Spark SQL基本概念与基本用法
1. Spark SQL概述
1.1 什么是Spark SQL
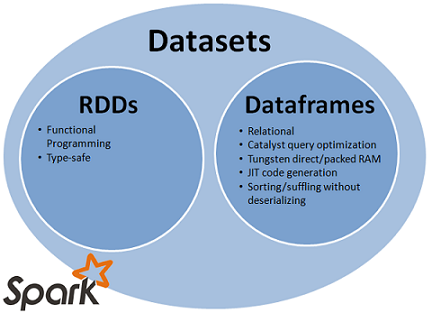
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为分布式SQL查询引擎。从下图可以查看RDD、DataFrames与DataSet的关系。
1.2 为什么要学习Spark SQL
Hive,它是将Hive SQL转换成MapReduce,然后提交到集群上执行的,大大简化了编写MapReduce程序的复杂性,而且MapReduce这种计算模型执行效率比较慢。类比Hive,Spark SQL,它时将Spark SQL转换成RDD,然后提交到集群上执行,执行效率非常快!
2. DataFrames
2.1 什么是DataFrames
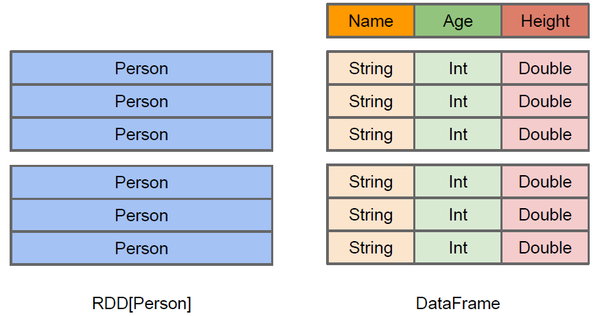
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
2.2 创建DataFrames
在Spark SQL中SQLContext是创建DataFrames和执行SQL的入口,在spark中已经内置了一个sqlContext。
创建DataFrames的步骤:
1) 在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.txt /
2) 在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://hadoop1:9000/person.txt").map(_.split(" "))
3) 定义case class(相当于表的schema)
case class Person(id:int, name:string, age:int)
4) 将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
5) 将RDD转换成DataFrame
val personDF = personRDD.toDF
6) 对DataFrame进行处理
personDF.show
2.3 DataFrame常用操作
2.3.1 DSL风格语法
查看DataFrame中的内容
personDF.show
查看DataFrame部分列中的内容
personDF.select(personDF.col("name")).show
personDF.select(col("name"),col("age")).show
personDF.select("name").show
打印DataFrame的Scheme信息
personDF.printSchema
查询所有的name和age,并将age+1
personDF.select(col("id"),col("name"),col("age")+1).show
personDF.select(personDF("id"), personDF("name"), personDF("age")+1).show
过滤age大于等于18的
personDF.filter(col("age") >= 18 ).show
按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show
2.3.2 SQL风格语法
如果想使用SQL风格的语法,需要将DataFrame注册成表
personDF.createOrReplaceTempView("t_person") //spark2.x以上写法 personDF.registerTempTable("t_person") //spark1.6以下写法
查询年龄最大的前两名
sqlContext.sql("select * from t_person order by age desc limit 2").show
显示表的Schema信息
sqlContext.sql("desc t_person").show
3. DataSet
3.1 什么是DataSet
DataSet是从Spark 1.6开始引入的一个新的抽象。DataSet是特定域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作。每个DataSet都有一个称为DataFrame的非类型化的视图,这个视图是行的数据集。为了有效地支持特定域对象,DataSet引入了Encoder(编码器)。例如,给出一个Person的类,有两个字段:name(string)和age(int),通过一个encoder来告诉spark在运行的时候产生代码把Person对象转换成一个二进制结构。这种二进制结构通常有更低的内存占用,以及优化的数据处理效率(例如在一个柱状格式)。若要了解数据的内部二进制表示,请使用schema(表结构)函数。
在DataSet上的操作,分为transformations和actions。transformations会产生新的DataSet,而actions则是触发计算并产生结果。transformations包括:map,filter,select和aggregate等操作。而actions包括:count,show或把数据写入到文件系统中。
RDD也是可以并行化的操作,DataSet和RDD主要的区别是:DataSet是特定域的对象集合;然而RDD是任何对象的集合。DataSet的API总是强类型的;而且可以利用这些模式进行优化,然而RDD却不行。
DataFrame是特殊的DataSet,它在编译时不会对模式进行检测。
3.2 创建DataSet
1) 直接通过Seq创建
case class Data(a: Int, b: String) val ds = Seq(Data(1, "one"), Data(2, "two")).toDS() ds.collect() ds.show()
2) 通过sqlContext创建
case class Person(name: String, zip: Long) val df = sqlContext.read.json(sc.parallelize("""{"zip": 94709, "name": "Michael"}""" :: Nil)) df.as[Person].collect() df.as[Person].show()
3.3 DataSet使用示例
1) DataSet的WordCount
import org.apache.spark.sql.functions._ #创建DataSet val ds = sqlContext.read.text("hdfs://node-1.itcast.cn:9000/wc").as[String] val result = ds.flatMap(_.split(" ")) .filter(_ != "") .toDF() .groupBy($"value") .agg(count("*") as "numOccurances") .orderBy($"numOccurances" desc) .show() val wordCount = ds.flatMap(_.split(" ")).filter(_ != "").groupBy(_.toLowerCase()).count().show()
2) 对hdfs上的json文件进行分析
样例schools.json:
{"name": "UC Berkeley", "yearFounded": 1868, "numStudents": 37581}
{"name": "MIT", "yearFounded": 1860, "numStudents": 11318}
把schools.json上传到hdfs上:
hdfs dfs -put schools.json /
