缓存,而Java的map默认是不支持的。changeValue方法利用一种使用数据缓存的算法完成聚合。在介绍此算法前先弄清一些定义:
- LOAD_FACTOR:负载因子,常量值等于0.7。
- initialCapacity:初始容量值64。
- capacity:容量,初始时等于initialCapacity。
- curSize:记录当前已经放入data的key与聚合值的数量。
- data:数组,初始大小为2*capacity,data数组的实际大小之所以是capacity的2倍,是因为key和聚合值各占一位。
- growThreshold:data数组容量增加的阀值,表达式为growThreshold = LOAD_FACTOR * capacity。
- mask:计算数据存放位置的掩码值,表达式为capacity - 1。
- k:要放入data的key。
- pos:k将要放入data的索引值。索引值等于k的哈希值再次计算哈希值的结果与mask按位&运算的值。表达式为pos = rehash (k.hashCode) & mask。
- curKey:data(2 * pos)位置的当前key。
- newValue:key的聚合值。
在掌握以上概念的前提下,给出以下算法描述:
条件1:如果curKey等于null,那么newValue等于1;
条件2:如果curKey不等于null并且不等于k,那么从pos当前位置向后找,直到此位置的索引值与mask按位&运算后的新位置的key符合条件1或者条件3;
条件3:如果curKey不等于null并且等于k,那么newValue等于data(2 * pos + 1) 与k对应的值按照mergeValue定义的函数运算。

2.AppendOnlyMap的容量增长
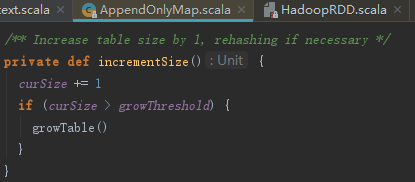
incrementSize方法用于扩充AppendOnlyMap的容量。当curSize>growThreshold时,调用growTable方法将capacity容量扩大一倍,即newCapacity = capacity * 2。
growTable方法先创建newCapacity的两倍大小的新数组,将老数组中的元素复制到新数组中,新数组索引位置采用新的mask重新使用rehash(k.hashCode)&mask计算。

经过以上算法的运算,word count例子的数据集合中间计算结果会变为((0, site), 1)、((0, which), 2)、((0, hadoop), 4)的样子,证明确实发生了聚合。
3.AppendOnlyMap大小采样
上一节growTable代码列出了AppendOnlyMap的容量增长实现方法growTable,那是不是意味着AppendOnlyMap的容量可以无限制增长呢?当然不是,我们需要对AppendOnlyMap大小进行限制。很明显我们可以在AppendOnlyMap的每次更新操作之后计算它的大小,这应该没有什么问题。Spark为大数据平台需要提供实时计算能力,无论是数据量还是对CPU的开销都很大,每当发生update或者insert操作就计算一次大小会严重影响Spark的性能,因此Spark实际采用了采样并利用这些采样对AppendOnlyMap未来的大小进行估算或推测的方式。
