Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述
注意:SparkContext的初始化剖析是基于Spark2.1.0版本的
Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端。了解Spark Driver的初始化,有助于读者理解用户应用程序在客户端的处理过程。
Spark Driver的初始化始终围绕着SparkContext的初始化。SparkContext可以算得上是所有Spark应用程序的发动机引擎,轿车要想跑起来,发动机首先要启动。SparkContext初始化完毕,才能向Spark集群提交任务。在平坦的公路上,发动机只需以较低的转速、较低的功率就可以游刃有余;在山区,你可能需要一台能够提供大功率的发动机才能满足你的需求。这些参数都是可以通过驾驶员操作油门、档位等传送给发动机的,而SparkContext的配置参数则由SparkConf负责,SparkConf就是你的操作面板。
SparkConf的构造很简单,主要是通过ConcurrentHashMap来维护各种Spark的配置属性。SparkConf代码结构如下,Spark的配置属性都是以“spark.”开头的字符串。

现在开始介绍SparkContext。SparkContext的初始化步骤如下:
- 创建Spark执行环境SparkEnv;
- 创建并初始化Spark UI;
- Hadoop相关配置及Executor环境变量的设置;
- 创建任务调度TaskScheduler;
- 创建和启动DAGScheduler;
- TaskScheduler的启动;
- 初始化管理器BlockManager(BlockManager是存储体系的主要组件之一)
- 启动测量系统MetricsSystem;
- 创建和启动Executor分配管理器ExecutorAllocationManager;
- ContextCleaner的创建与启动;
- Spark环境更新;
- 创建DAGSchedulerSource和BlockManagerSource;
- 将SparkContext标记为激活;
SparkContext的主构造参数为SparkConf,其实现如下:
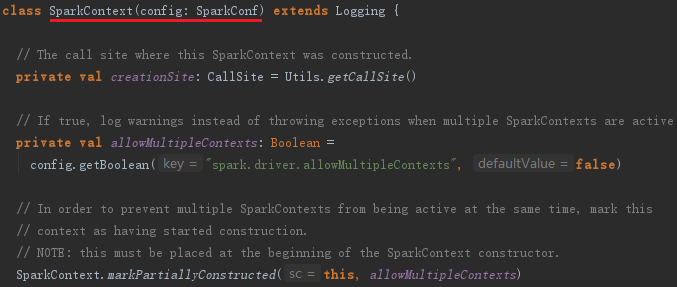
上面代码中的CallSite存储了线程栈中最靠近栈顶的用户类及最靠近栈底的Scala或者Spark核心类信息。SparkContext默认只有一个实例(由属性spark.driver.allowMultipleContexts来控制,用户需要多个SparkContext实例时,可以将其设置为true),方法markPartiallyConstructed用来确保实例的唯一性,并将当前SparkContext标记为正在构建中。
接下来会对SparkConf进行复制,然后对各种配置信息进行校验,代码如下:
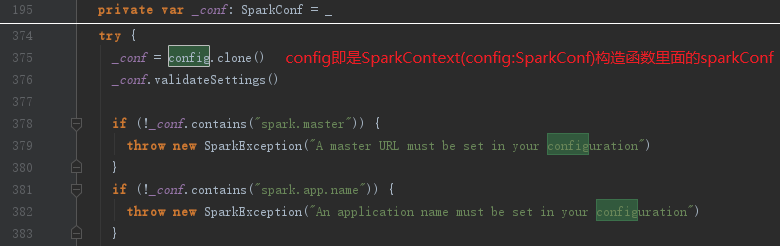