编写代码:
#定义case class case class University(name: String, numStudents: Long, yearFounded: Long) #创建DataSet val schools = sqlContext.read.json("hdfs://hadoop1:9000/schools.json").as[University] #操作DataSet schools.map(sc => s"${sc.name} is ${2015 - sc.yearFounded} years old").show
3) 对person.json进行分析
把json转DataFrame
#JSON -> DataFrame
val df = sqlContext.read.json("hdfs://hadoop1:9000/person.json")
使用DataFrame操作
df.where($"age" >= 20).show df.where(col("age") >= 20).show df.printSchema
DataFrame转DataSet
#DataFrame -> Dataset case class Person(age: Long, name: String) val ds = df.as[Person] ds.filter(_.age >= 20).show
DataSet转DataFrame
# Dataset -> DataFrame
val df2 = ds.toDF
DataFrame和DataSet操作对比
import org.apache.spark.sql.types._ df.where($"age" > 0) .groupBy((($"age" / 10) cast IntegerType) * 10 as "decade") .agg(count("*")) .orderBy($"decade") .show ds.filter(_.age > 0) .groupBy(p => (p.age / 10) * 10) .agg(count("name")) .toDF() .withColumnRenamed("value", "decade") .orderBy("decade") .show
4) 对student.json进行分析
把json转DataFrame
val df = sqlContext.read.json("hdfs://hadoop1:9000/student.json")
DataFrame转DataSet
case class Student(name: String, age: Long, major: String) val studentDS = df.as[Student] studentDS.select($"name".as[String], $"age".as[Long]).filter(_._2 > 19).collect()
DataSet根据major分组求和
studentDS.groupBy(_.major).count().collect()
DataSet根据major分组聚合
import org.apache.spark.sql.functions._ studentDS.groupBy(_.major).agg(avg($"age").as[Double]).collect()
创建Major的分类
case class Major(shortName: String, fullName: String) val majors = Seq(Major("CS", "Computer Science"), Major("Math", "Mathematics")).toDS()
把studentDS和majors求join
val joined = studentDS.joinWith(majors, $"major" === $"shortName") joined.map(s => (s._1.name, s._2.fullName)).show() joined.explain()
4. 以编程方式执行Spark SQL查询
4.1 编写Spark SQL查询程序
前面我们学习了如何在Spark Shell中使用SQL完成查询,现在我们来实现在自定义的程序中编写Spark SQL查询程序。首先在maven项目的pom.xml中添加Spark SQL的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
4.1.1 通过反射推断Schema
import org.apache.spark.sql.{SQLContext, SparkSession} import org.apache.spark.{SparkConf, SparkContext} /** * @author y15079 * @create 2018-03-11 14:23 * @desc **/ object SQLDemo { def main(args: Array[String]): Unit = { //本地运行 val conf = new SparkConf().setAppName("SQLDemo").setMaster("local[2]") //val conf = new SparkConf().setAppName("SQLDemo") 要打包到spark集群上运行则不需要后面的setMaster("local[2]") //SQLContext要依赖SparkContext val sc = new SparkContext(conf) //创建SQLContext spark1.6.1以下的写法 //val sqlContext = new SQLContext(sc) //spark2.0 以上的写法 val sqlContext = SparkSession.builder().config(conf).getOrCreate() //提交到spark集群上运行,需要设置用户,否则无权限执行,本地运行则无需 //System.setProperty("user.name", "bigdata") //集群hdfs路径 hdfs://node-1.itcast.cn:9000/person.txt //下面由于是本地运行,所以采用本地路径 //将RDD和case class关联 val personRdd = sc.textFile("D:\\IDEA\\HelloSpark\\src\\main\\files\\day4\\person.txt").map({line => val fields = line.split(",") Person(fields(0).toLong, fields(1), fields(2).toInt) }) //导入隐式转换,如果不导入无法将RDD转换成DataFrame //将RDD转换成DataFrame import sqlContext.implicits._ val personDf = personRdd.toDF() //采用SQL编写风格 注册表 //personDf.registerTempTable("person") spark 1.6.1以下的写法 personDf.createOrReplaceTempView("person") sqlContext.sql("select * from person where age >= 20 order by age desc limit 2").show() } } //case class一定要放到外面 case class Person(id:Long, name:String, age:Int)
4.1.2 通过StructType直接指定Schema
