SolrCloud存储数据于HDFS的方法
1. 概述
solrCloud数据存储在hdfs上的方法有两种,一是配置solr.in.sh脚本文件,比较简单的一种方式;二是配置solrconfig.xml配置文件, 比较繁琐点,需要更新到zookeeper上。
说明:solrcloud部署是按照https://www.cnblogs.com/swordfall/p/11967385.html “Ranger安装部署 - solr安装”进行安装的,故本博文也是在此基础上进行hdfs相关配置的
2. 配置solr.in.sh文件
2.1. 索引数据存储在非HA的hdfs上
配置solr.in.sh文件,该文件位于/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/scripts,修改内容为:
$ vim solr.in.sh SOLR_OPTS="$SOLR_OPTS \ -Dsolr.directoryFactory=HdfsDirectoryFactory \ -Dsolr.lock.type=hdfs \ -Dsolr.hdfs.home=hdfs://bridge1:9000/solr"
解析:
- solr.directoryFactory=HdfsDirectoryFactory 为固定配置;
- solr.lock.type=hdfs 为固定配置;
- solr.hdfs.home=hdfs://bridge1:9000/solr 为指定solr的索引数据在hdfs上的路径。
2.2. 索引数据存储在HA的hdfs上
配置solr.in.sh文件,该文件位于/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/scripts,修改内容为:
$ vim solr.in.sh SOLR_OPTS="$SOLR_OPTS \ -Dsolr.directoryFactory=HdfsDirectoryFactory \ -Dsolr.lock.type=hdfs \ -Dsolr.hdfs.confdir=/opt/app/hadoop-2.7.5-ha-multi/etc/hadoop \ -Dsolr.hdfs.home=hdfs://bridge/solr"
解析:
- solr.hdfs.confdir=/opt/app/hadoop-2.7.5-ha-multi/etc/hadoop 为hdfs的ha配置路径;
- solr.hdfs.home=hdfs://bridge/solr 为指定solr的索引数据在hdfs上的路径, bridge为hdfs的ha名。
3. 配置solrconfig.xml文件
3.1. solrconfig.xml配置在非HA与HA的hdfs上
3.1.1. 索引数据存储在非HA的hdfs上
配置solrconfig.xml文件,修改配置文件内容如下:
<dataDir>${solr.data.dir:}</dataDir>
<directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory">
<str name="solr.hdfs.home">hdfs://bridge1:8020/solr</str>
<bool name="solr.hdfs.blockcache.enabled">true</bool>
<int name="solr.hdfs.blockcache.slab.count">1</int>
<bool name="solr.hdfs.blockcache.direct.memory.allocation">true</bool>
<int name="solr.hdfs.blockcache.blocksperbank">16384</int>
<bool name="solr.hdfs.blockcache.read.enabled">true</bool>
<bool name="solr.hdfs.blockcache.write.enabled">true</bool>
<bool name="solr.hdfs.nrtcachingdirectory.enable">true</bool>
<int name="solr.hdfs.nrtcachingdirectory.maxmergesizemb">16</int>
<int name="solr.hdfs.nrtcachingdirectory.maxcachedmb">192</int>
</directoryFactory>
<lockType>${solr.lock.type:hdfs}</lockType>
解析:
- ${solr.data.dir:} 为solr的索引数据存储的路径,一般为solr.hdfs.home的路径下面,如hdfs://bridge1:8020/solr/data,这种只适合集合的分片数量为1,即SHARDS,当分片为大于1的时候,将会报错,错误如下:
"192.168.1.11:6083_solr":"org.apache.solr.client.solrj.impl.HttpSolrClient$RemoteSolrException:
Error from server at http://192.168.1.11:6083/solr:
Error CREATEing SolrCore 'ranger_audits_shard1_replica_n1': Unable to create core [ranger_audits_shard1_replica_n1]