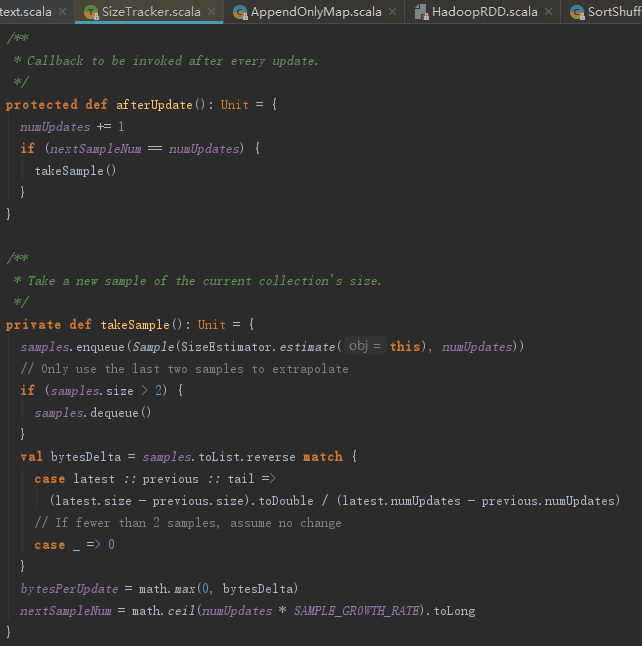
SizeTrackingAppendOnlyMap继承了特质SizeTracker,其afterUpdate,其处理步骤如下:
1) 将AppendOnlyMap所占的内存进行估算并且与当前编号(numUpdates)一起作为样本数据更新到samples = new mutable.Queue[Sample]中。
2) 如果当前采样数量大于2,则使samples执行一次出队操作,保证样本总数等于2。
3) 计算每次更新增加的大小,公式如下:

4) 计算下次采样的间隔nextSampleNum。
AppendOnlyMap的大小采样数据用于推测AppendOnlyMap未来的大小。推测的实现见如下代码。由于PartitionedPairBuffer也继承了SizeTracker,所以estimateSize方法不但对AppendOnlyMap也对PartitionedPairBuffer在内存中的容量进行限制以防内存溢出时发挥其作用。
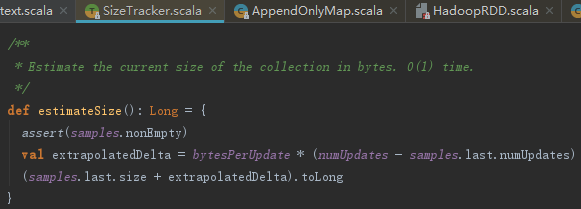
3.2 map端计算结果简单缓存
ExternalSorter的insertAll方法中,如果没有定义aggregator,那么shouldCombine为false,见代码如下。这时会调用PartitionedPairBuffer的insert方法,从其实现可以知道,它只不过是把计算结果简单缓存到数组中了。

下面我们来介绍PartitionedPairBuffer的容量增长。
PartitionedPairBuffer的容量增长是通过growArray方法实现的。growArray实现增长data数组容量的方式非常简单,只是新建2倍大小的新数组,然后简单复制而已,见代码如下:
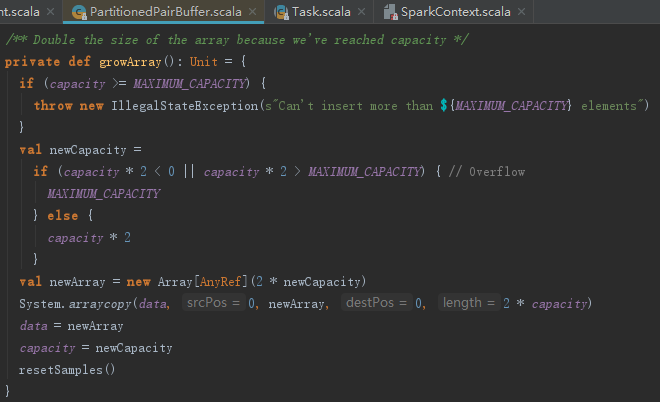
spark使用PartitionedPairBuffer的过程中,也会调用maybeSpillCollection方法,来处理PartitionedPairBuffer溢出(当PartitionedPairBuffer的大小超过myMemoryThreshold时,将集合中的数据写入磁盘并新建PartitionedPairBuffer)。这样做是为了防止内存溢出,解决了Spark早期版本shuffle的内存撑爆问题。
3.3 容量限制
既然AppendOnlyMap和PartitionedPairBuffer的容量都可以增长,那么数据量不大的时候不会有问题。但由于大数据处理的数据量往往都很大,全部都放入内存会将系统的内存撑爆。Spark为了防止这个问题的发生,提供了函数maybeSpillCollection,见代码如下:

1.集合溢出判定