从上面校验的代码看到必须指定属性spark.master和spark.app.name,否则会抛出异常,结束初始化进程。spark.master用于设置部署模式,spark.app.name用于指定应用程序名称。
2. 创建执行环境SparkEnv
内容详情请看https://www.cnblogs.com/swordfall/p/9303348.html
3. 创建并初始化Spark UI
内容详情请看https://www.cnblogs.com/swordfall/p/9303399.html
4. Hadoop相关配置及Executor环境变量的设置
内容详情请看https://www.cnblogs.com/swordfall/p/9306113.html
5. 创建任务调度器TaskScheduler
内容详情请看:https://www.cnblogs.com/swordfall/p/9314949.html
6. 创建和启动DAGScheduler
内容详情请看:https://www.cnblogs.com/swordfall/p/9314940.html
7. TaskScheduler的启动
内容详情请看:https://www.cnblogs.com/swordfall/p/9314930.html
8. 初始化管理器BlockManager
内容详情请看:https://www.cnblogs.com/swordfall/p/9318900.html
9. 启动测量系统MetricsSystem
内容详情请看:https://www.cnblogs.com/swordfall/p/9317579.html
10. 创建和启动ExecutorAllocationManager
ExecutorAllocationManager用于对已分配的Executor进行管理,创建和启动ExecutorAllocationManager的代码如下:
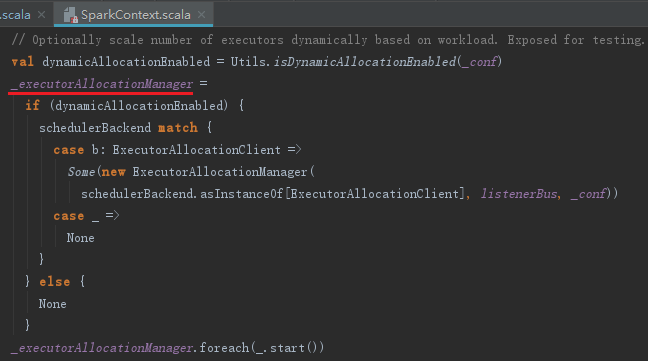
默认情况下不会创建ExecutorAllocationManager,可以修改属性spark.dynamicAllocation.enabled为true来创建。ExecutorAllocationManager可以设置动态分配最小Executor数量、动态分配最大Executor数量、每个Executor可以运行的Task数量等配置信息,并对配置信息进行校验。start方法将ExecutorAllocationListener加入listenerBus中,ExecutorAllocationListener通过监听listenerBus里的事件,动态添加、删除Executor。并且通过Thread不断添加Executor,遍历Executor,将超时的Executor杀掉并移除。ExecutorAllocationListener的实现与其他SparkListener类似,不再赘述。ExecutorAllocationManager的关键代码如下:
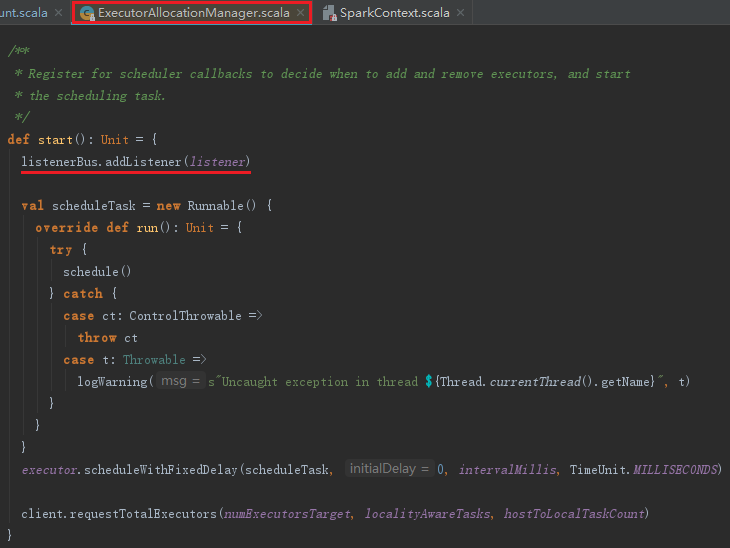
注意:listenerBus内置了线程listenerThread,此线程不断从eventQueue中拉出事件对象,调用监听器的监听方法。要启动此线程,需要调用listenerBus的start()方法,代码如下:
listenerBus.start()
11. ContextCleaner的创建与启动
ContextCleaner用于清理那些超出应用范围的RDD、ShuffleDependency和Broadcast对象。由于配置属性spark.cleaner.referenceTracking默认是true,所以会构造并启动ContextCleaner,代码如下:

ContextCleaner的组成如下:
- referenceQueue:缓存顶级的AnyRef引用;
- referenceBuffer:缓存AnyRef的虚引用;
- listeners:缓存清理工作的监听器数组;
- cleaningThread:用于具体清理工作的线程。
ContextCleaner的工作原理和listenerBus一样,也采用监听器模式,由线程来处理,此线程实际只是调用keepCleaning方法。keepCleaning的实现见代码:
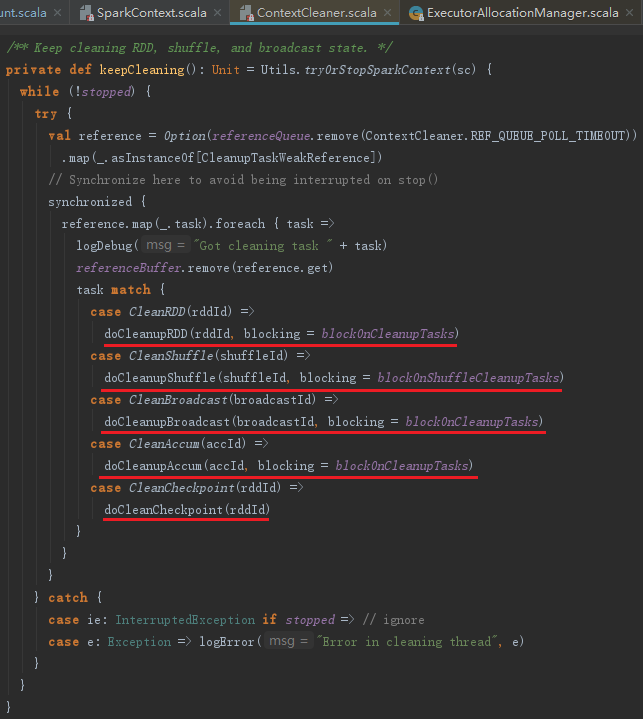
12. Spark环境更新
内容详情请看:https://www.cnblogs.com/swordfall/p/9318499.html
13. 创建DAGSchedulerSource和BlockManagerSource
在创建DAGSchedulerSource、BlockManagerSource之前首先调用taskScheduler的postStartHook方法,其目的是为了等待backend就绪,见代码:
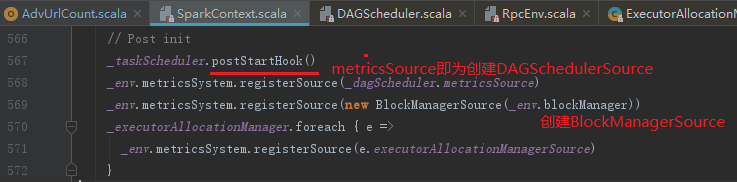
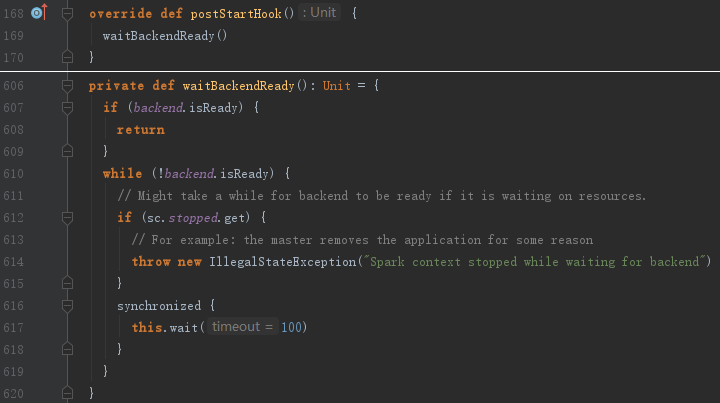
14. 将SparkContext标记为激活
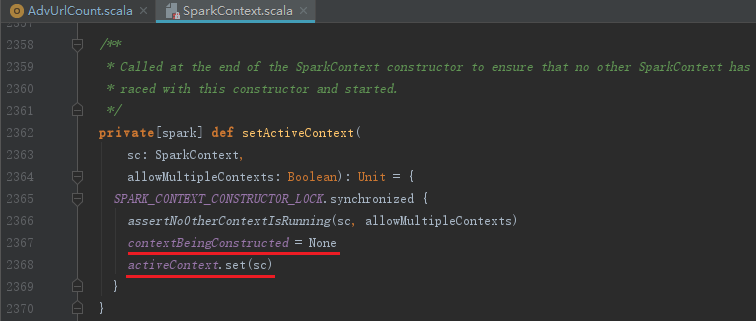
SparkContext初始化的最后将当前SparkContext的状态从contextBeingConstructed(正在构建中)改为activeContext(已激活),代码如下:

setActiveContext方法的实现如下:
15. 总结
listenerBus对于监听器模式的经典应用看来并不复杂,希望读者朋友能应用到自己的产品中去。此外,使用Netty所提供的异步网络框架构建的Block传输服务,基于Jetty构建的内嵌web服务(HTTP文件服务器和SparkUI),基于codahale提供的第三方测量仓库创建的测量系统,Executor中的心跳实现等内容,都值得借鉴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号