Caused by: /solr/data/index/write.lock for client 192.168.1.11 already exists\n\tat
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:2584)\n\tat
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2471)\n\tat
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2355)\n\tat
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:624)\n\tat
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:398)\n\tat
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)\n\tat
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)\n\tat
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)\n\tat
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)\n\tat
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)\n\tat
java.security.AccessController.doPrivileged(Native Method)\n\tat
javax.security.auth.Subject.doAs(Subject.java:422)\n\tat
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)\n\tat
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2213)\n"
为了解决上述错误,建议${solr.data.dir:}默认为空,不填。
- solr.hdfs.home为solr的存储目录
- solr.lock.type为solr的类型,指定为hdfs
3.1.2. 索引数据存储在HA的hdfs上
配置solrconfig.xml文件,修改配置文件内容如下:
<dataDir>${solr.data.dir:}</dataDir> <directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory"> <str name="solr.hdfs.home">hdfs://bridge1:8020/solr</str> <str name="solr.hdfs.confdir">/opt/app/hadoop-2.7.5-ha-multi/etc/hadoop</str> <bool name="solr.hdfs.blockcache.enabled">true</bool> <int name="solr.hdfs.blockcache.slab.count">1</int> <bool name="solr.hdfs.blockcache.direct.memory.allocation">true</bool> <int name="solr.hdfs.blockcache.blocksperbank">16384</int> <bool name="solr.hdfs.blockcache.read.enabled">true</bool> <bool name="solr.hdfs.blockcache.write.enabled">true</bool> <bool name="solr.hdfs.nrtcachingdirectory.enable">true</bool> <int name="solr.hdfs.nrtcachingdirectory.maxmergesizemb">16</int> <int name="solr.hdfs.nrtcachingdirectory.maxcachedmb">192</int> </directoryFactory> <lockType>${solr.lock.type:hdfs}</lockType>
解析:与非HA模式的配置的差别在于solr.hdfs.confdir
- solr.hdfs.confdir为指定hdfs的配置路径
3.2. solrconfig.xml文件更新到zookeeper上
solrconfig.xml在本地机器修改,对solr不生效,只有更新到zookeeper上面才生效。这里有个更新脚本add_ranger_audits_conf_to_zk.sh,脚本路径位于/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/scripts,如下:
function usage { echo "Error: The following properties need to be set in the script SOLR_ZK, SOLR_INSTALL_DIR and SOLR_RANGER_HOME" exit 1 } JAVA_HOME=/usr/lib/java/jdk1.8.0_151 SOLR_USER=solr SOLR_ZK=bridge1:2181,bridge2:2181,bridge3:2181/ranger_audits SOLR_INSTALL_DIR=/opt/app/ranger-solr-8.3.0-cloud SOLR_RANGER_HOME=/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server if [ "`whoami`" != "$SOLR_USER" ]; then if [ -w /etc/passwd ]; then echo "Running this script as $SOLR_USER..." su $SOLR_USER $0 else echo "ERROR: You need to run this script $0 as user $SOLR_USER. You are currently running it as `whoami`" fi exit 1 fi if [ "$SOLR_ZK" = "" ]; then usage fi if [ "$SOLR_INSTALL_DIR" = "" ]; then usage fi if [ "$SOLR_RANGER_HOME" = "" ]; then usage fi SOLR_RANGER_CONFIG_NAME=ranger_audits SOLR_RANGER_CONFIG_LOCAL_PATH=${SOLR_RANGER_HOME}/conf ZK_CLI=$SOLR_INSTALL_DIR/server/scripts/cloud-scripts/zkcli.sh if [ ! -x $ZK_CLI ]; then echo "Error: $ZK_CLI is not found or you don't have permission to execute it." exit 1 fi set -x $ZK_CLI -cmd upconfig -zkhost $SOLR_ZK -confname $SOLR_RANGER_CONFIG_NAME -confdir $SOLR_RANGER_CONFIG_LOCAL_PATH
解析:
- JAVA_HOME设置JAVA_HOME路径
- SOLR_USER solr用户
- SOLR_ZK solr关联的zookeeper
- SOLR_INSTALL_DIR solr安装目录
- SOLR_RANGER_HOME solr关于ranger的安装目录
- SOLR_RANGER_CONFIG_NAME solr的ranger集合名
- SOLR_RANGER_CONFIG_LOCAL_PATH solrconfig.xml配置文件的路径
- ZK_CLI zk_cli的路径
执行脚本:
$ pwd /opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/scripts $ ./add_ranger_audits_conf_to_zk.sh
3.3. solrconfig.xml文件是否更新成功检测
登录solr admin的网址,查看solrconfig.xml文件,如下,则成功更新solrconfig.xml文件。
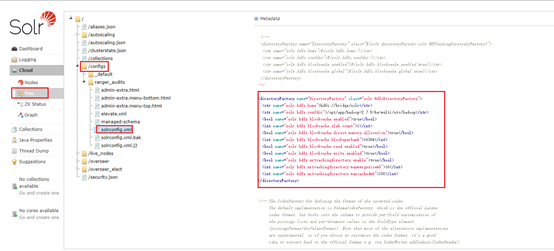
4. solr集合创建脚本
当配置好solr.in.sh脚本文件或者配置好solrconfig.xml文件,两者之一后,我们创建名为“ranger_audits”的集合。
create_ranger_audits_collection.sh,文件位于/opt/app/ranger-solr-8.3.0-cloud/ranger_audit_server/scripts,如下:
SOLR_HOST_URL=http://`hostname -f`:6083 SOLR_ZK=bridge1:2181,bridge2:2181,bridge3:2181/ranger_audits SOLR_INSTALL_DIR=/opt/app/ranger-solr-8.3.0-cloud SHARDS=2 REPLICATION=1 CONF_NAME=ranger_audits COLLECTION_NAME=ranger_audits which curl 2>&1 > /dev/null if [ $? -ne 0 ]; then echo "curl is not found. Please install it for creating the collection" exit 1 fi set -x curl --negotiate -u : "${SOLR_HOST_URL}/solr/admin/collections?action=CREATE&name=${COLLECTION_NAME}&numShards=${SHARDS}&replicationFactor=${REPLICATION}&collection.configName=$CONF_NAME&maxShardsPerNode=100"
这里建议:由于数据存储在hdfs上,hdfs已有副本机制。故solr的副本REPLICATION设置为1,避免冗余。
解析:
- SHARDS 分片根据部署的机器数量配置
5. solr集合索引数据是否存储在hdfs上
如下图展示,则表明集合的索引数据已存储在hdfs上。
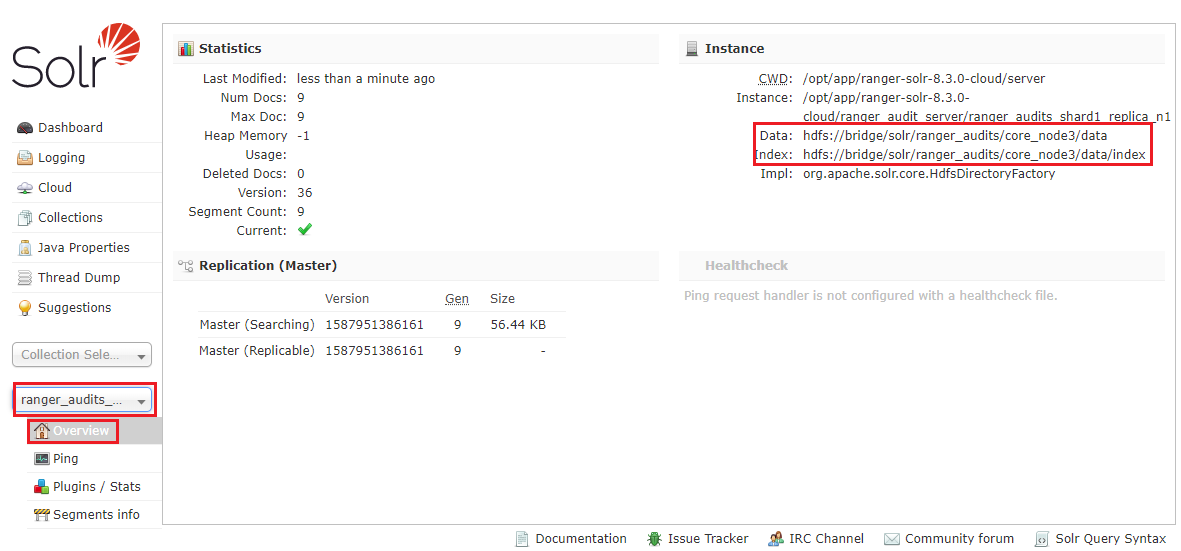
总结
【参考资料】
https://www.jianshu.com/p/026b5641786c Solr7.3 Cloud On HDFS搭建
https://lucene.apache.org/solr/guide/7_3/running-solr-on-hdfs.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号