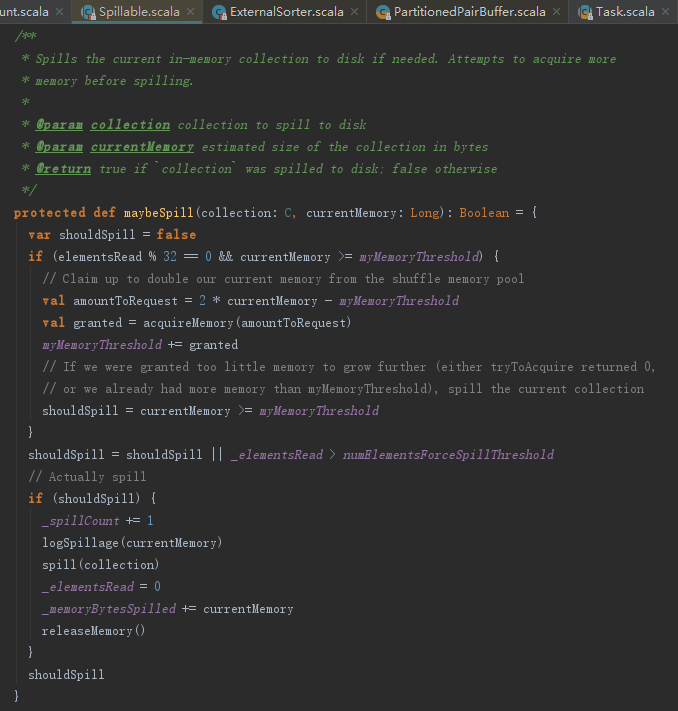
maybeSpillCollection判定集合是否溢出主要由maybeSpill函数来决定,见代码如下。maybeSpill函数的处理步骤如下:
1) 为当前线程尝试获取amountToRequest大小的内存(amountToRequest = 2 * currentMemory - myMemoryThreshold)。
2) 如果获得的内存依然不足(myMemoryThreshold <= currentMemory),则调用spill,执行溢出操作。内存不足可能是申请到的内存为0或者已经申请得到的内存大小超过了myMemoryThreshold。
3) 溢出后续处理,如elementsRead归零,已溢出内存字节数(memoryBytesSpilled)增加线程当前内存大小(currentMemory),释放当前线程占用的内存。
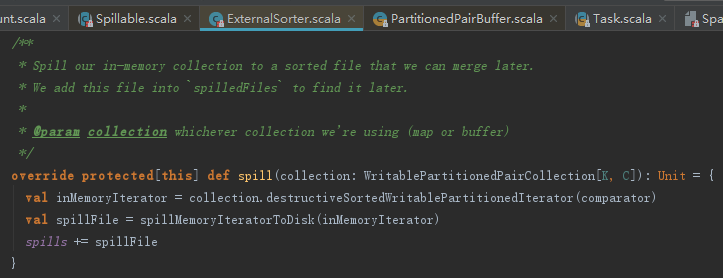
2. 溢出
spill方法的实现,见如下代码。如果bypassMergeSort为真,则调用spillToPartitiionFiles将内存中的数据溢出到分区文件。如果bypassMergeSort不为真,则调用spillToMergeableFile。
spillToMergeableFile方法的处理步骤如下:
1) 调用createTempShuffleBlock创建临时文件。
2) 新建ShuffleWriteMetrics用于测量。
3) 调用getDiskWriter方法创建DiskBlockObjectWriter。
4) 调用destructiveSortedIterator方法对集合元素排序。
5) 将集合内容写入临时文件。写入的时机有两个:
- 集合遍历完的时候,执行flush。
- 遍历过程中,每当写入DiskBlockObjectWriter的元素个数(objectsWritten)达到批量序列化尺寸(serializerBatchSize)时,也会执行flush,然后重新创建DiskBlockObjectWriter。

4.map端计算结果持久化
writPartitionedFile用于持久化计算结果。此方法有两个分支:
- 溢出到分区文件后合并:将内存中缓存的多个partition的计算结果分别写入多个临时Block文件,然后将这些Block文件的内容全部写入正式的Block输出文件中。
- 内存中排序合并:将缓存的中间计算结果按照partition分组后写入Block输出文件。此种方式还需要更新此任务与内存、磁盘有关的测量数据。
无论哪种排序方式,每个partition都会最终写入一个正式的Block文件,所以每个map任务实际上最后只会生成一个磁盘文件,最终解决了Spark早期版本中一个map任务输出的bucket文件过多和磁盘I/O成为性能瓶颈的问题。此外,无论哪种排序方式,每输出完一个partition的中间结果时,都会记录当前partition的长度,此长度将记录在索引文件中,以便下游任务的读取。