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.{Row, SQLContext, SparkSession} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} /** * @author y15079 * @create 2018-05-12 2:12 * @desc **/ object SQLSchemaDemo { def main(args: Array[String]): Unit = { //本地运行 val conf = new SparkConf().setAppName("SQLSchemaDemo").setMaster("local[2]") //val conf = new SparkConf().setAppName("SQLDemo") 要打包到spark集群上运行则不需要后面的setMaster("local[2]") //SQLContext要依赖SparkContext val sc = new SparkContext(conf) //创建SQLContext spark1.6.1以下的写法 //val sqlContext = new SQLContext(sc) //spark2.0 以上的写法 val sqlContext = SparkSession.builder().config(conf).getOrCreate() //提交到spark集群上运行,需要设置用户,否则无权限执行,本地运行则无需 //System.setProperty("user.name", "bigdata") //集群hdfs路径 hdfs://node-1.itcast.cn:9000/person.txt //下面由于是本地运行,所以采用本地路径 //从指定的地址创建RDD val personRDD = sc.textFile("D:\\IDEA\\HelloSpark\\src\\main\\files\\day4\\person.txt").map(_.split(",")) //通过StructType直接指定每个字段的schema val schema = StructType( List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) //将RDD映射到rowRDD val rowRDD = personRDD.map(p=>Row(p(0).toInt, p(1).trim, p(2).toInt)) //将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD, schema) //注册表 //personDataFrame.registerTempTable("person") spark 1.6.1以下的写法 personDataFrame.createOrReplaceTempView("person") //执行SQL val df = sqlContext.sql("select * from person where age >= 20 order by age desc limit 2").show() sc.stop() } }
5. 数据源
5.1 JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
5.1.1 从Mysql中加载数据库(Spark Shell 方式)
1) 启动Spark Shell,必须指定mysql连接驱动jar包
spark-shell --master spark://hadoop1:7077 --jars mysql-connector-java-5.1.35-bin.jar --driver-class-path mysql-connector-java-5.1.35-bin.jar
2) 从mysql中加载数据
val jdbcDF = sqlContext.read.format("jdbc").option(
Map("url"->"jdbc:mysql://hadoop1:3306/bigdata",
"driver"->"com.mysql.jdbc.Driver",
"dbtable"->"person",
"user"->"root",
"password"->"123456")
).load()
3) 执行查询
jdbcDF.show()
5.1.2 将数据写入到MySQL中(打jar包方式)
1) 编写Spark SQL程序
import java.util.Properties import org.apache.spark.sql.{Row, SQLContext, SparkSession} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.{SparkConf, SparkContext} /** * @author y15079 * @create 2018-05-12 2:50 * @desc **/ object JdbcDFDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("MysqlDemo").setMaster("local[2]") val sc = new SparkContext(conf) //创建SQLContext spark1.6.1以下的写法 //val sqlContext = new SQLContext(sc) //spark2.0 以上的写法 val sqlContext = SparkSession.builder().config(conf).getOrCreate() //通过并行化创建RDD val personRDD = sc.parallelize(Array("1 tom 5", "2 jerry 3", "3 kitty 6")).map(_.split(" ")) //通过StructType直接指定每个字段的schema val schema = StructType( List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) //将RDD映射到rowRDD val rowRDD = personRDD.map(p=>Row(p(0).toInt, p(1).trim, p(2).toInt)) //将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD, schema) //创建Properties存储数据库相关属性 val prop = new Properties() prop.put("user", "root") prop.put("password", "123456") //将数据追加到数据库 personDataFrame.write.mode("append").jdbc("jdbc:mysql://localhost:3306/bigdata","bigdata.person", prop) sc.stop() } }
2) 用maven-shade-plugin插件将程序打包
3) 将jar包提交到spark集群
spark-submit --class cn.itcast.spark.sql.jdbcDF --master spark://hadoop1:7077 --jars mysql-connector-java-5.1.35-bin.jar --driver-class-path mysql-connector-java-5.1.35-bin.jar /root/demo.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号