writePartitionedFile中有关DiskBlockObjectWriter的实现。
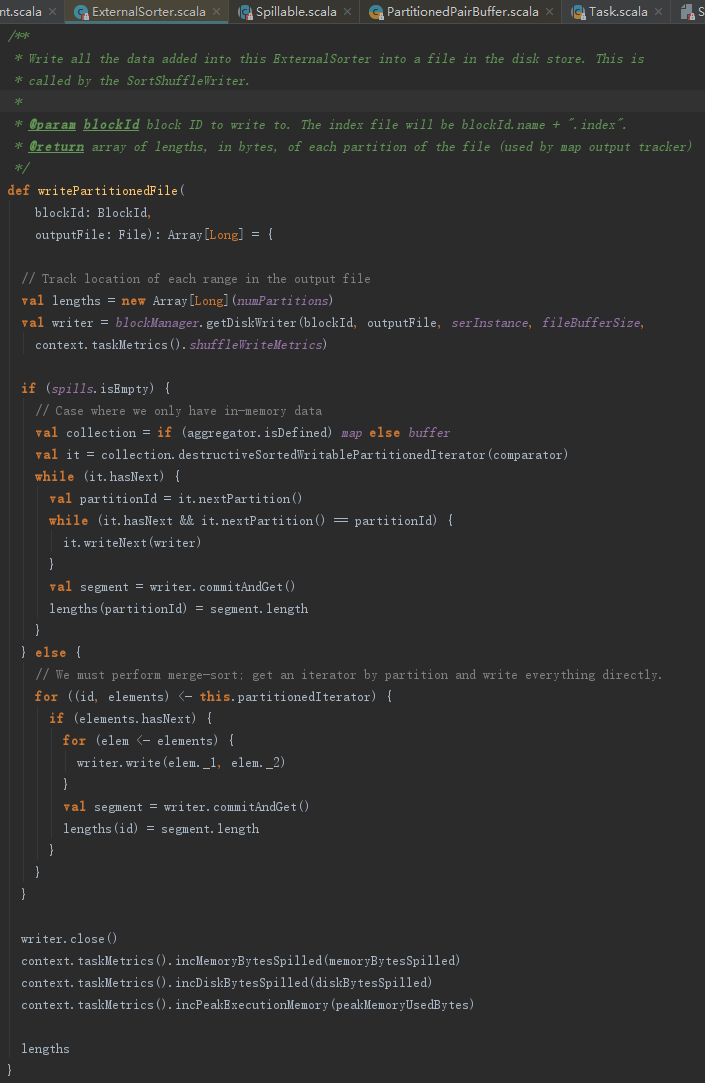
4.1 溢出分区文件
spillToPartitionFiles用于将内存中的集合数据按照每个partition创建一个临时Block文件,为每个临时Block文件生成一个DiskBlockObjectWriter,并且用DiskBlockObjectWriter将计算结果分别写入这些临时Block文件中。createTempShuffleBlock方法创建临时的Block。getDiskWriter方法创建DiskBlockObjectWriter。
略
4.2 排序与分区分组
partitionedIterator通过对集合按照指定的比较器进行排序,并且按照partition id分组,生成迭代器。
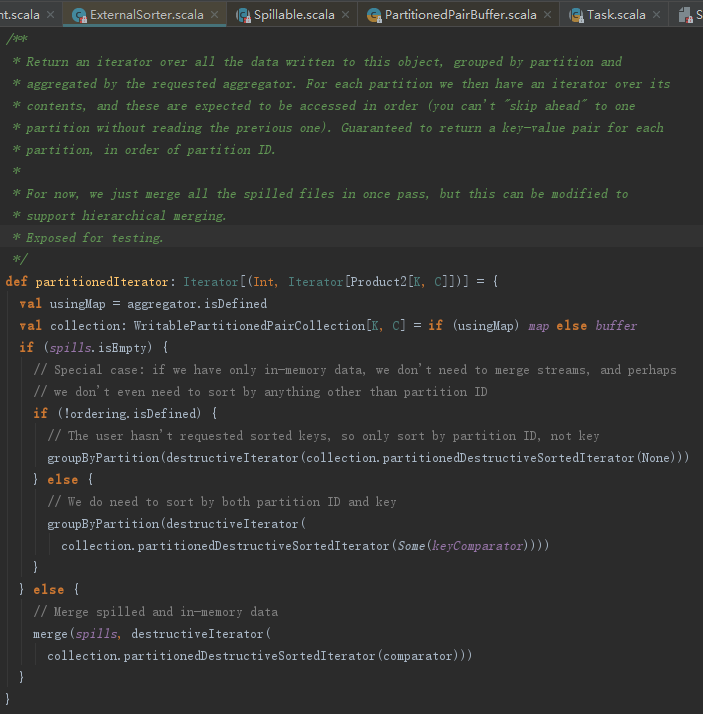
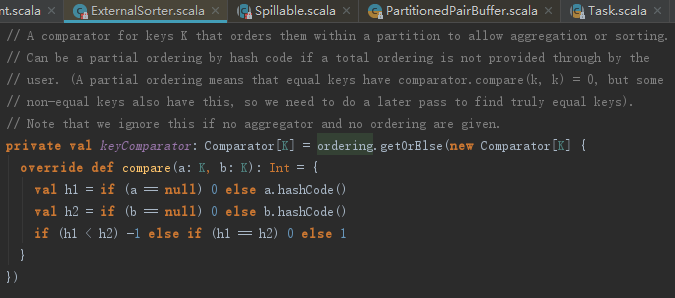
1.比较器
下述代码列出了目前的三种比较器:
- keyComparator:按照指定的key进行排序;
- partitionComparator:按照partition id进行比较;
- partitionKeyComparator:先按照partition id进行比较,再按照指定的key进行第二级排序。当没有指定排序字段并且没有指定聚合函数时会退化为partitionComparator。
由于partitionedIterator方法实际是通过调用destructiveSortedIterator和groupByPartition来实现,下面详细分析这两个方法。
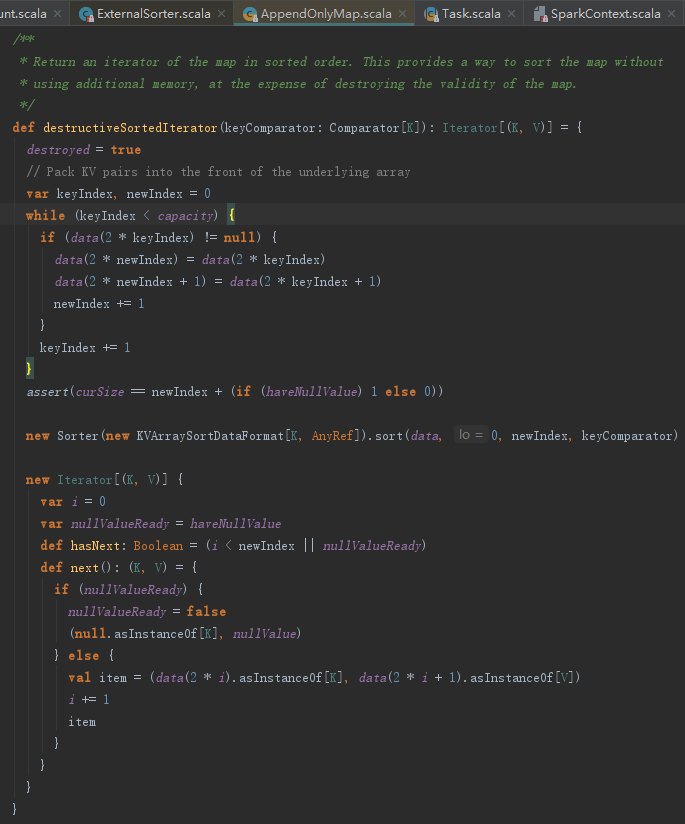
2.排序
destructiveSortedIterator方法的处理步骤如下:
1) 将data数组向左整理排序。
2) 利用Sorter、KVArraySortDataFormat以及指定的比较器进行排序。这其中用到了TimSort,也就是优化版的归并排序。
3) 生成新的迭代器。
3.分区分组
groupByPartition主要用于对destructiveSortedIterator生成的迭代器按照partition id分组。
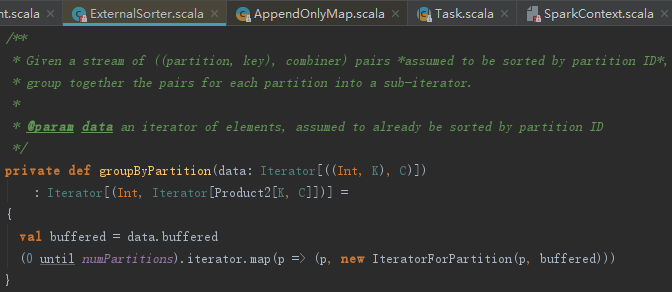
IteratorForPartition如何区分partition呢?见如下代码。可见其hasNext会判断数据的partitionId。
4.3 分区索引文件
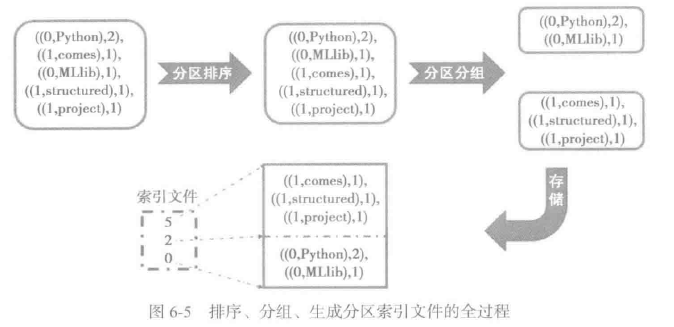
无论采用哪种缓存处理,在持久化的时候都会被写入同一文件。那么reduce任务如何从此文件中按照分区读取数据呢?IndexShuffleBlockManager的writeIndexFile方法生成的分区索引文件。此文件使用偏移量来区分各个分区的计算结果,偏移量来自于合并排序过程中记录的各个partition的长度。
这里用下图展示内存中排序、分组后生成分区索引文件的全过程。
5. reduce端读取中间结算结果
先简单说下,当map任务相关Stage的任务都执行完毕后,会唤起下游Stage的提交及任务的执行。上游任务的执行结果必然是下游任务的输入,我们就下游 任务如何读取上游任务计算结果来展开。
ResultTask的计算是由RDD的iterator方法驱动,这在介绍ShuffleMapTask的时候已经介绍过。其计算过程最终会落实到ShuffleRDD的compute方法。ShuffleRDD的compute方法首先会调用SortShuffleManager的getReader方法创建BlockStoreShuffleReader,然后执行BlockStoreShuffleReader的read方法读取依赖任务的中间计算结果。
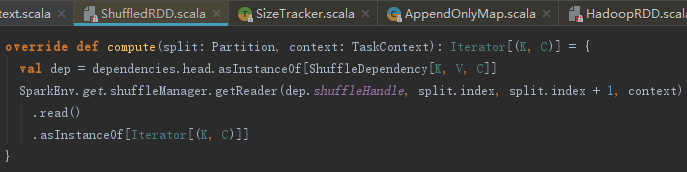
SortShuffleManager的getReader方法的实现如下:

BlockStoreShuffleReader用来读取上游任务计算结果,它的read方法的处理步骤如下:
1) 从远端节点或者本地读取中间计算结果。
2) 对InterruptibleIterator执行聚合。
3) 对InterruptibleIterator排序,由于使用ExternalSorter的insertAll,不再赘述。
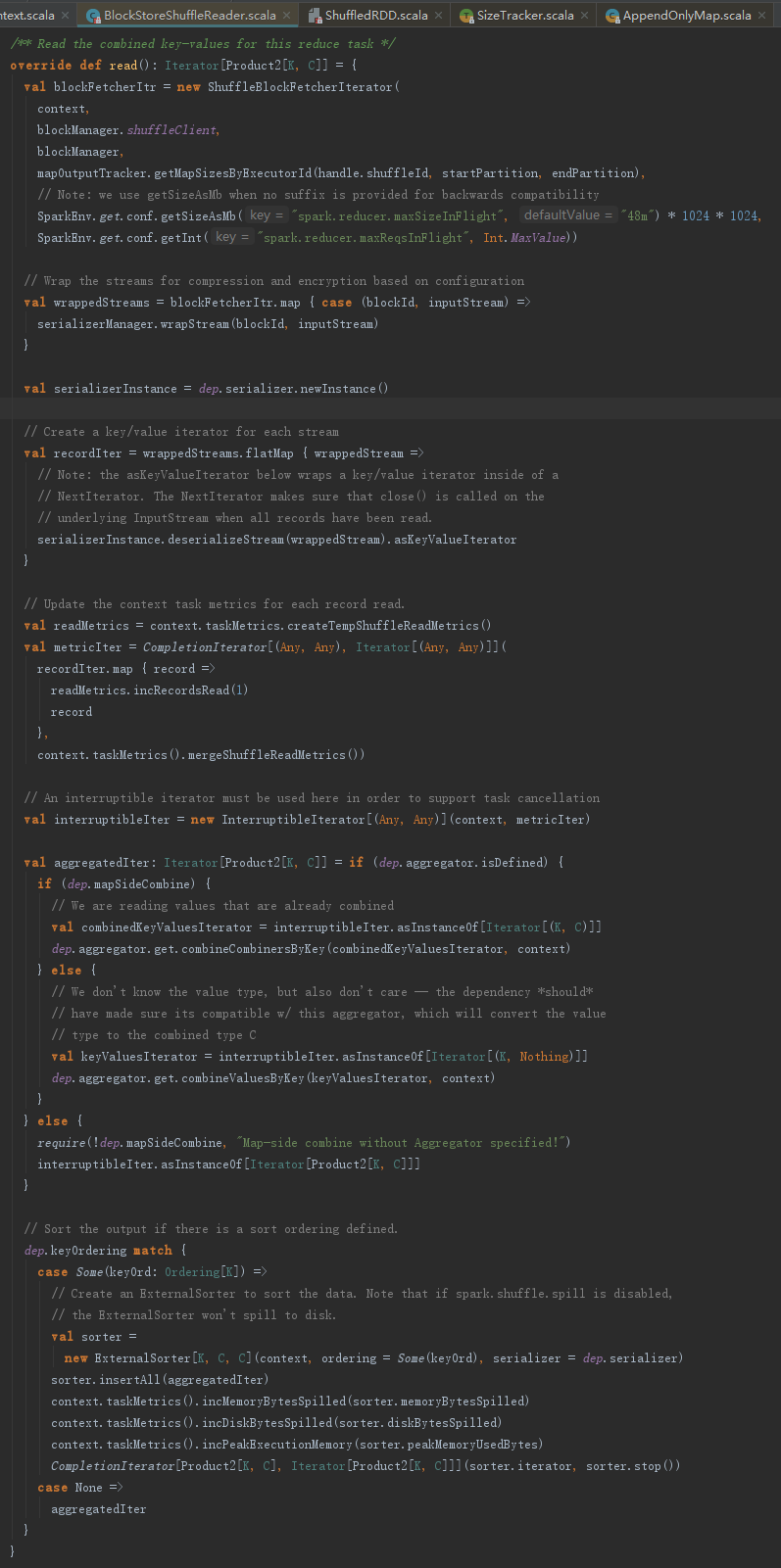
从远端节点或者本地读取中间计算结果通过调用BlockStoreShuffleFetcher的fetch方法实现,它的处理步骤如下:
1) 获取map任务执行的状态信息。
2) 按照中间结果所在节点划分各个Block。
3) 创建ShuffleBlockFetcherIterator(即从远端节点或者本地读取中间计算结果)。
4) 将ShuffleBlockFetcherIterator封装为InterruptibleIterator。

5.1 获取map任务状态
Spark通过调用MapOutputTracker的getServerStatues来获取map任务执行的状态信息,其处理步骤如下:
1) 从当前BlockManager的MapOutputTracker中获取MapStatus,若没有就进入第2)步,否则直接到第4)步。
2) 如果获取列表(fetching)中已经存在要取的shuffleId,那么就等待其他线程获取。如果获取列表中不存在要取的shuffleId,那么就将shuffleId放入获取列表。
3) 调用askTracker方法向MapOutputTrackerMasterEndpoint发送GetMapOutputStatuses消息获取map任务的状态信息。MapOutputTrackerMasterEndpoint接收到GetMapOutputStatuses消息后,将请求的map任务状态信息序列化发送给请求方。请求方接收到map任务状态信息后进行反序列化操作,然后放入本地的mapStatuses中。
4) 调用MapOutputTracker的convertMapStatuses方法将获得MapStatus转换为map任务所在的地址(即BlockManagerId)和map任务输出中分配给当前reduce任务的Block大小。




5.2 划分本地与远程Block
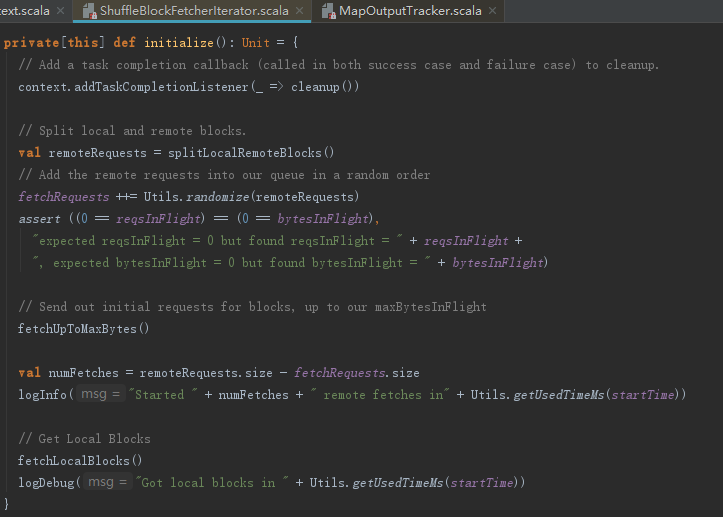
无论从本地还是从MapOutputTrackerMasterEndpoint获取的状态信息,都需要按照地址划分并且转换为BlockId。ShuffleBlockFetcherIterator是读取中间结果的关键。构造ShuffleBlockFetcherIterator的时候会调用到initialize方法,它的初始化过程如下:
1) 使用splitLocalRemoteBlocks方法划分本地读取和远程读取的Block的请求。
2) 将FetchRequest随机排序后存入fetchRequests:newQueue[FetchRequest]。
3) 遍历fetchRequests中的所有FetchRequest,远程请求Block中间结果。
4) 调用fetchLocalBlocks获取本地Block。
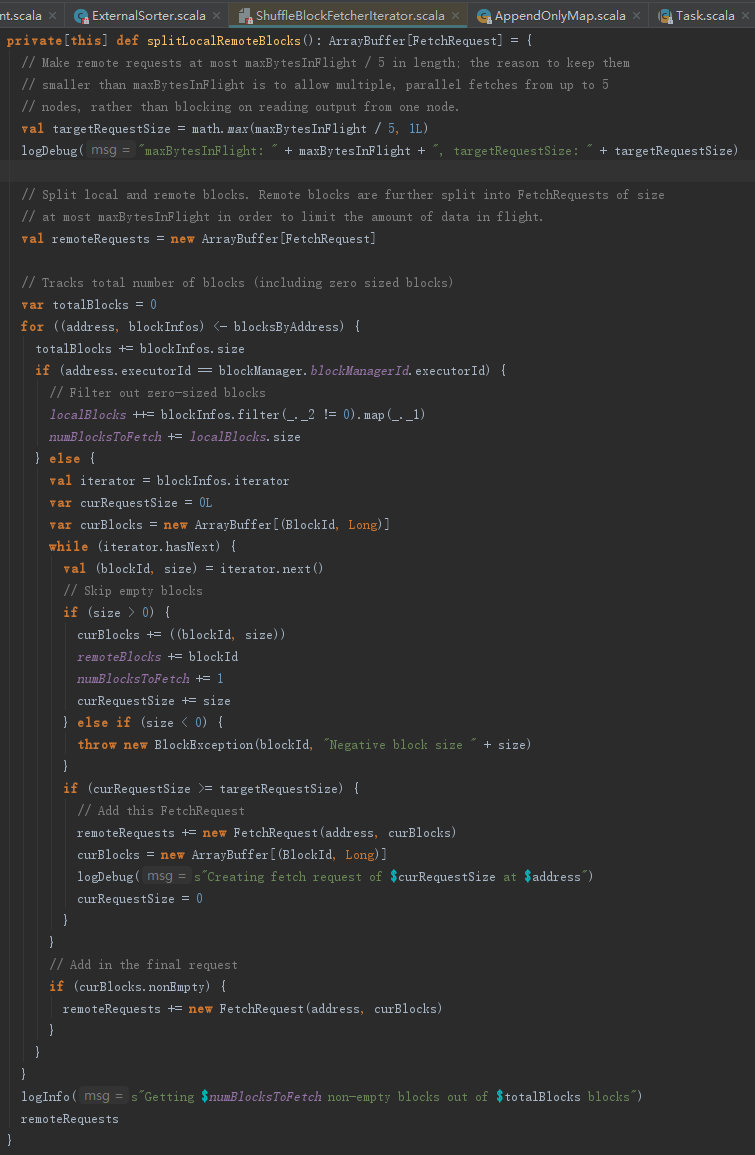
splitLocalRemoteBlocks方法用于划分哪些Block从本地获取,哪些需要远程拉取,是获取中间计算结果的关键。为便于描述,先解释以下定义:
- targetRequestSize:每个远程请求的最大尺寸。
- totalBlocks:统计Block总数。
- localBlocks:ArrayBuffer[BlockId],缓存可以在本地获取的Block的blockId。
- remoteBlocks:HashSet[BlockId]j,缓存需要远程获取的Block的blockId。
- curBlocks:ArrayBuffer[(BlockId, Long)],远程获取的累加缓存,用于保证每个远程请求的尺寸不超过targetRequestSize。为什么要累加缓存?如果向一个机器节点频繁地请求字节数很小的Block,那么势必造成网络拥塞并增加节点负担。将多个小数据量的请求合并为一个大的请求将避免这些问题,提高系统性能。
- curRequestSize:当前累加到curBlocks中的所有Block的大小之和,用于保证每个远程请求的尺寸不超过targetRequestSize。
- remoteRequests:new ArrayBuffer[FetchRequest],缓存需要远程请求的FetchRequest对象。
- numBlocksToFetch:一共要获取的Block数量。
- maxBytesInFlight:单次航班请求的最大字节数。什么叫航班?其实就是一批请求,这批请求的字节总数不能超过maxBytesInFlight,而且每个请求的字节数不能超过maxBytesInFilght的五分之一。可以通过参数spark.reducer.maxMbInFlight来控制大小。为什么每个请求的字节数不能超过maxBytesInFlight的五分之一?这样做是为了提高请求的并发度,允许5个请求分别从5个节点获取数据,最大限度利用各节点的资源。
明白了这些定义,我们一起来看看splitLocalRemoteBlocks的处理逻辑吧。
1) 遍历已经按照BlockManagerId分组的blockInfo,如果blockInfo所在的Executor与当前Executor相同,则将它的BlockId存入localBlocks;否则,将blockInfo的BlockId和size累加到curBlocks,将blockId存入remoteBlocks,curRequestSize增加size的大小,每当curRequestSize >= targetRequestSize,则新建FetchRequest放入remoteRequests,并且为生成下一个FetchRequest做一些准备(如新建curBlocks,curRequestSize置为0)。
2) 遍历结束,curBlocks中如果仍然有缓存的(BlockId,Long),新建FetchRequest放入remoteRequests。此次请求不受maxBytesInFlight和targetRequestSize的影响。
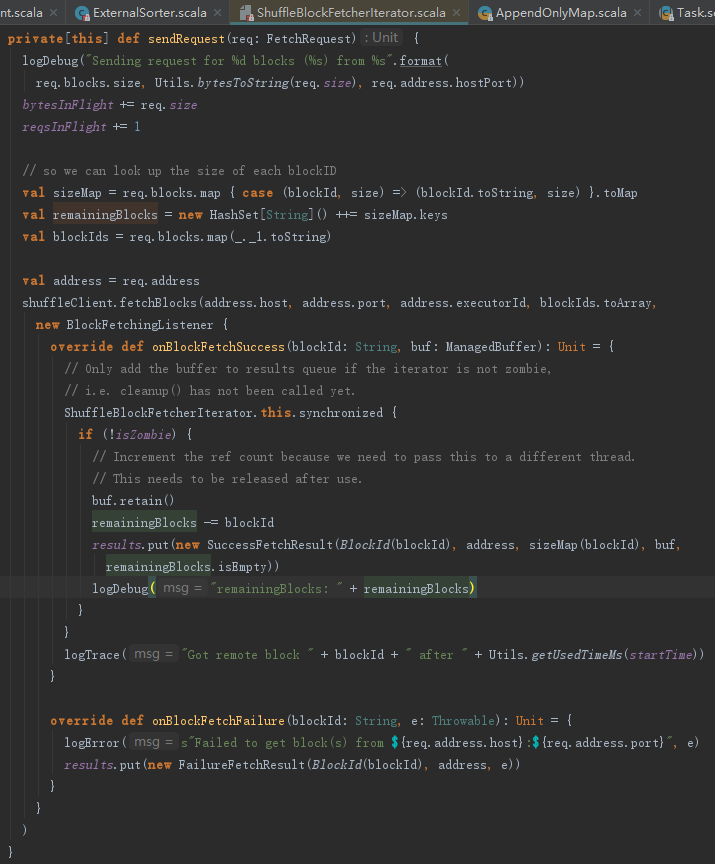
5.3 获取远程Block
sendRequest方法用于远程请求中间结果。sendRequest利用FetchRequest里封装的blockId、size、address等信息,调用shuffleClient的fetchBlocks方法获取其他节点上的中间计算结果。
5.4 获取本地Block
fetchLocalBlocks用于对本地中间计算结果的获取。fetchLocalBlocks方法很简单,利用熟悉的BlockManager的getBlockData方法获取本地Block,最后将取到的中间结果存入results = new LinkedBlockingQueue[FetchResult]中。
6.reduce端计算
6.1 如何同时处理多个map任务的中间结果
reduce任务的上游map任务可能有多个,根据之前的分析,知道这些中间结果的Block及数据缓存在ShuffleBlockFetcherIterator的results:new LinkedBlockingQueue[FetchResult]中。ShuffleBlockFetcherIterator作为迭代器,它的实现见如下代码。从其实现可知,每次迭代ShuffleBlockFetcherIterator,会先从results:new LinkedBlockingQueue[FetchResult]中取出一个FetchResult,并构造此FetchResult的迭代器。

6.2 reduce端再缓存中对中间计算结果执行聚合和排序
reduce端获取map端任务计算中间结果后,将ShuffleBlockFetcherIterator封装为InterruptibleIterator并聚合。聚合操作主要依赖aggregator的combineCombinersByKey方法,见如下代码。如果isSpillEnabled为false,会再次使用AppendOnlyMap的changeValue方法。isSpillEnabled默认是true,此时会使用ExternalAppendOnlyMap完成聚合。
ExternalAppendOnlyMap的insert方法的实际工作是由insertAll完成的,见如下代码。从代码实现可以看到其实质也是使用SizeTrackingAppendOnlyMap。
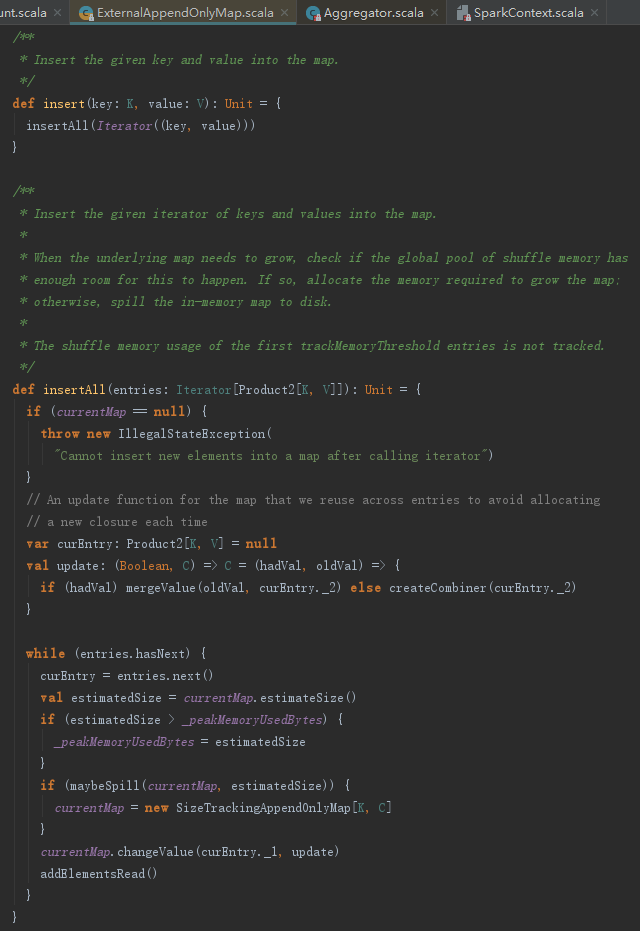
经过以上处理,数据结果为类似(##, 8), (N, 1), (set, 2), (use, 3), (Hadoop-supported, 1)的样子。
7.map端与reduce端组合分析
这一节主要对计算引擎部分的内容进行串联,用图来展示最常见的几种组合,以便大家对计算引擎有个宏观的认识。
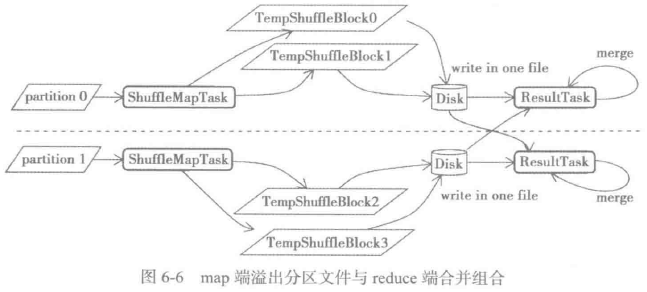
7.1 在map端溢出分区文件,在reduce端合并组合
bypassMergeSort标记是否传递到reduce端再做合并和排序,此种情况不使用缓存,而是先将数据按照partition写入不同文件,最后按partition顺序合并写入同一文件。当没有指定聚合、排序函数,且partition数量较小时,一般采用这种方式。此种方式将多个bucket合并到同一个文件,通过减少map输出的文件数量,节省了磁盘I/O,最终提升了性能,见如下图:
7.2 在map端简单缓存、排序分组,在reduce端合并组合
此种情况在缓存中利用指定的排序函数对数据按照partition或者key进行排序,最后按partition顺序合并写入同一文件。当没有指定聚合函数,且partition数量大时,一般采用这种方式,见如下图。此种方式将多个bucket合并到同一个文件,通过减少map输出的文件数量,节省了磁盘I/O,提升了性能;对SizeTrackingPairBuffer的缓存进行溢出判断,当超过myMemoryThreshold的大小时,将数据写入磁盘,防止内存溢出。

7.3在map端缓存中聚合、排序分组,在reduce端组合
此种情况在缓存中对数据按照key聚合,并且利用指定的排序函数对数据按照partition或者key进行排序,最后按partition顺序合并写入同一文件。当指定了聚合函数时,一般采用这种方式,见如下图。此种方式将多个bucket合并到同一个文件,通过减少map输出的文件数量,节省了磁盘I/O,提升了性能;对中间输出数据不是一次性读取,而是逐条放入AppendOnlyMap的缓存,并对数据进行聚合,减少了中间结果占用的内存大小;对AppendOnlyMap的缓存进行溢出判断,当超出myMemoryThreshold的大小时,将数据写入磁盘,防止内存溢出。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号